 夜雨聆风
夜雨聆风





Matt Pocock:AI 时代代码并不廉价,软件工程基本功比以往更重要
核心主张:AI 编程工具被过度炒作,但也异常强大。决定成败的不是工具,而是流程;那些真正成功的开发者并没有把一切都推给 AI,而是回归了软件工程的基本功。
背景信息
说话人是谁:Matt Pocock,知名开发者与技术讲师。在过去 18 个月里,他一直致力于教开发者如何使用 AI 智能体 (AI Agent) 组成的“群体 (Swarms)”来构建高质量的应用程序,并开设了一门极具挑衅意味的课程——《写给真正工程师的 Claude Code》。
这次讲了什么:他探讨了在使用 AI 编程工具时常见的 5 种“翻车”场景,并指出在这个新时代,测试驱动开发、领域驱动设计和深模块等有着几十年历史的软件工程基本功,不仅没有失效,反而比以往任何时候都更加致命和重要。

1. “写出文档让 AI 生成代码”的迷思与软件熵
在准备 AI 编程课程的过程中,我非常头疼,因为这个领域的变化实在太快了。AI 似乎带来了一种全新的范式,很多人觉得我们肯定需要抛弃所有旧规则,去迎接新东西。

1.1. “规格到代码”模式的破产
围绕这种想法,出现了一个叫做“规格到代码 (Specs to code)”的运动。它的核心理念是:你只需要写一份说明文档(规格),描述应用程序该怎么运行,然后用 AI 把它变成代码。如果程序出了问题,你不需要去看代码,只要回去修改那份说明文档,再次运行“编译器(AI)”,就能得出新的代码。

我自己也试过。我尽量忍住不去看代码,但最后还是忍不住看了。我发现,我第一次跑出来一些代码,运行之后发现不行;修改说明后再跑一次,代码变得更糟了;再跑一次,更加糟糕。我就这样一遍遍地运行,最后得到了一堆垃圾。

我认为这种方法根本行不通。那种认为我们可以忽略代码、让代码自我管理的想法,其实只是换了层皮的氛围式编程 (Vibe Coding)。
1.2. 坏代码变得前所未有地昂贵
我开始思考,怎么才能修复这个“编译器”?怎么才能让它每次不产生更糟的代码?我觉得我需要用英语向大语言模型 (Large Language Model, LLM) 解释清楚“好的代码库”到底长什么样。

我翻出了我最爱的老书之一,John Ousterhout 写的《软件设计的哲学》(A Philosophy of Software Design)(去亚马逊上买本看看)。他对坏代码的定义是“复杂的代码”——任何让软件系统的结构变得难以理解和修改的东西,就是复杂性。如果一个代码库你一改就出 Bug,那它就是个坏的代码库;好的代码库是容易修改的。

接着我又翻了另一本书,《程序员修炼之道》(The Pragmatic Programmer)。里面有一整章在讲“软件熵 (Software Entropy)”。

这正是我遇到的情况:熵的概念就是事物总是倾向于走向灾难、分崩离析和坍塌。当你每次修改代码时,如果你只盯着眼前的修改,而不去思考整个系统的设计,你的代码库就会变得越来越糟。在“规格到代码”的理念里,你一遍遍地重新生成代码,其实就是在制造越来越糟的代码。
在这个运动背后,有一个核心观 点是“代码是廉价的”。

我不认为代码是廉价的。事实上,坏代码现在是前所未有地昂贵。因为如果你的代码库很难修改,你就无 法享受 AI 带来的巨大红利——在好的代码库里,AI 的表现其实极其出色。


这也意味着,好的代码库比以往任何时候都重要,软件工程的基本功比以往任何时候都重要。

2. 避免 AI 翻车的五个实操指南
接下来,让我们聊点实际的。下面这些都是你在用 AI 时可能遇到(或即将遇到)的翻车模式,以及我们如何通过回归经典软件实践来避免它们。
2.1. 翻车模式一:AI 做的根本不是我想要的
你明明觉得脑子里有个好主意,但 AI 做出来的东西却完全是另一码事。

《程序员修炼之道》里提到过,其实没有谁能真正确切地知道自己想要什么。你和 AI 之间存在沟通壁垒。当你和 AI 交流时,其实就像是 AI 在做需求收集,它试图从你那里弄清楚你到底需要什么。

Frederick P. Brooks 在《设计的物理学》(The Design of Design) 中提出了“设计概念 (Design Concept)”的想法。当几个人一起设计东西时,你们之间会漂浮着一个稍纵即逝的“关于正在构建的东西的想法”。这个设计概念不是一个实体资产,不是一个你可以塞进 Markdown 文件的东西,它是关于你们在构建什么的“无形理论”。

我和 AI 之间显然没有共享这个设计概念。因此,我写了一个非常简单的提示词技能,叫做“拷问我 (Grill Me, 技能/grill-me)”:
“无情地拷问我关于这个计划的每一个细节,直到我们达成共识。沿着设计树的每一个分支走下去,逐一解决决策之间的依赖关系。”
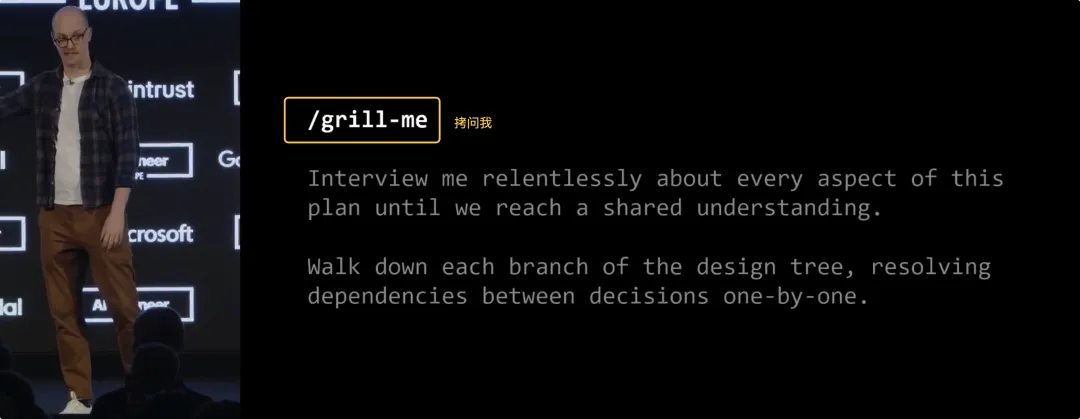
这个包含几行词的仓库在 GitHub 上大概拿了 13000 个 Star,简直疯传,大家都爱死它了。这几句话会让 AI 向你抛出大概 40 个、60 个问题,我甚至见过它在确认双方达成共识前问了别人 100 个问题。它把 AI 变成了一个“对手”,不断向你抛出想法来碰撞。
当你们完成这段对话后,你可以把生成的内容直接变成产品需求文档 (Product Requirements Document, PRD),或者如果是小修改,直接转化成 Issue 丢给挂机运行的 AI 智能体去处理。


别在这件事上杠我(Don’t at me),但我个人认为这比我在用的工具(Claude Code)默认的“计划模式”要好得多。默认模式总是太急于生成一个实体文件,急着开始干活;而我认为,先达成共享的设计概念要好得多。


2.2. 翻车模式二:AI 废话太多,跟你不在一个频道
有时候 AI 会用极其冗长的废话来解释它在干嘛,感觉你们俩根本没有在使用同一种语言。

如果你是一个资深开发者,想象一下你和一个非技术领域的业务专家合作。比如对方让你开发一个微芯片相关的应用,但你对微芯片一无所知。如果你不建立某种共享语言,他们就会用你听不懂的术语,你再把它们翻译成连你自己(甚至专家)都看不懂的代码。

这让我回到了领域驱动设计 (Domain-Driven Design, DDD)。我现在简直爱死 DDD 了。DDD 里有一个核心概念叫做“统一语言 (Ubiquitous Language)”:开发者之间的对话、代码的表达、以及与业务专家的对话,都必须基于同一个领域模型。

于是我做了一个“统一语言”技能。它基本上就是扫描你的代码库,寻找专业术语,然后生成一个 Markdown 文件,里面是用表格列出的所有术语和定义。我把这个文件发给 AI,我自己也看。在我和 AI 进行“拷问”规划时,我总是一直开着这个文件。

通过阅读 AI 的思维痕迹我发现,这不仅改善了规划过程,还能让 AI 的思考方式变得不那么啰嗦,并且能确保最终的实现效果与你最初的计划高度一致。

2.3. 翻车模式三:AI 构建了对的东西,但跑不通
如果你们对齐了需求,AI 也做了该做的事,但代码就是跑不通怎么办?

显而易见的解决办法是引入反馈循环:

但我发现,即使有了这些反馈循环,LLM 用得也不怎么好。它不像老练的开发者那样能充分利用反馈。它倾向于一次性干太多事:一口气吐出海量代码,然后才想起来,“哦,我可能该做个类型检查,或者跑个测试”。
《程序员修炼之道》把这种行为形容为“超出车头灯的照射范围(开得太快)”——因为你获得反馈的速率,就是你的限速标志。你应该边写边测试,迈出极其谨慎的小步子。
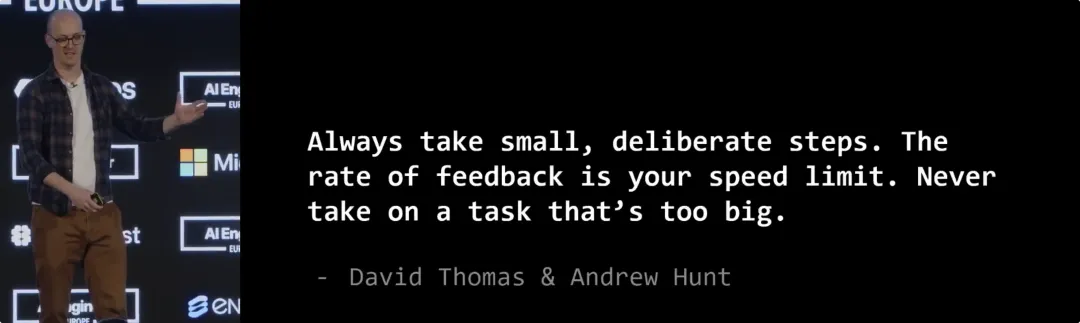
默认情况下的 AI 非常不擅长这个。所以我们的第三个技巧是测试驱动开发 (Test-Driven Development, TDD)。TDD 会强迫 LLM 迈小步:先写一个测试,让测试通过,然后再重构代码优化设计。

2.4. 翻车模式四:代码库太乱,AI 无法理解
实行 TDD 的难点在于,写测试本身就很难。写测试时你需要做一堆相互依赖的决定:测试的单元要多大?需要 Mock(模拟)什么?一开始到底要测试什么行为?如果你测试一个超级庞大的应用,它可能会很不稳定。

回顾我的整个开发生涯,我发现:好的代码库,就是容易测试的代码库。这又回到了“代码很重要”的观点。代码库越好,你的反馈循环就越好;你能给 LLM 提供更好的反馈,它就能写出更好的代码。

一个容易测试的代码库长什么样?再次请出 John Ousterhout。他提倡在代码库中使用“深模块 (Deep Modules)”,而不是浅模块 (Shallow Modules)。你应该用相对较少的深模块,配上简单的接口。

深模块:简单的接口背后隐藏了大量的功能和复杂性。你如果愿意,可以深入模块内部查看,但完全没必要,你只用它的接口就行。
浅模块:接口很复杂,但里面没多少实质功能。

现在很多代码库里充斥着浅模块,就像一堆微小的代码斑块。AI 非常“擅长”制造这种代码。当 AI 面对这种代码库时,它很难去探索和导航。

它试图理解代码,但因为布局糟糕、充满了浅模块,它可能无法及时找到正确的模块,或者理不清依赖关系,最终导致它根本看不懂你的代码。

而在深模块组成的代码库中,同样的代码被很好地圈在边界内。你应该紧紧把控并精心设计最上层的接口(防止 AI 把设计搞砸),但至于模块内部的实现,你可以放心地交给 AI。
我为此写了一个“改善代码库架构”的技能。虽然过程有点复杂,但套路是可重复的:让 AI 探索代码库,寻找相关联的代码,然后把它们全包进一个深模块里。这样代码的边界变得极其简单,你只需要在这个接口层面进行验证测试就可以了。

2.5. 翻车模式五:代码产出猛增,但你的大脑跟不上了

假设你的反馈循环转起来了,你交付代码的速度前所未有地快,但你是不是感觉比职业生涯中的任何时候都要累?因为你不仅要让 AI 干活,你自己还得把所有的信息都装在脑子里。
深模块同样能解决这个问题,因为它能拯救你的大脑。你可以把这些深模块当成“灰盒 (Gray Boxes)”。

你可以对自己说:“我只负责设计接口,不去过度操心(或审查)内部的实现。”当然,对于金融这类核心关键业务你不能这么搞;但在应用的大多数普通模块里,只要外部有可测试的边界,并且你清楚它的目标并能从外部设计它,内部实现完全可以扔给 AI(那个大黑块)去处理。


3. 每天都要投资系统设计
上面提到的这些方法意味着,我们每次接触代码、规划功能时,都必须清醒地意识到应用中各个模块的存在。我们需要对这幅“架构地图”了如指掌,让它成为我们“统一语言”的一部分,并融入我们的规划技能中。
现在我在写 PRD 时,会非常具体地指出哪些模块需要修改、模块内的接口要怎么改。我无时无刻不在思考这些设计。
正如 Kent Beck 所说:“每天都要投资系统设计。”

这才是核心所在。“规格到代码”的做法,实际上是在放弃对系统设计的投资。而我认为,投资系统设计才是通向成功的绝对关键。
代码绝不是廉价的,代码非常重要。如果我们把 AI 看作是一个出色的前线战术程序员(一个在泥地里摸爬滚打修改代码的中士),那么它的上方必须有一个人站在战略高度进行思考。那个人就是你。而要做好这个战略指挥官,依靠的正是我们使用了 20 年甚至更久的软件工程基本功。
