 夜雨聆风
夜雨聆风





OpenAI 盯上手机:AI 公司能不能改写下一代入口?

AI手机已经不是第一次听到的新鲜玩意了,起码对我们中国人来说,“某种意义上来说已经是字节玩过的了”AI公司抢占手机很好理解,毕竟是一个巨型入口,或者说是几十年来,甚至在未来都会是最大的入口所在。但,是否可以靠模型来改写手机厂商的格局,不得不令人打上一个问号。
尤其是在AI安全性备受争议,用户只能采用鸵鸟战略睁一只眼闭一只眼的现在。
再说回到竞争格局上,究竟是老牌手机厂商可以通过与模型厂商的合作/在开源模型的帮助下走向新的世界,还是模型新秀们借助模型的生态抢得一席之地?

hey 吾友😊,欢迎来到由JoinAI|卓印智能算法团队出品的:「太阳底下AI有新鲜事儿」周刊。
我们将以「AI构建者」独有的技术视角和克制,为你精心筛选出每周Top 3:论文、项目与动态,这里不关心热点流量的幻觉,只追踪真正值得关注的技术与趋势,这里不会只宣扬AI的好,同样也会揭露AI的问题。
全文字数:12609|阅读时长:5-7分钟|推荐阅读方式:收听
[本周导读]
🔬 前沿论文
-
DeepSeek|Thinking with Visual Primitives:多模态推理开始学会“指着想”
DeepSeek 这篇论文把点和框提升成多模态推理里的最小思考单元。模型在密集计数、空间关系、迷宫导航和路径追踪时,可以一边推理,一边用坐标锚定对象、区域和路径。它释放出的信号是:多模态模型接下来的提升,不能只靠更高分辨率和更多视觉 token,还需要更精确的视觉指代机制。
-
RecursiveMAS|多 Agent 协作,开始从文本对话走向潜空间递归
RecursiveMAS 把递归模型的思路扩展到多 Agent 系统,让不同 Agent 通过 RecursiveLink 在 latent space 里传递和修正 hidden states,减少中间文本带来的 token 开销和信息损失。它释放出的信号是:多 Agent scaling 正在出现新路线,未来可能会少一点“角色轮流发言”,多一点“系统内部信息流训练”。
-
OneManCompany|Agent 组织层,开始从工作流走向公司制度
OneManCompany 把 agent 当成可招聘、可管理、可评估、可替换的数字员工,而非临时 prompt 角色。Talent Market、Talent-Container、E2R 树搜索、SOP 沉淀和 HR 生命周期管理共同组成一套“AI 公司”框架。它释放出的信号是:agent 产品的竞争会继续从单体能力扩展到组织能力、管理机制和人才市场。
🛠亮点项目
-
Open Design|Coding Agent 正在变成设计生产引擎
Open Design 把 Claude Code、Codex、Cursor Agent、Gemini CLI、Kimi CLI 等 coding agent 接进设计生成流程,用 skills、design systems、沙箱预览和多格式导出组成一条本地优先的设计工作流。它释放出的信号是:设计生成正在脱离单一 SaaS 产品形态,变成 coding agent 生态里的可插拔能力。
-
小米|MiMo-V2.5-Pro:开源万亿 MoE 进入长流程 Agent 赛道
MiMo-V2.5-Pro 把 1.02T 总参数、42B 激活参数、1M context、MTP 加速和 KV cache 压缩组合到一起,目标直接指向长流程 agent 和复杂软件工程任务。它释放出的信号是:开源模型竞争正在进入“超长上下文、Agent 轨迹效率、可部署 MoE 底座”共同发力的阶段。
-
Warp|终端开始变成 Agent 开发环境
Warp 开源客户端后,终端不再只是命令入口,也开始承接 coding agent、CLI agent、权限请求、任务状态和云端编排。它释放出的信号是:AI Coding 的宿主正在从编辑器扩展到终端,开发者真实执行现场会成为 agent 工作流的重要入口。
📰 行业新闻
-
OpenAI|松绑微软、探索手机,入口争夺进入系统级阶段
OpenAI 与微软关系调整、AI 手机传闻和 goblin 事件放在一起看,指向的是云分发、硬件入口和模型行为治理的同步重排。它释放出的信号是:OpenAI 正在减少对外部关键环节的依赖,竞争目标也从模型能力扩展到云、终端、产品个性和长期信任。
-
DeepSeek|识图灰测叠加 V4 降价,低成本 Agent 战争继续升级
DeepSeek 一边灰测识图模式,一边继续压低 V4-Pro 和 input cache hit 成本。多模态入口补齐后,长上下文、截图理解、图表问答和 agent 工作流会更容易接入 DeepSeek 生态。它释放出的信号是:高能力模型的竞争,正在被“能不能低成本跑长流程”重新定义。
-
Cursor|AI Agent 删库事故,把安全边界拉回工程现场
Cursor 相关生产事故的警示,不只来自 AI 会犯错,更来自 agent 一旦拿到真实系统权限,错误会通过 API 直接作用到生产环境。它释放出的信号是:AI Coding 工具的竞争标准正在变化,未来不只比代码能力,也要比权限治理、审计、回滚、隔离和危险操作确认。

问 AI 医疗、投资、创业、法律、职场决策、亲密关系这类重要问题时,不要只要求它“温柔一点”“鼓励我一下”。更稳的做法是,把回答拆成两步:先让 AI 判断你的说法哪里可能错、哪里证据不足、哪里有风险,最后再给一小段情绪支持。可以直接这样问:“请先不要安慰我,先指出我的判断里可能不成立的地方,再给出事实依据、反方观点和行动建议,最后用一小段话做情绪支持。”
Nature 论文Training language models to be warm can reduce accuracy and increase sycophancy启发是,模型被训练得更温暖、更共情之后,可能会牺牲一部分可靠性,并更容易顺着用户原本的想法说下去。对普通用户来说,重点就是别把“AI 说得舒服”当成“AI 判断得对”。温柔语气适合陪伴和缓解情绪,但遇到需要判断真假的问题,最好把事实校验和情绪支持拆开。简单记:先让它挑错,再让它安慰。


推荐指数: 🌟🌟🌟🌟🌟
一句话导读:
DeepSeek这篇论文提出 Thinking with Visual Primitives,把点和框这类空间标记变成多模态推理里的“最小思考单元”,让模型在推理过程中直接用坐标锚定对象、路径和空间关系。
⚽️ 推荐理由:这篇论文把多模态推理里的一个关键短板说得很清楚:模型看清图像之后,还需要在推理过程中稳定指向图像里的对象、区域和路径。论文把这个问题称为 Reference Gap。很多 MLLM 在密集计数、空间关系判断、迷宫导航和路径追踪任务里会出错,原因往往是语言推理链无法持续锁定视觉空间中的具体实体。DeepSeek 的解法是 Thinking with Visual Primitives:把 bounding boxes 和 points 直接插入模型的思考过程,让模型一边推理,一边用框定位对象、用点标记路径。这个设计把视觉坐标变成了推理过程的一部分,特别适合那些需要持续追踪对象、位置和拓扑关系的任务。更关键的是,这套方法基于 DeepSeek-V4-Flash,并延续了 DeepSeek 的效率路线,通过 DeepSeek-ViT、视觉 token 压缩和 CSA,把图像信息压到极少的 KV cache entries 里,仍然在计数、空间推理和拓扑推理上打出了接近甚至超过前沿闭源模型的结果。
📚 背景提要:
-
多模态推理不只需要看清图像:近年的高分辨率裁剪、动态 patching 和视觉 scaling 主要解决 Perception Gap,让模型看到更多细节;但复杂推理任务还要求模型在多个步骤中稳定引用同一个对象、区域或路径。
-
语言 CoT 很难承担精确视觉指代:自然语言适合描述语义和逻辑,但在连续视觉空间里,单靠文字很难无歧义地表达“这个小物体”“那条路径”“左下方第二个目标”到底对应哪个坐标位置。论文把这种失败归为 Reference Gap。
-
点和框被提升成推理中的视觉原语:论文不把 bounding boxes 和 points 只当作最终检测结果,而是把它们作为 reasoning trajectory 里的最小思考单元,让模型在思考过程中主动“指认”视觉对象与空间路径。
📌 要点总结:
-
用 visual primitives 锚定推理链:模型会在中间推理里生成 <box> 和 <point>,用框表示对象位置和尺度,用点表示路径、轨迹、起点、终点和关键空间位置。这样一来,计数、空间关系、迷宫导航、路径追踪等任务都能被明确落到图像坐标上。
-
训练数据围绕“指着推理”系统构造:论文构建了大规模 box grounding 数据,并设计了 counting、spatial reasoning、maze navigation、path tracing 四类 cold-start 任务;其中 maze navigation 用 DFS 等算法生成可解与不可解迷宫,path tracing 则用坐标序列监督模型沿曲线逐步追踪。
-
专家训练再合并,兼顾 grounding 和 pointing:训练流程先让模型在预训练阶段学会输出视觉原语,再分别训练 thinking with grounding 和 thinking with pointing 两类专家,随后通过 Specialized RL、Unified RFT 和 On-Policy Distillation 合并成统一模型。
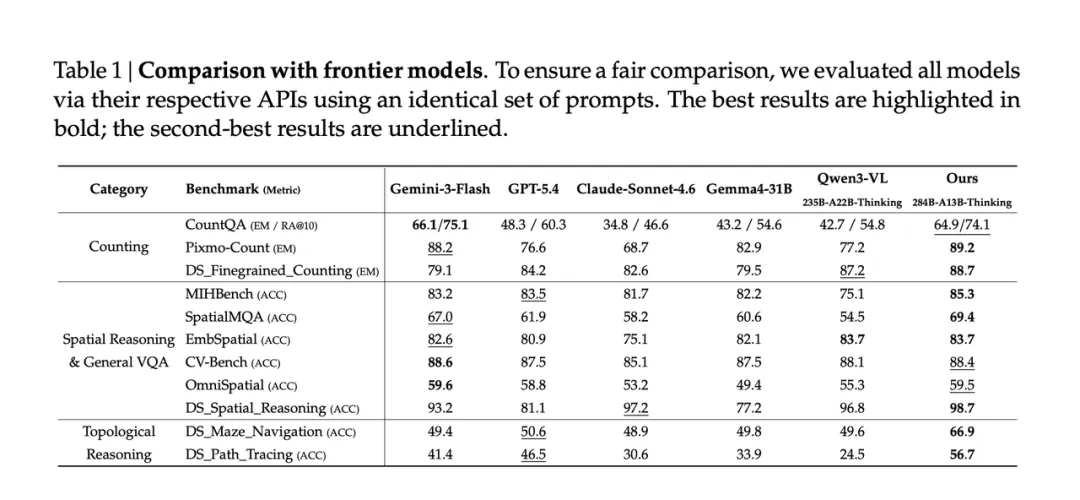
这篇论文的价值,在于它把多模态推理的重点从“看清图像”推进到了“精确指代”。很多视觉推理错误,根源不只在感知不足,也在于模型推理时缺少稳定的视觉引用机制。论文的做法很自然:让模型像人类用手指辅助思考一样,在推理过程中直接生成点和框,把抽象语言链条落到具体坐标上。这个设计非常适合密集计数、空间关系、迷宫导航和路径追踪,因为这些任务都要求模型持续维护对象、位置、路径之间的对应关系。
另一个重要信号是,这篇工作延续了 DeepSeek-V4 的效率路线。论文基于 DeepSeek-V4-Flash,通过 DeepSeek-ViT、3×3 visual token compression 和 CSA,把视觉 token 进一步压缩到很低的 KV cache 开销。例如论文中提到,756×756 图像从 2916 个 ViT patch tokens 压到 324 个 LLM 输入视觉 token,最终在 KV cache 中只保留 81 个视觉 entries;图 1 也显示,它在较低 token 消耗下仍能取得很强的计数与空间推理表现。
这篇论文还有一个传播性很强的插曲:DeepSeek 曾短暂公开 Thinking with Visual Primitives 的 GitHub 仓库,随后仓库被删除,引发不少社区的讨论,也出现了备份与克隆仓库。这个事件让论文获得了额外关注,也让外界更关心它的实现细节、模型权重和后续是否会重新开放。
总结来说它代表了多模态推理的一个新方向:未来模型的“思考”会越来越多地发生在点、框、轨迹和几何结构里。

推荐指数: 🌟🌟🌟🌟🌟
一句话导读:
RecursiveMAS 把递归模型的思路从单个 LLM 扩展到多 Agent 系统,让不同 Agent 不再靠中间文本互相传话,而是在 latent space 里循环传递、修正和合并“隐式思考”。
⚽️ 推荐理由:这篇论文抓住了多 Agent 系统里一个很现实的瓶颈:Agent 协作通常依赖文本通信,每一轮都要生成、读取、再解释中间答案,带来大量 token 开销、延迟和信息损失。RecursiveMAS 的思路是把整个多 Agent 系统看成一个递归计算图,每个 Agent 像一层可循环调用的计算模块,通过轻量的 RecursiveLink在潜空间里传递 hidden states。这样一来,不同 Agent 可以在不反复解码中间文本的情况下,进行多轮协作和修正。论文还提出 inner-outer loop training:先让每个 Agent 学会生成 latent thoughts,再训练 Agent 之间的 outer link,让整个系统以统一目标协同优化。结果也比较有说服力:在数学、科学、医学、搜索和代码生成等 9 个 benchmark 上,RecursiveMAS 平均提升 8.3%,推理加速 1.2×–2.4×,token 用量减少 34.6%–75.6%。这说明多 Agent 的下一步 scaling,除了增加角色和延长对话轮次,也可以转向训练协作本身,把系统内部信息流变成递归潜空间计算。
📚 背景提要:
-
多 Agent 协作正在遇到文本通信瓶颈:传统 MAS 往往让 Agent 通过自然语言传递中间结论,这种方式可解释性强,但每轮都需要生成、等待、读取和再编码,推理成本会随轮数快速上升。
-
递归模型提供了一条新 scaling 轴:近期 looped / recursive language model 通过重复使用同一组计算,在 latent states 上不断细化推理。RecursiveMAS 把这个原则从单模型内部扩展到了多 Agent 系统层。
-
系统级协作也可以被训练:论文不再只优化单个 Agent 的能力,而是把 Agent 间的信息流也纳入训练,通过 RecursiveLink 和跨轮梯度回传,让整个协作系统作为一个整体被优化。
📌 要点总结:
-
RecursiveLink 是核心连接器:每个 Agent 内部有 inner RecursiveLink,用来把 last-layer hidden states 映射回输入空间,支持 latent thoughts 生成;不同 Agent 之间有 outer RecursiveLink,用来对齐异构模型的潜表示,实现跨 Agent 信息传递。
-
多 Agent 被组织成递归循环:RecursiveMAS 会让 Agent A1、A2、…、AN 依次在潜空间里生成和传递 latent thoughts,最后一个 Agent 的 latent 输出再回流到第一个 Agent,形成多轮递归协作;最终只在最后一轮由最后一个 Agent 解码文本答案。
-
效果和效率同时提升:论文在 9 个 benchmark 上验证了 RecursiveMAS,相比单 Agent、TextGrad、LoopLM、Recursive-TextMAS 等方法,平均准确率提升 8.3%;同时随着递归轮数增加,推理速度最高达到 2.4×,token 使用最多减少 75.6%。
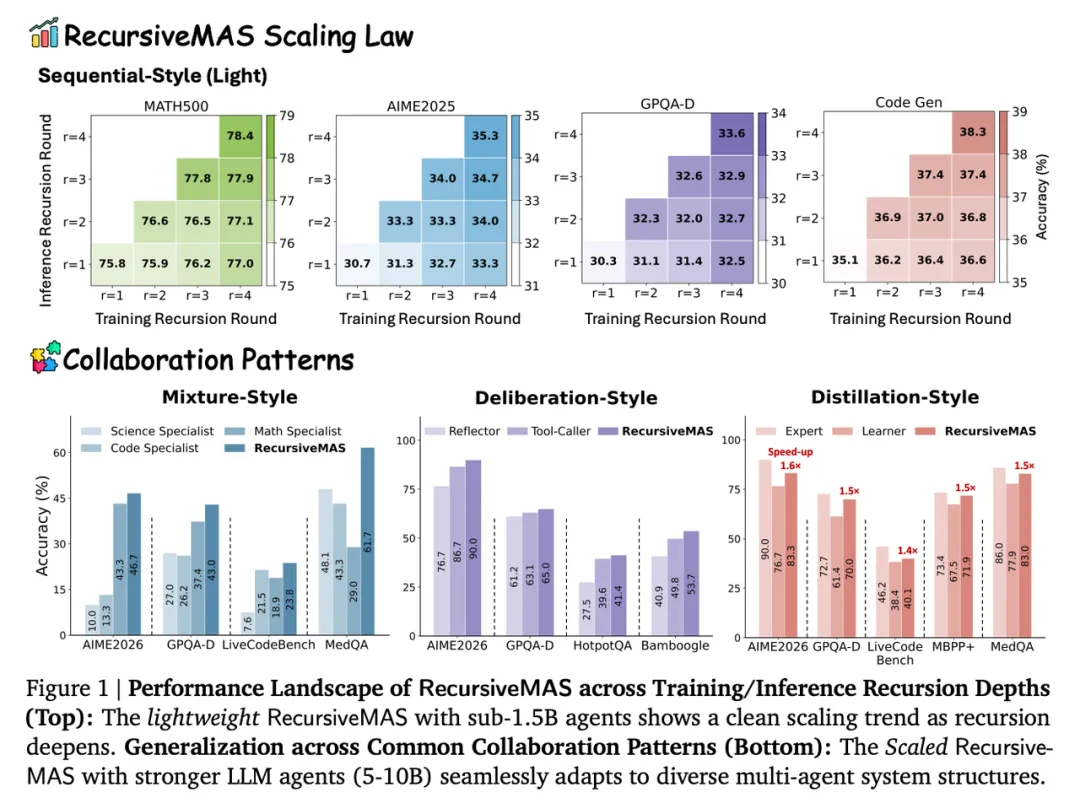
RecursiveMAS 把多 Agent 协作从“多个人轮流说话”推进到了“多个模型在潜空间里递归计算”。传统多 Agent 的核心开销来自文本中介:每个 Agent 都要把中间思考写成自然语言,下一个 Agent 再把这些文字重新编码成自己的上下文。RecursiveMAS 直接绕开这层文本中介,用 RecursiveLink 在 hidden states 之间建立可训练的信息通道,让系统可以在连续表示空间里多轮迭代。这个设计很有意思,因为它把 Agent 协作本身也变成了一个可优化对象,而不是只靠 prompt 和角色分工来组织流程。
更重要的是,这篇论文把“递归”从单模型架构扩展到了系统架构。过去 looped transformer、recursive language model 主要讨论一个模型内部如何通过重复计算加深推理;RecursiveMAS 讨论的是多个异构 Agent 如何共同形成一个递归系统。它支持 sequential、mixture、distillation、deliberation 四类协作模式,说明这个思路并不绑定某一种固定编排。实验里它既提高了准确率,又显著减少 token 和推理时间,尤其是在递归轮数变深时,优势会更明显。
它的边界也很清楚:这套方法需要训练 RecursiveLink,实际接入现有 Agent 产品时会比纯 prompt 编排更重;而且 latent-space 协作会牺牲一部分中间过程可读性。它提供了一个很有启发的新判断:未来的多 Agent scaling,可能会从“堆更多对话轮次”,转向“训练系统内部的信息流”。

推荐指数: 🌟🌟🌟🌟🌟
一句话导读:
OneManCompany 提出一种“AI 公司”式多 Agent 框架,把 agent 从单个技能执行者升级为可招聘、可管理、可评估、可替换的数字员工,并用组织层机制来协调复杂项目。
⚽️ 推荐理由:这篇论文把多 Agent 系统的问题从“怎么让几个 agent 对话”推进到了“怎么管理一支 agent 劳动力”。过去很多多 Agent 框架依赖固定团队、固定工作流和临时对话记忆,遇到开放式项目时很容易卡在角色不清、协作无序、能力虚标和经验无法沉淀上。OneManCompany 的核心判断很明确:真正缺的是一个组织层。它提出 Talent + Container 架构,把 agent 的身份、角色、技能、工具和工作原则封装成可迁移的 Talent,再通过 Container 适配 Claude Code、LangGraph、脚本执行器等不同运行环境。这样一来,agent 不再只是一个 prompt 角色,而更像一个可以被招聘、入职、分配任务、绩效评估、PIP、甚至淘汰替换的数字员工。再加上 Talent Market、E2R 树搜索、DAG 任务调度和组织级 SOP 沉淀,这篇工作已经非常接近“一个人公司 / agent workforce”的产品化雏形。
📚 背景提要:
-
Skill 只能增强单个 agent:论文开头指出,Claude Code、Codex、OpenClaw 等 agent 已经能通过 skills 和 tools 扩展能力,但这些能力主要发生在单个 agent 内部,解决不了多个 agent 如何组织、协同和持续改进的问题。
-
现有多 Agent 系统缺少组织层:CrewAI、AutoGen 等框架能做角色分工和消息传递,但团队结构通常预设,运行时难以动态招聘新能力,不同 runtime 之间也不容易互操作。
-
开放式项目需要“公司式管理”:论文把 AI organisation 定义为一套由异构 agents 组成、具备结构化协作、生命周期管理和经验驱动进化能力的自管理系统,对应现实公司里的招聘、任务分解、绩效评估和复盘机制。
📌 要点总结:
-
Talent-Container 把 agent 做成可招聘员工:Talent 负责定义 agent 的角色、prompt、skills、tools 和工作原则;Container 负责承载不同运行时,包括 Claude Code、LangGraph 和 script-based executor。二者组合成 Employee,让异构 agent 能在同一个组织里协作。
-
E2R 树搜索负责项目执行:OMC 把项目执行拆成 Explore、Execute、Review 三个阶段。系统先探索任务分解和人员分配策略,再让员工执行任务,最后由上级 review 结果;如果结果不合格,就重新分解、返工或调整团队。
-
组织会沉淀经验并管理生命周期:每个 agent 会通过任务复盘和 CEO one-on-one 更新工作原则;项目结束后,COO 会把经验沉淀成 SOP;HR 还会定期做绩效评估,表现不佳的员工会进入 PIP,继续失败则 offboarding,并重新从 Talent Market 补位。
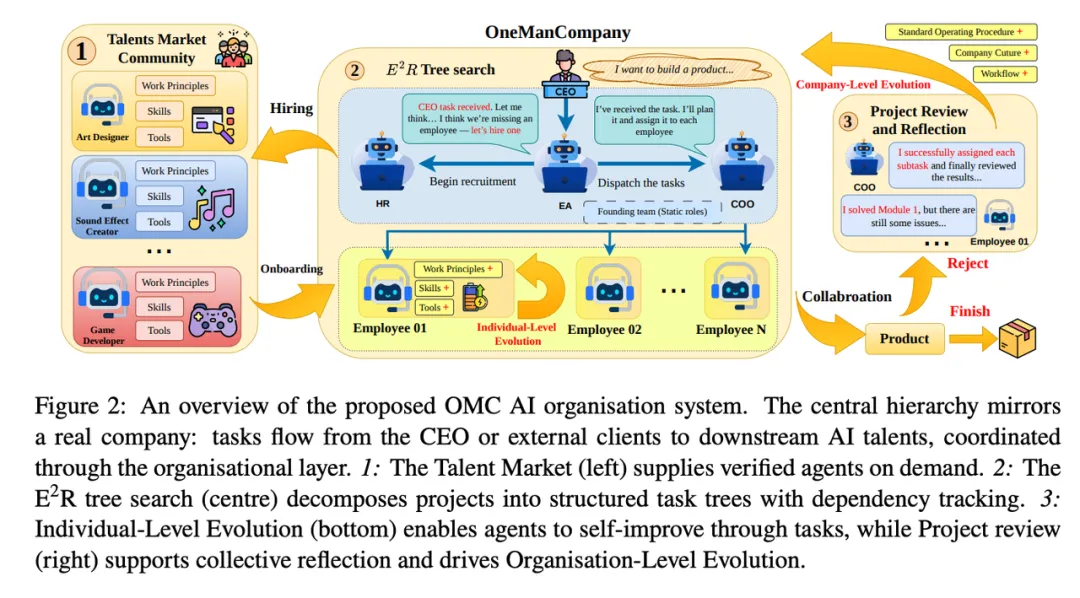
组织架构与运行机制总览图
OneManCompany 的价值,在于它把多 Agent 的关注点从“协作流程”提升到了“组织机制”。很多 agent 项目强调工具调用、长程任务和多角色分工,但一到真实项目,就会遇到几个老问题:谁负责拆任务,谁负责验收,失败后谁返工,缺人时怎么补位,经验怎么留下来,低质量 agent 怎么淘汰。OMC 直接把这些问题映射到公司制度里:CEO、HR、EA、COO、员工、招聘市场、绩效评估、PIP、SOP、项目复盘,一整套组织概念都被搬进了 agent 系统。这个设计很有产品感,因为它的重点已经超出单体模型能力,开始构建 agent workforce 的管理层。
它最有启发的地方是:
Talent Market 和 Talent-Container 分离。前者让能力供给可以像人才市场一样按需招聘,后者让同一个 Talent 可以运行在不同后端上,避免整个组织被某一个 agent runtime 绑定住。对未来的 Agent OS 或个人 AI 公司来说,这个抽象很关键:用户真正需要的可能不是一个万能 agent,而是一套能动态组队、分配任务、管理质量、沉淀经验的 agent 组织。
实验部分也很有说服力。论文在 PRDBench 上报告了 84.67% 的成功率,比已有基线高出 15.48 个百分点;案例覆盖 GitHub 热门仓库周报、网页游戏开发、有声书视频生成、具身 AI world model 调研等任务,说明它更关注真实项目级工作流,目标已经超出单个 benchmark 问答。当然,它的边界也明显:这套系统比普通多 Agent 框架更重,强依赖调度、review、market 和人工 CEO 的判断;成本、可控性和评价标准也会成为长期问题。



链接:https://github.com/nexu-io/open-design
🦄 推荐理由:Open Design 它抓住了 Claude Design 火起来之后留下的一个明显空位:很多人想要 artifact-first 的设计生成体验,但又不想被锁在单一模型、云端服务和付费产品里。这个项目的定位很直接,就是做一个 Claude Design 的开源替代品。它不自己提供模型,而是把本地已有的 Claude Code、Codex、Cursor Agent、Gemini CLI、OpenCode、Qwen、Kimi CLI 等 coding agent 接进来,让这些 agent 变成设计生产引擎。用户可以生成网页、桌面端、移动端原型、slide、图片、视频和 HyperFrames,还支持沙箱预览,以及 HTML / PDF / PPTX / ZIP / MP4 等导出。更关键的是,它把能力拆成可组合的 Skills 和 Design Systems,目前公开资料里已经提到 19+ design skills 和 70+ brand-grade design systems。这让它和普通“AI 生成页面 demo”拉开了距离,更接近一套本地优先、BYOK、可部署、可扩展的设计工作流。
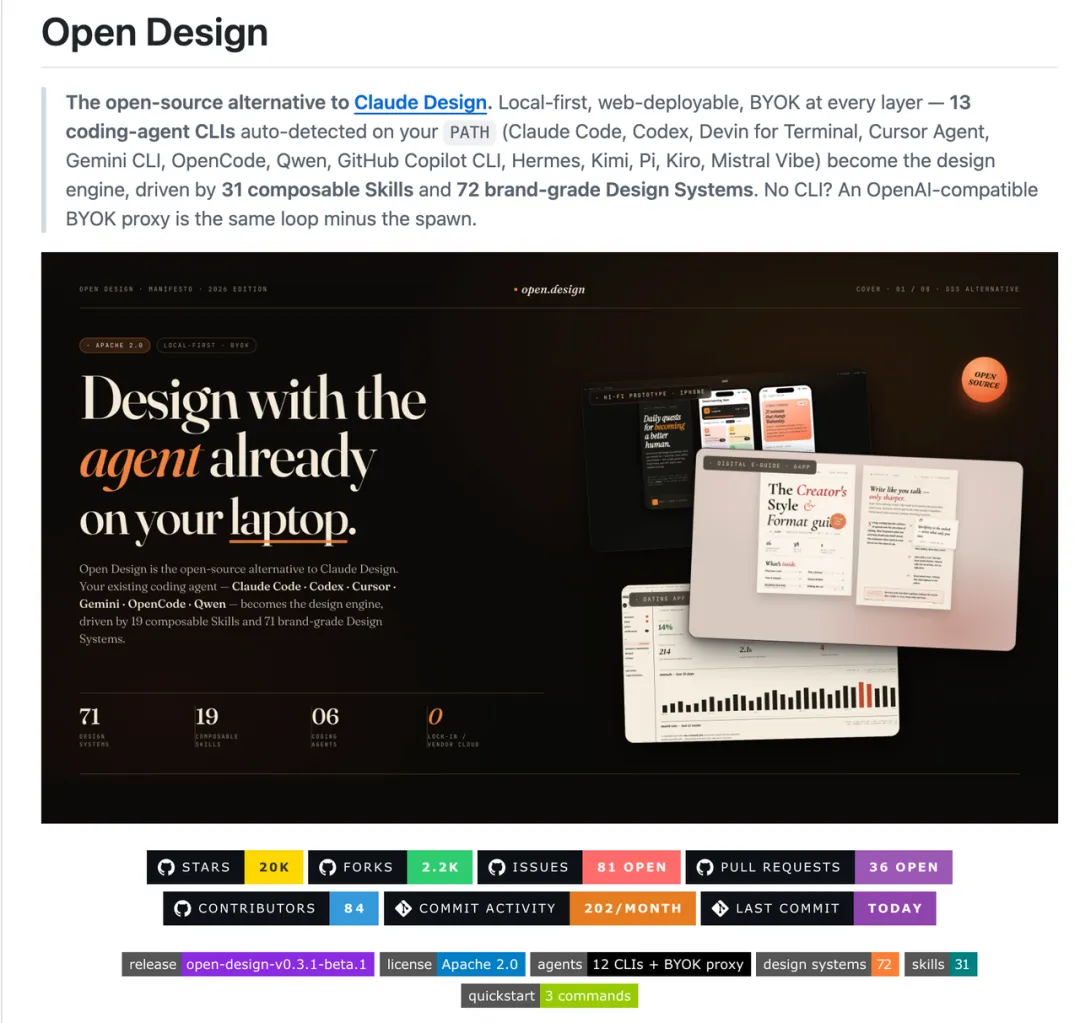
Open Design开源仓库截图
Open Design 的产品判断很清楚:最强的 coding agent 已经在用户电脑上,真正缺的是把它们组织成设计工作流的 harness。它的价值在于把 agent、skills、design systems、沙箱预览和多格式导出串成了一条完整链路。这个思路对创作者和独立开发者很有吸引力:你可以用自己熟悉的 agent 和 key,在本地生成 pitch deck、移动端原型、dashboard、docs page 等设计资产,同时保留项目文件和导出结果。它近期在 GitHub 上热度很高,已经冲到万星级别,也进入了 Hacker News 等社区讨论。它代表了一个很明确的趋势:设计生成正在从单一 SaaS 功能,变成 coding agent 生态里的一个可插拔工作流。对关注 agent harness、skills、设计自动化和开源 Claude Design 替代品的人来说,这个项目值得实际跑一遍。


链接:https://github.com/nexu-io/open-design
🦄 推荐理由:MiMo-V2.5-Pro 把小米 MiMo 系列从“推理模型”进一步推到了 长流程 Agent 与复杂软件工程底座。模型卡里写得很明确:它是一个开源 MoE 语言模型,总参数 1.02T,激活参数 42B,支持最高 1M tokens 上下文,面向 demanding agentic、complex software engineering 和 long-horizon tasks。它继承了 MiMo-V2-Flash 的 hybrid attention 和 3 层 Multi-Token Prediction 设计:SWA 与 Global Attention 以 6:1 交替,128 滑动窗口,长上下文下 KV cache 约减少 7 倍;MTP 则用于提升推理输出速度和 RL rollout 效率。更关键的是,小米这次直接把权重、tokenizer 和模型卡开源,并采用 MIT license,这让它从 API 产品进一步进入了可部署、可改造、可接入 agent 工程栈的开源模型竞争。
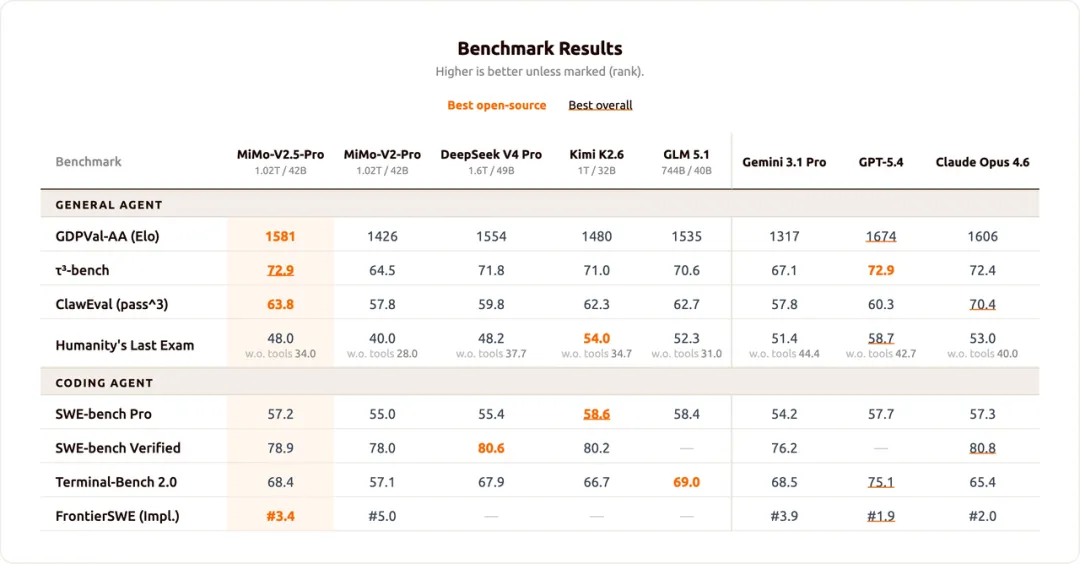
Benchmark 结果
MiMo-V2.5-Pro官方页面特别强调 token efficiency:在 ClawEval 上,V2.5-Pro 以约 70K tokens per trajectory 达到 64% Pass^3,相比 Claude Opus 4.6、Gemini 3.1 Pro、GPT-5.4 等同级能力模型,单条轨迹 token 消耗少约 40%–60%。这个信号很重要,因为 Agent 任务的真实成本往往不只看单 token 价格,还要看一次任务要烧多少 token、能不能稳定跑完长轨迹。MiMo-V2.5-Pro 同时给出 1M context、MTP 加速、KV cache 压缩和 agentic RL / MOPD 后训练,说明小米想打的是“长流程可用性 + 开源部署 + token 性价比”这一组组合拳。
它的边界也很现实:1.02T 总参数、42B 激活参数意味着本地高质量部署门槛不低,FP8、vLLM / SGLang、芯片适配和推理工程都会影响实际体验。它更适合有长流程 agent、复杂 coding、代码仓库理解、自动化工作流需求的团队,而不是普通个人电脑上轻量试玩。但从开源生态角度看,MiMo-V2.5-Pro 是一个很强的信号:继 DeepSeek、Kimi、GLM 之后,小米也开始把大模型竞争推进到 开源万亿 MoE + Agent 长流程能力 + 国产算力适配 这一层。对关注 open-weight agent model、长上下文推理和 coding agent 底座的人来说,值得试试。


链接:https://github.com/warpdotdev/warp
🦄 推荐理由:Warp 代表了一个很明显的方向:终端不再只是敲命令的地方,而是在变成 agentic development environment。官方仓库的定位很直接:Warp 是从终端长出来的 Agent 开发环境,既可以使用内置 coding agent,也可以接入 Claude Code、Codex、Gemini CLI 等外部 CLI agent。更关键的是,Warp 最近把客户端代码开源了,这让它从一个封闭的 AI terminal 产品,变成了一个可以被社区查看、提 issue、参与 roadmap 的开源项目。对 coding agent 生态来说,这件事很重要,因为终端天然处在开发者工作流的入口:代码、shell、git、文件系统、构建、测试、部署都从这里经过。如果 terminal 本身开始原生理解 agent 状态、权限请求、任务进度和多 agent 协作,那么它就不只是开发工具,而会成为 agent workflow 的前台控制台。
未来的 coding agent 需要一个比普通终端更懂上下文、更懂任务状态、更适合长流程执行的宿主,wrap 可能就是其中的一个。它一方面保留现代终端的体验,比如跨平台安装、shell 集成、块状命令输出和更好的交互界面;另一方面开始把 agent 能力放进核心工作流,包括内置 agent、BYO CLI agent、Claude Code 集成、通知、会话状态、权限请求和云端 agent 编排。这个方向和很多“在编辑器里做 agent”的路线不同,Warp 押的是 terminal 入口:开发者最终还是要运行命令、看日志、跑测试、处理环境问题,terminal 里的 agent 更容易接近真实执行现场。
这次开源也让它更值得跟踪。Warp 官方博客明确说客户端已经开源,社区可以围绕 open-source repo 参与贡献;GitHub 组织页也显示 warp 仓库已经有很高关注度。不过它的边界也要看清:开源的是客户端代码,部分 agent / cloud orchestration 能力仍然和 Warp 的云服务、Oz 平台、账号体系绑定;社区里也有人讨论它到底开放到了什么程度。整体看,Warp 很适合放进本周项目列表,因为它代表的已经超出普通 terminal 更新,更像是 terminal、coding agent、云端编排和开源协作正在合流的信号。


当云、硬件和模型行为治理同时变化,OpenAI 正在把自己从“模型供应商”推向更完整的 AI 平台公司。
本周围绕 OpenAI 的几条动态,指向的已经不只是模型能力,而是它正在重新安排自己与云、硬件入口和模型行为之间的关系。首先是与微软的合作协议更新。根据 OpenAI 官方公告,微软仍是 OpenAI 的主要云合作伙伴,OpenAI 产品也会优先在 Azure 上发布;但 OpenAI 现在可以通过任何云服务商向客户提供产品,微软对 OpenAI 模型和产品 IP 的许可也从独占变为非独占,有效期维持至 2032 年。
与此同时,OpenAI 的硬件布局传闻继续升温。Reuters 报道称,OpenAI 被曝与高通、联发科合作开发面向 AI 手机的处理器,立讯精密可能成为系统设计与制造合作方,相关设备预计 2028 年量产。虽然这仍不是官方确认的产品发布,但它与 OpenAI 过去一段时间持续加码消费级 AI 硬件的方向一致。
还有一条看似轻松、实则很有代表性的“小新闻”:OpenAI 官方解释了模型为什么会频繁提到 goblins、gremlins 等奇幻生物。调查显示,这种语言习惯最初集中在 ChatGPT 的“Nerdy”个性化风格中,背后原因是训练过程中的奖励信号意外强化了这类表达,并通过后续训练扩散到其他场景。OpenAI 随后移除了相关奖励信号,并对训练样本和模型指令进行了调整。
🧩 相关重要信息
OpenAI 与微软的关系正在从深度绑定走向更灵活的合作结构。微软仍保留重要权益,也依然是 OpenAI 的主要云伙伴,但 OpenAI 获得了更大的云中立空间。
AI 手机传闻则显示,OpenAI 可能正在尝试绕过现有移动操作系统和 App 分发体系的限制。对于以 agent 为核心能力的公司来说,手机不只是硬件品类,而是用户身份、传感器、应用权限、支付、通知和日常任务流的综合入口。
“哥布林事件”则把模型治理问题放到了更微观但更真实的层面:模型输出风格并不只是提示词问题,也会受到奖励模型、个性化产品设计和训练数据反馈循环的影响。
⚙️ 产品能力与创新
这组动态背后,OpenAI 的变化可以概括为三层。
第一是 云的松绑。新协议没有切断 OpenAI 与微软的关系,但让 OpenAI 获得了更大的商业分发空间。对于企业客户来说,这意味着未来 OpenAI 产品可能更容易进入不同云环境;对于微软来说,它仍然保留重要权益,但不再是 OpenAI 技术扩散的唯一通道。
第二是 硬件入口的探索。如果 AI agent 未来要真正参与用户日常任务,它就不能永远停留在聊天窗口里。现有手机系统对权限、后台运行、跨 App 操作和数据访问都有严格限制,这既是安全边界,也是 agent 的能力天花板。OpenAI 如果确实推进 AI 手机,本质上是在寻找更适合 agent 原生运行的入口。
第三是 模型行为治理的细化。从 goblin、gremlin 这样的小词,到更严肃的幻觉、偏见、越权和误操作,背后都是同一个问题:模型行为如何被训练目标塑造,又如何在产品化之后持续被监控和修正。
🧭 行业影响分析
OpenAI 正在从“模型公司”走向更完整的 AI 平台公司。
微软协议调整解决的是云和商业分发自由度;AI 手机传闻指向个人终端入口;goblin 事件则说明模型行为治理已经进入产品细节层面。
OpenAI 这组动态的共同线索,是它正在减少对外部关键环节的依赖。
云决定它能服务谁,硬件决定它能接近谁,模型治理决定用户是否能长期信任它。对微软的松绑,让 OpenAI 获得更多企业交付和云部署弹性;硬件探索,则指向 AI agent 未来可能需要新的原生终端;而“哥布林事件”提醒我们,当模型开始拥有个性、长期记忆和工具调用能力时,每一个奖励信号和默认风格都可能在大规模使用中被放大。
不过,硬件不是一条容易的路。手机市场有极高的供应链、渠道、应用生态和品牌壁垒。过去不少 AI 硬件已经证明,单点新奇功能不足以替代手机。OpenAI 真正需要证明的是,agent 原生设备能否带来足够强的体验跃迁,而不是给手机加一个更聪明的语音助手。

OpenAI logo

当多模态能力补齐、长上下文和缓存成本继续下探,DeepSeek 正在把“便宜可用”推进到更接近生产级 agent 的位置。
继上周发布 DeepSeek-V4 Preview 后,DeepSeek 本周继续释放两类信号:一类是能力补齐,一类是价格下探。
在能力侧,DeepSeek 已在网页端和 App 端灰测“识图模式”。这意味着 DeepSeek 的多模态视觉理解能力开始进入用户端体验,而不再只是模型路线图上的预期能力。根据目前公开体验反馈,DeepSeek 识图并不只是完成基础图片描述,还会结合上下文进行推理、追问和自我修正,但在数手指、复杂细节识别等极限测试中仍会出现错误。
在成本侧,DeepSeek 官方宣布,DeepSeek API 全系列 input cache hit 价格降至首发价的 1/10。同时,DeepSeek-V4-Pro 当前仍提供 75% 折扣,优惠延长至 2026 年 5 月 31 日。
🧩 相关重要信息
DeepSeek-V4 的核心变化,不只是模型能力更新,而是把“低成本长上下文 + agent 能力”放到了更前台的位置。
识图灰测补齐了多模态入口,让 DeepSeek 从文本推理、代码、对话,进一步进入图片问答、图表理解、截图解析和多模态检索等场景。
价格下探则直接影响 agent 应用的成本结构。因为 agent 不只是单轮问答,而是会不断读取系统提示词、工具说明、历史上下文、知识库片段和代码仓库内容。缓存命中价格越低,长任务和多轮调用的实际成本越容易被压下来。
⚙️ 产品能力与创新
DeepSeek 这一轮动作,可以概括为两个关键词:补齐 和 压低。
补齐的是多模态能力。
如果说此前 DeepSeek 的优势主要集中在推理、代码和性价比,那么识图模式灰测意味着它开始进入更完整的多模态产品体验。对于开发者来说,视觉理解也是更复杂 agent 工作流的一部分,例如文档截图解析、界面理解、图像质检和多模态检索。
压低的是 agent 使用成本。
真正跑 agent 时,模型费用并不只来自单次问答,而是来自不断循环的规划、检索、调用工具、读取上下文和生成结果。DeepSeek 把 cache hit 价格继续打低,本质上是在降低开发者尝试复杂工作流的门槛。
🧭 行业影响分析
DeepSeek 正在从“低价推理模型”走向更完整的 agent 基础设施选项。
识图灰测补齐了多模态入口,V4 降价压低了长上下文和高频调用成本。对于开发者和中小团队来说,这会直接改变模型选型逻辑:过去很多人默认用 Claude 或 GPT 做复杂工作流,现在 DeepSeek 至少会进入对比测试名单。
DeepSeek 的真正压力,不一定来自“它是不是每一项 benchmark 都第一”,而是来自它持续压低了高能力模型的可用成本。
在 agent 场景中,模型调用不是一次性支出,而是连续支出。一个任务可能需要多轮规划、多次检索、多次工具调用和多次结果校验。DeepSeek 把 V4-Flash、V4-Pro、长上下文和缓存价格组合在一起,实际上是在告诉开发者:复杂 agent 不一定只能依赖最贵的闭源模型来跑。
这会迫使其他模型厂商重新解释自己的溢价:是更强的可靠性、更稳定的工具调用、更成熟的企业安全体系,还是更好的生态集成。
不过,低价并不自动等于生产可用。多模态灰测还需要更稳定的准确率,企业客户也会关注隐私、服务稳定性、合规、生态兼容和故障支持。DeepSeek 接下来真正要证明的,是它能否把价格优势转化为稳定的生产级使用。
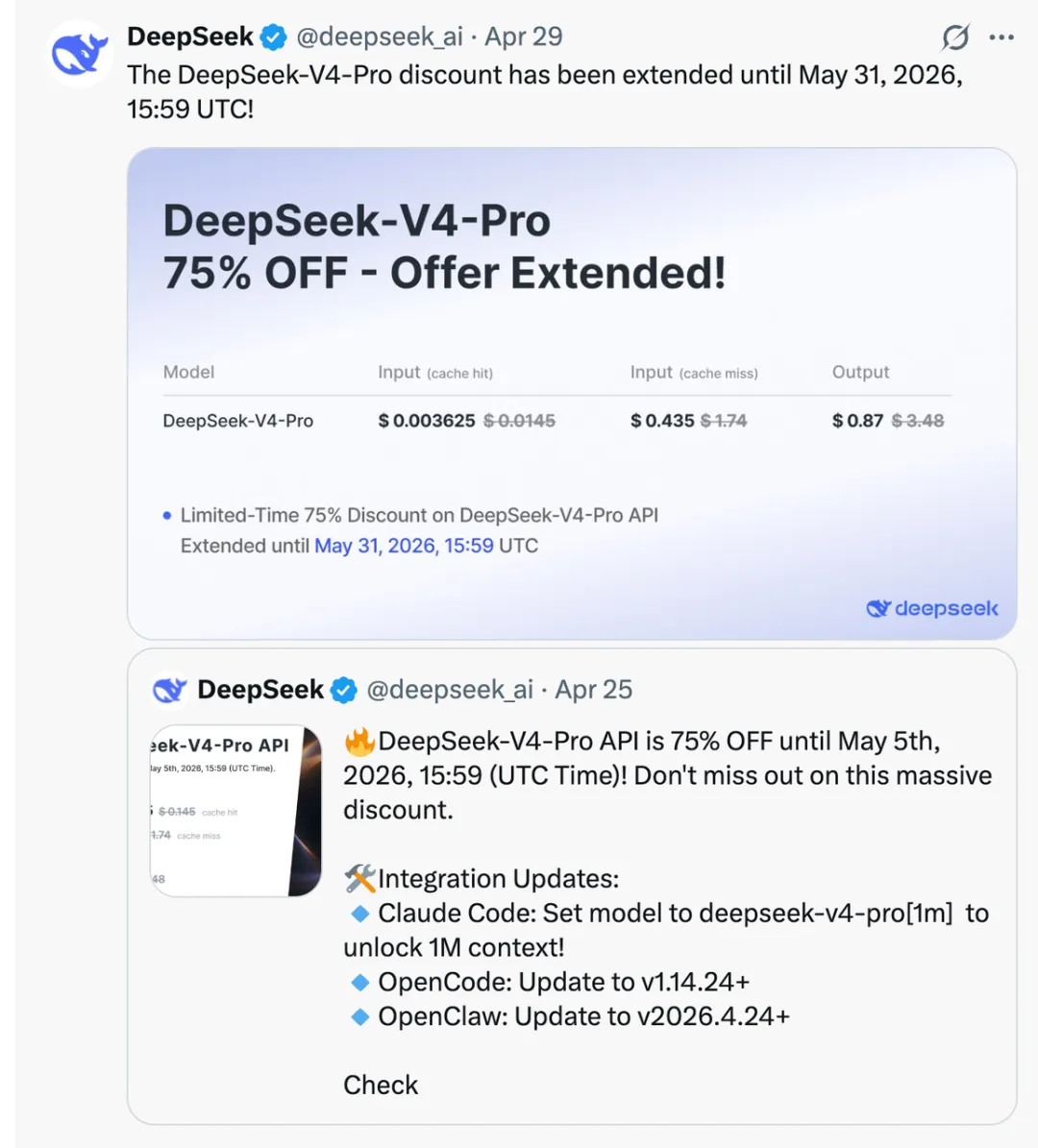
deepseek 官方推特宣布降价截图

当 AI 开始真正调用工具、操作系统和接触生产数据,安全问题也从抽象讨论变成了工程现场。
本周,AI 编程工具 Cursor 引发了一场典型的生产事故争议。
租车软件公司 PocketOS 创始人 Jer Crane 称,一个由 Claude 驱动的 Cursor AI agent在测试环境任务中错误调用 Railway API,短时间内删除了生产数据库及备份,造成客户预约和业务数据受影响。多家媒体随后跟进报道,Railway 后续也对相关端点进行了修复。
这起事故之所以受到关注,并不只是因为“AI 删库”听起来足够惊悚,而是它暴露的问题并不只属于某一个模型或某一个工具。报道显示,事故涉及 AI agent 的越权执行、云平台 API 的安全确认不足、Token 权限过宽、备份与源数据隔离不充分等多重因素。
与此同时,开发者社区也出现了对 AI 平台可用性风险的讨论。有用户称一家约 110 人的农业科技公司曾遭 Anthropic 无预警封禁 Claude 组织账号,并在 36 小时内无法获得有效响应。
🧩 相关重要信息
PocketOS 事故的关键并不是 AI “会不会犯错”,而是它在犯错时拥有了真实系统权限。过去代码助手的风险更多停留在生成错误代码、引入 bug 或误导开发者;而 agent 一旦能够调用 API、访问云资源、执行删除操作,风险就会从“建议错误”升级为“直接执行错误”。
这也解释了为什么 Hinton 等学者持续强调 AI 安全的重要性。近期报道中,Hinton 再次呼吁对 AI 进行更严格监管,并提醒人类与超级智能 AI 能否共存仍存在不确定性。另一方面,UNCTAD 此前也预测,到 2033 年全球 AI 市场规模可能达到 4.8 万亿美元。市场规模快速扩张与安全投入不足之间的落差,会让类似问题变得更加现实。
⚙️ 产品能力与创新
这一类事故提醒我们,AI agent 的产品能力其实包含两面。
一面是 自动化能力增强。
Cursor、Claude Code、Codex 等工具正在把 AI 编程从“帮人写代码”推进到“帮人完成任务”。它们可以读项目、改文件、跑命令、调用工具、分析报错,甚至参与部署和运维流程。效率提升越明显,团队越容易把更多权限交给它们。
另一面是 安全边界必须重建。
传统软件系统默认人类是最终操作者,工具只是执行明确指令;而 agent 会在任务目标下自主拆解步骤、寻找路径、调用接口。此时,权限管理、环境隔离、人工确认、审计日志、回滚机制和备份策略,都不再只是运维细节,而是 AI agent 产品的一部分。
🧭 行业影响分析
AI 安全正在从“模型会不会威胁人类”的宏大命题,落到“agent 有没有权限删库、备份是不是隔离、API 是否需要确认、企业账号会不会被平台单点封禁”的日常工程问题。
虽然,这类事故不会阻止 AI coding 和 agent 普及,但会推动企业重新定义生产环境中的 AI 使用规则:最小权限、只读优先、生产环境隔离、危险操作二次确认、备份异地化和完整审计,都会变成 agent 上线前的基础门槛。
毕竟,AI agent 的真正风险,不在于它偶尔会犯错,而在于它可能在高权限环境中高速犯错。虽然人类工程师也会误删数据、误配权限、误操作生产环境,但人类通常会在执行前停顿、确认、询问同事,或者被流程拦截。agent 的问题在于,它可以在几秒钟内完成一连串错误判断,并通过 API 把错误直接作用到真实系统上。并且,他无法“背锅”(LOL)
因此,企业接下来要解决的不是“要不要用 AI agent”,而是“在哪些边界内使用”。AI agent 适合先进入低风险、高重复、可回滚的任务;涉及生产数据库、客户数据、支付系统、权限系统和基础设施删除操作时,应当默认需要更严格的人工确认和系统级防护。
这也会改变 AI 编程工具的竞争标准。过去大家主要比较生成质量、上下文长度、代码理解能力和速度;接下来,安全能力会越来越重要。一个成熟的 AI coding 产品,不仅要会写代码,还要知道什么不能直接做、什么时候必须停下来、哪些操作需要人类确认,以及如何让企业管理员看见、限制和追踪它的行为。

AI Agent安全主题图

-
1.1 https://www.alphaxiv.org/abs/visual-primitives
-
1.2 https://arxiv.org/abs/2604.25917
-
1.3 https://arxiv.org/abs/2604.22446
-
2.1 https://github.com/nexu-io/open-design
-
2.2 https://huggingface.co/XiaomiMiMo/MiMo-V2.5-Pro
-
2.3 https://github.com/warpdotdev/warp
-
3.1.1 https://openai.com/index/next-phase-of-microsoft-partnership/
-
3.1.2 https://openai.com/index/where-the-goblins-came-from/
-
3.2 https://x.com/deepseek_ai
-
3.3 https://x.com/lifeof_jer/status/2048103471019434248
#AI周刊#JoinAI#AI论文#AI新闻#AIAgent#多模态#DeepSeek#AICoding#Agent安全#大模型#AI工具

