 夜雨聆风
夜雨聆风





「码途AI」AI学习专题 | 每周一章 – 第四章 10分钟搭建本地大语言模型!用LangChain调用Ollama,轻松上手开发
我最近刚好完整跑了一遍。从安装 Ollama,到下载模型,再到用 LangChain 在 Python 里调用本地模型做流式输出,整个过程并不复杂。
所以这篇文章不只讲安装步骤,也把这次实测过程里的结论一起整理出来。如果你想先把本地模型跑起来,照着做就行;如果你更关心我们平时使用的电脑到底适合什么模型,后面的部分也能直接参考。
一、为什么值得试一次本地大模型?
原因很简单:省钱,也更可控。
和直接调用云端 API 相比,本地部署有几个很实际的好处:
-
不用反复买 Token -
数据不出本机,隐私压力更小 -
适合做原型验证和功能测试 -
跑通之后,后面接代码会更灵活
尤其是对产品经理、独立开发者和刚接触 AI 应用的人来说,本地跑通一遍,理解会快很多。你会更清楚模型是怎么运行的,代码是怎么接进去的,性能瓶颈到底在哪里。
二、Ollama 是什么?
可以把 Ollama 理解成一个本地模型运行工具。
它把模型下载、模型管理和本地推理都封装好了,不需要自己从底层一点点搭。对想快速上手的人来说,它最大的优点就是简单。
最常用的命令就这几个:
ollama pull qwen3:4bollama listollama run qwen3:4b如果你是第一次在本地玩大模型,Ollama 很适合拿来入门。
三、这次测试用的电脑配置
先把测试环境放出来,方便你对照自己的机器判断。
我的电脑配置:
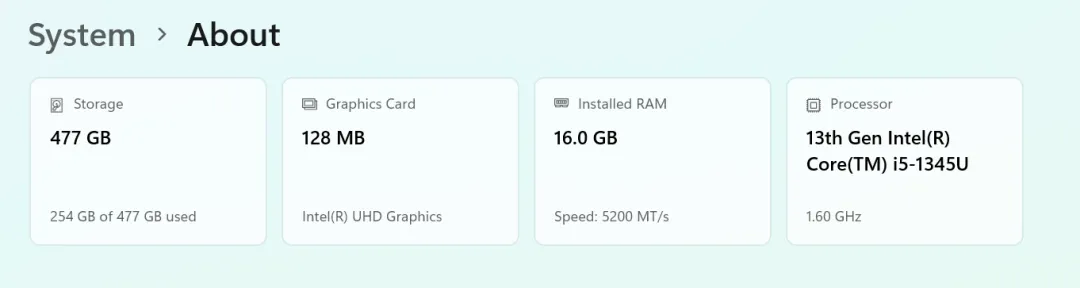
-
内存:16GB -
处理器:13th Gen Intel(R) Core(TM) i5-1345U -
CPU 核心数:10 核
先说结论:这类 i5-1345U + 16GB 内存 的联想轻薄本,可以跑本地大模型,但更适合轻量级、量化后的小模型。真要说体验,大概就是“能用,但别指望特别流畅”。
如果你的电脑配置和我接近,这篇文章里的结论基本都能参考。
四、这台电脑的瓶颈到底在哪里?
对这台机器来说,瓶颈主要有两个。
1. 内存是第一道门槛
虽然机器是 16GB 内存,但 Windows、浏览器、输入法和各种后台程序本身就会占掉不少。真正跑模型的时候,能稳定分给模型的,通常也就 10GB 左右。
这意味着:
-
4B 及以下模型更稳妥 -
7B 模型可以尝试,但得用更激进的量化版本,还要把上下文压小 -
更大的模型,基本不适合这类轻薄本上使用,也跑不起来。
我刚开始测试时,使用的是deepseek-r1:8b模型,就遇到过很典型的报错:
model requires more system memory (3.3 GiB) than is available (2.7 GiB)这句话的意思很直接:当前可用内存不够,模型跑不起来,所以后面我换了4B及以下的模型。
要注意,这里看的是“可用内存”,不是“总内存”。就算机器标着 16GB,如果后台程序开得多,一样可能报这个错。
2. CPU 能跑,但速度有上限
i5-1345U 是轻薄本常见的低功耗处理器,日常办公没问题,但不是专门拿来做大模型推理的。再加上没有独显,本地推理基本只能靠 CPU 和内存硬扛。
实际体验就是:
-
能生成结果,但不会特别快 -
适合做轻量问答、文档总结、Demo 演示 -
不适合对实时性要求高的场景
五、这台机器适合跑什么模型?
如果把“能不能跑”和“跑起来舒不舒服”分开看,这台机器大致可以这样选模型:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果压缩成一句话,就是:
-
最适合的是 3B 到 4B 的量化模型 -
1B 到 2B 更快,但回答质量和稳定性会差一些 -
7B 不建议当这台机器的日常主力模型
六、第一步:安装 Ollama
Windows 用户直接去官网下载安装就行。
安装完成后,先在 PowerShell 里执行:
ollama --version能看到版本号,说明安装成功。
然后再执行:
ollama list如果你是第一次装,列表为空很正常。
七、第二步:下载本地模型
结合这台 16GB 机器的表现,我更建议先从中小模型开始。
比如先拉一个 4B 模型:
ollama pull qwen3:4b如果你想先验证流程、尽快看到结果,也可以直接拉一个更小的模型:
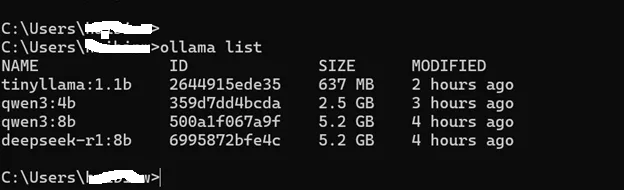
ollama pull tinyllama:1.1b下载完成后,用下面这条命令确认本地模型列表:
ollama list如果你只是想先把流程跑通,可以这么选:
-
想要相对稳一点: qwen3:4b -
想要尽快跑起来: tinyllama:1.1b
还有几个很实用的小建议:
-
跑模型前,尽量关掉浏览器、Office 之类的后台程序 -
上下文窗口不要开太大,轻薄本上 1024以内更合适 -
优先用已经量化好的模型,不要一开始就追求参数更大
八、第三步:安装 LangChain 依赖
如果你只是想在终端里直接和模型对话,到这一步其实已经够了。
但如果你想用 Python 调用本地模型,就还要装 LangChain 相关依赖:
pip install langchain langchain-ollama我一开始测试时,第一次就碰到了这个错误:
ModuleNotFoundError: No module named 'langchain_ollama'本质上没别的原因,就是依赖没装好。把 langchain-ollama 装上之后,代码就能继续跑。
九、第四步:写一个最小可用测试脚本
这里给一个尽量简单、直接能跑的例子。
它做了三件事:
-
用 SystemMessage约束模型角色 -
用流式输出实时打印内容 -
记录总响应时间,方便对比不同模型的速度
import timefrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_ollama import ChatOllamamessages = [ SystemMessage("你是码途AI问答助手,专注于技术问题解答。请用简洁、专业的中文回答用户的问题。"), HumanMessage("请用简洁的语言介绍一下你是谁,以及你能提供哪些帮助。")]ollama_llm = ChatOllama(model="tinyllama:1.1b", num_ctx=256)start_time = time.time()for chunk in ollama_llm.stream(messages): print(chunk.content, end="", flush=True)end_time = time.time()print(f"\n响应时间: {end_time - start_time:.2f} 秒")运行命令:
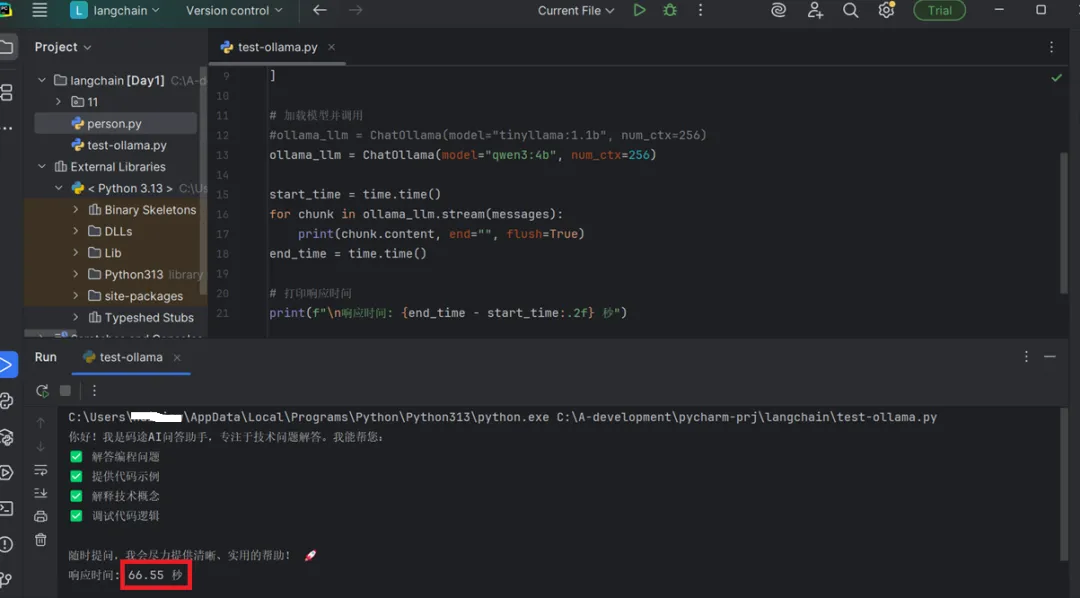
python .\test-ollama.py使用qwen3:4b 模型,截取其中一次问答如下,耗时 66.55秒:
十、为什么后来我改用了小模型?
原因很实际:大一点的模型在这台机器上耗时长。
我前面试过更大的模型,结果很直接,要么内存不够,要么速度太慢。为了先把整条链路跑通,我后面切换成了更小的模型,比如:
-
tinyllama:1.1b -
num_ctx=256
这么做的好处很明显:
-
更容易成功运行 -
内存压力更小 -
响应速度更快 -
更适合做演示和学习
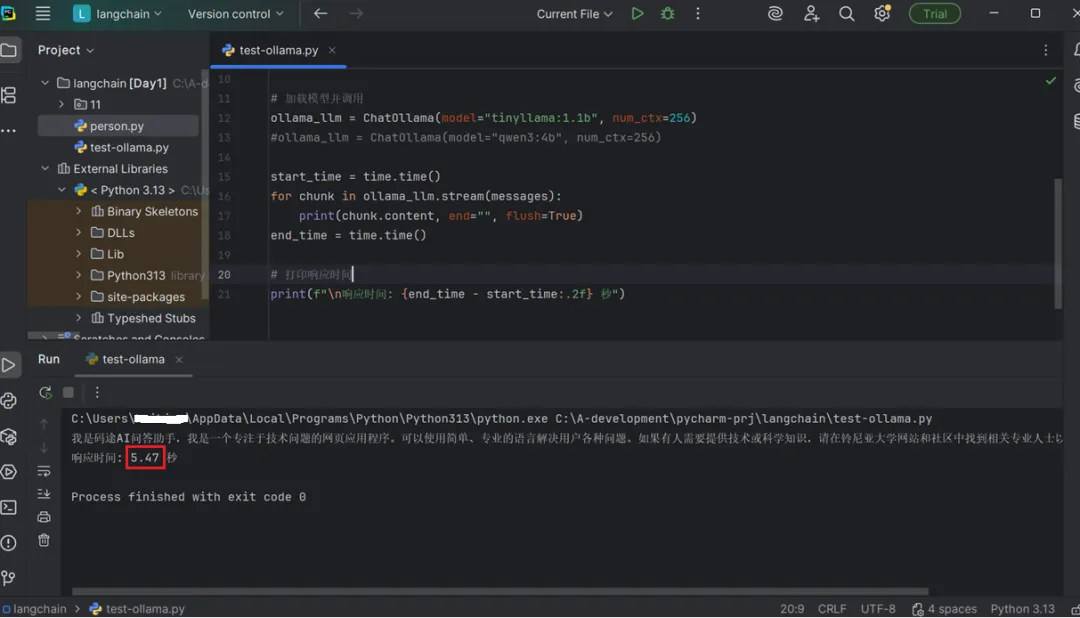
使用tinyllama:1.1b 模型,截取其中一次问答如下,耗时 5.47秒:
十一、用了小模型之后,我碰到哪些问题?
很多教程都会告诉你,小模型更省资源、速度更快。这句话没错,但只说了一半。
另一半是:小模型更容易答偏,稳定性也差一些。
我实际测试下来,主要碰到了下面几个问题。
1. 回答会跑偏
明明已经在系统消息里写清楚角色了,用户问题也很明确,但有些回答还是会偏题,甚至看起来有点奇怪。
这说明小模型在理解角色和约束这件事上,本来就没那么稳。
2. 有时中文,有时英文
同一段代码,多跑几次,输出语言不一定稳定。有时候是中文,有时候会突然冒出一段英文。
原因通常也不复杂:
-
小模型约束能力弱 -
训练语料本身就是多语言混合 -
提示词不够强时,语言更容易漂移
3. 容易重复、啰嗦
小模型很容易把一句话能说清的事情,拉成一大段。看起来字很多,但真正有用的信息不多。
常见表现有:
-
同一个意思反复说 -
内容空泛 -
句子看着完整,但重点不够明确
4. 风格不稳定
有时候像客服,有时候像英文助手,有时候又像在写宣传文案。
如果只是自己测试,这还不算大问题;但如果真拿去做产品原型,这种漂移感会很明显。
5. 速度快了,但没快到“秒回”
换成小模型之后,响应时间确实降下来了。我测试里大概见过这些结果:
-
12.43 秒 -
11.01 秒 -
7.96 秒 -
5.17 秒
说明小模型确实有提速效果,但也别期待它在这类轻薄本上像云端服务一样“秒回”。
影响本地响应速度的,不只是模型大小,还有这些因素:
-
当前系统资源占用 -
CPU 负载 -
上下文长度 -
问题本身的复杂度 -
输出内容的长短
十二、小模型适合什么场景?
我的结论是:小模型很适合拿来跑流程,但不适合直接承担高质量输出任务。
适合它的场景有:
-
本地体验大模型 -
验证 LangChain 调用链路 -
快速做 Demo -
做原型和功能验证 -
学习提示词怎么写
如果你想要的是更自然、更稳定、更像正式助手的回答,那小模型通常只能当过渡方案。
十三、怎么尽量减少小模型“答得怪”的问题?
如果你现在只能先用小模型,那至少可以先做这几件事。
1. 系统消息尽量写具体
不要只写“你是一个 AI 助手”,这种约束太弱。
像下面这种会更有效:
SystemMessage("你是码途AI问答助手,专注于技术问题解答。请用简洁、专业的中文回答用户的问题。")这里一次性把角色、领域、语言和语气都说清楚了。
2. 用户问题尽量明确
不要只问“介绍一下自己”。
改成“请用简洁的语言介绍一下你是谁,以及你能提供哪些帮助”,模型通常会更容易答在点上。
3. 上下文别开太大
如果只是本地测试,没必要一开始就把上下文窗口拉很高。
比如:
ChatOllama(model="tinyllama:1.1b", num_ctx=256)这样更省内存,也更适合轻量测试。
4. 对小模型的预期要放对
小模型最重要的价值,不是一次性给你特别高质量的回答,而是帮你先把这条链路跑通:
-
模型部署 -
代码调用 -
提示词设计 -
流式输出 -
基础问答验证
流程跑通了,后面再换更强的模型,才更有意义。
十四、什么时候该换更大的模型?
当你已经把这些都跑顺了:
-
Ollama 安装好了 -
模型能正常下载和运行 -
LangChain 能顺利调用 -
流式输出没有问题 -
提示词结构也基本稳定了
那下一步就该考虑换更强一点的模型,去提升回答质量。
如果机器资源允许,可以优先试 4B 左右的模型,在速度和质量之间找一个平衡点。
如果资源不够,那就只能接受这个现实:本地体验本来就是在做取舍。
-
要速度,就选更小模型 -
要质量,就选更大模型 -
想两边都兼顾,就得上更好的硬件
十五、最后做个总结
把这次实测压缩成几个结论,其实很清楚:
-
Ollama 很适合做本地入门,安装和使用门槛都不高 -
LangChain 接本地模型并不复杂,适合做快速实验 -
16GB 内存的轻薄本可以跑中小模型,但不适合追更大的参数量 -
这类机器上,3B 到 4B 的量化模型通常最均衡 -
小模型能明显降低门槛,但回答质量更容易波动 -
如果只是学习和验证流程,小模型完全够用 -
如果要做更正式的产品体验,最终还是得看模型质量和硬件能力
本地大模型真正有意思的地方,不只是把它跑起来,而是你在这个过程中,会很快知道什么方案适合自己,什么地方值得继续投入。
如果你也在尝试本地大模型,欢迎关注码途AI。后面我会继续分享更多 LangChain 实战、本地模型调优和 AI 应用落地的内容。