 夜雨聆风
夜雨聆风





AI:人类先验与计算的博弈
一句开场,和这篇文章的主旨
每一代 AI 兴起时,都会有人替上一代辩护:新东西不可解释、不可控、黑盒。从 SIFT 看 LeNet 的年代,到今天用传统深度学习看 LLM,叙事几乎没有变过。
但三十年回头看,后一代很少把前一代直接推下舞台。更常见的是:技术谱系扩展了,旧方法退回到更适合自己的场景,在那里继续高效、稳定地工作。
我早年在 IDG 做过一份 AI 行业内部研究报告。这篇算是在那份底稿上,补上这几年自己的理解,也顺着上一篇《智矿:高智力密度数据之争》的思路,回头梳理一下 AI 三十年的演进脉络。
这些观察更多是从外部视角做的一阶推演,写出来主要是为了理顺自己的思路,不代表定论。
这篇文章的主旨可以浓缩成三个词:人类先验、计算、数据。
AI 三十年的演进,本质上都在这三个维度之间博弈:人类先验逐步退场,计算在更大尺度上叠加,数据形态一次次跃迁。
每一幕的飞跃都不是线性的,而是这三条线中的某一条,找到了新的指数维度。
这条主轴和 Sutton 那篇 The Bitter Lesson [1] 说的是同一件事:凡是能 scale 的方法,最后都会把不能 scale 的方法挤到边上。
AI 1.0:人编码先验,机器求解优化
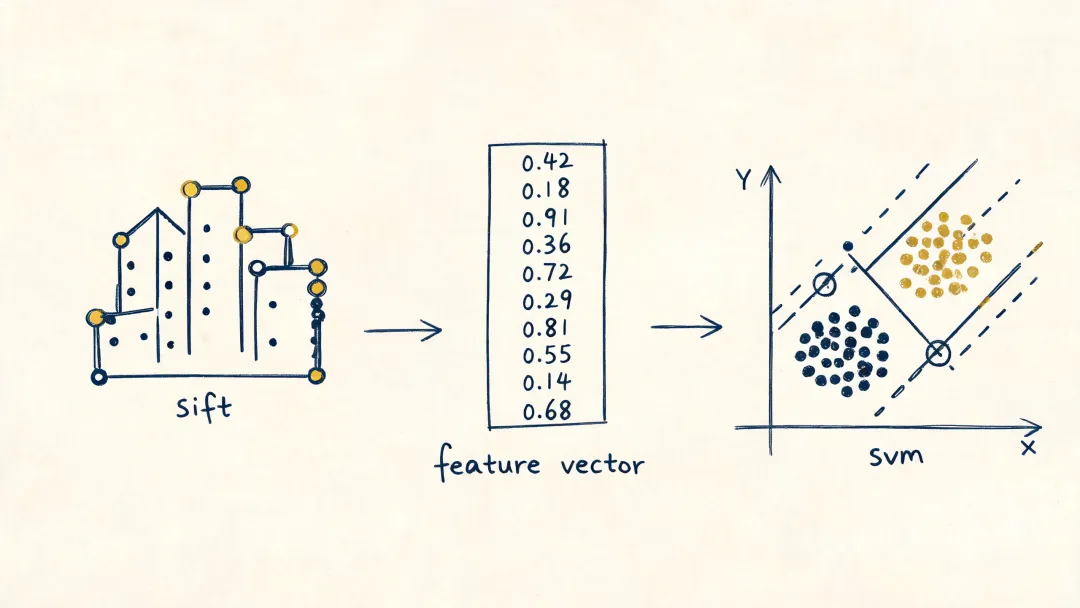
时间窗大概是 1990s 到 2011,AlexNet 之前。
这一幕的灵魂是特征工程。图像里抽 SIFT [2]、HOG [3]、Haar,文本里做 BoW、TF-IDF、n-gram,语音里取 MFCC——每一种特征,都是人对某个模态的物理理解和任务经验的压缩。
模型族也不大:SVM、Random Forest [4]、AdaBoost、CRF、HMM,各自占据一类细分问题。图像识别、信息检索、广告排序、语音识别、序列标注,本质上都是”人先把世界压成一组特征,机器再在特征空间里求解”。
机器在做什么?在人工构造好的特征空间里拟合边界、排序函数或状态转移。SVM 求最大间隔,Logistic Regression 做凸优化,Random Forest 贪心地分裂决策树,HMM / CRF 则把序列结构显式写进模型。
当时也叫训练,但它和今天意义上的训练不是一回事。那时的训练,更像是在一个被人充分压缩过的问题上求解或拟合;后来深度学习里的训练,则是在海量非凸参数空间中,用随机梯度一点点搜索。
数据常在千到万量级,少数大规模场景推到十万量级。参数从百到十万量级,单机 CPU 训练一次通常需要几小时到几天。预算几乎全花在”特征怎么设计”上,参数本身的开销反而不是核心瓶颈。
可解释性是默认要求。每一维特征的物理含义、每一条规则的来源、每一段决策边界的理由,都要能讲清楚。
这一幕的隐藏假设是:人对世界的抽象是核心能力,机器只是把人的抽象向量化之后,画出一条边界。
AI 2.0:机器端到端学特征
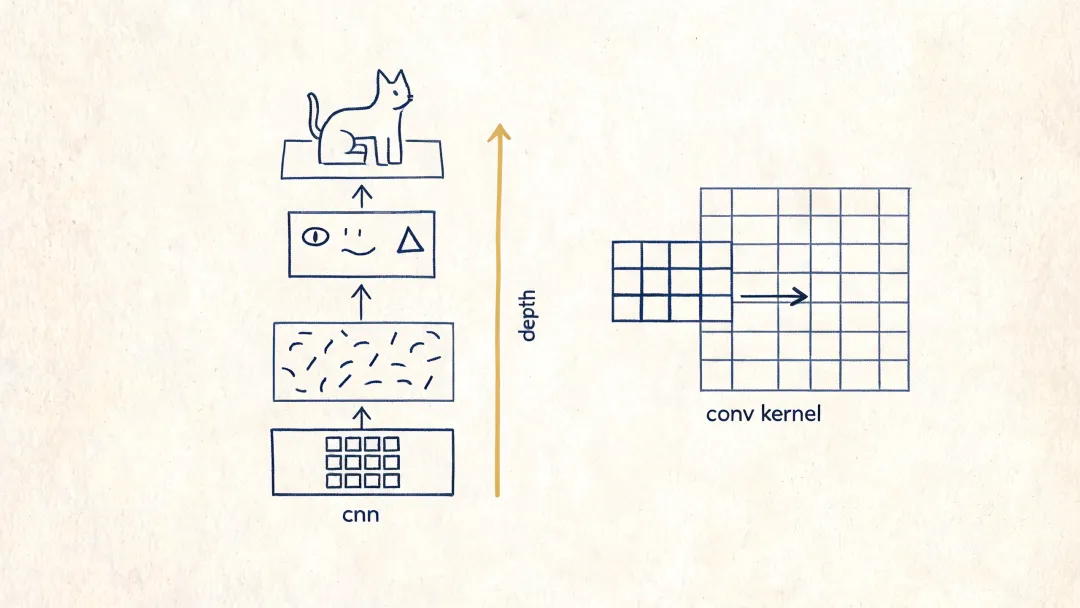
2012 年的 ImageNet 比赛,是这一幕的起点。AlexNet [5] 把 ILSVRC-2012 的 top-5 test error 一举压到 15.3%,第二名是 26.2%。从那一刻起,”特征怎么设计”在视觉领域开始退场,并在几年里顺次蔓延到 NLP、语音和推荐系统。
人的工作变了:不再手工设计特征,而是设计可学习的问题——把一个真实任务转译成输入、标签、损失函数和评测指标。数据收集和标注成为新的瓶颈。ImageNet [7]、COCO、SQuAD 这些数据集,本身就是这一代 AI 的功勋章。
但人类先验并没有消失,只是从特征层下沉到了结构层。CNN 默认局部像素更相关,RNN 默认序列状态要逐步递推,早期 seq2seq + attention 也把输入输出的对齐方式部分写进了结构里。人不再直接告诉机器”边缘在哪里”,但仍然在告诉机器”图像该怎么读,序列该怎么展开”。
数据从万级最高推到百万—千万级,按上限看提高了三个数量级。算力则从 CPU 转向 GPU。AlexNet 在两块 GTX 580 上训练了五到六天;如果粗略按单次训练 FLOPs 估算,相比传统单机 CPU 时代的多数经典任务,训练计算量至少跃升了数个数量级。
Deep Learning 不是把单层结构变得更复杂,而是把同一种简单算子在层数上反复叠加。VGG 19 层,GoogLeNet 22 层,ResNet 152 层。残差连接让更深的网络变得可训练,深度本身第一次成为可以系统下注的变量。
这一幕的本质是:机器开始替人判断”什么是好特征”;人退后一步,去问”什么是好问题、什么是好数据”。
AI 3.0:通用模型时代,智能开始涌现
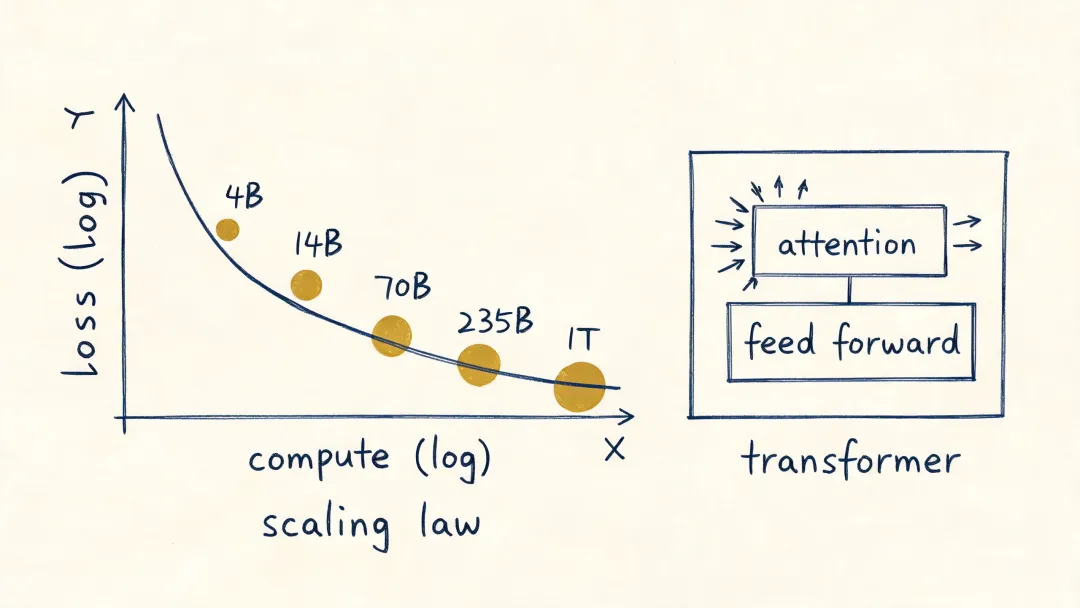
2020 年,GPT-3 [8] 登场。一个 175B 参数的 Transformer,无需任务专属微调,仅靠”上下文里给几个例子”,就能跨任务工作。模型从”为某个任务训一个”变成了”训一个,解决一类任务”。
与其说 AI 3.0 是 LLM 时代,不如说这是一个终于学会同时 scale 数据和算力的时代。LLM 只是最先爆发出来的那一支;SAM 之于视觉、Whisper 之于语音,都是同一范式在不同模态上的复刻:One Model for Many Tasks。
人继续退后一步。Transformer [9] 成为主流之后,架构主干趋于收敛;不再需要为每个任务从零设计一套模型,也不再需要为每个窄任务构建一个封闭数据集。通用语料、后训练、偏好数据、工具调用,开始成为新的核心变量。
严格说,Transformer 不是”没有先验”,而是固定的模态先验更弱。CNN 的局部性、RNN 的递推性,被一种更通用、更易并行、更适合大规模集群训练的 attention 算子替代。人类先验没有被清零,但它退到了更底层、更稀薄的位置。
人剩下的工作,是提出意图、定义价值观、设计评测、搭建工具。基础模型怎么把能力练出来,这套方法已经越来越公开;真正的差异,正逐渐转向数据、后训练、系统工程和产品闭环。
数量级再上一个台阶:训练数据从百万样本推进到千亿到万亿 token;训练算力从 AlexNet 级别的约 10¹⁷ FLOPs,推进到 GPT-3 级别的 10²³ FLOPs,并在后续 frontier runs 中继续向 10²⁵–10²⁶ FLOPs 逼近 [14]。
2020 年 Kaplan 等人的 Scaling Laws for Neural Language Models [10] 是这一幕的方法论锚点。它第一次把模型大小、训练数据、所需算力之间的关系,拟成一组干净的 power-law。后来 Chinchilla [13] 校正了数据和参数之间的最优配比,但”规模可预测”这件事本身没有变。
从那以后,前沿模型训练不再只是经验赌博,而更像在一条曲线上下注:多大模型、多大数据、多少算力,第一次有了可计算、可外推、可比较的分配逻辑。
这一幕的关键不是单卡变快了,而是算力的部署尺度变大了:从单卡到多卡,从多卡到集群,从集群到跨机房互联。
NVIDIA 的产品演化也沿着同一条线索展开 [15]:先是把单芯片里的计算密度做高,再把封装、HBM、节点内互联做强,最后继续往节点间网络和更大规模的数据中心 fabric 推。每一步都不是简单地”让一张卡更快”,而是在更大的物理尺度上,把更多计算单元组织成一台更大的机器。
模态选择上也有一个底层逻辑:为什么是语言先突破?因为语言的知识密度极高。人类几千年文明的抽象、推理、制度、经验、争论,都被压缩在文本里。单位 token 承载的抽象密度,远高于像素或音频帧。
3.0 内部还可以再切几级,按”人交出去多少”递推:
-
3.0:GPT-3,in-context learning 涌现,不再为每个任务训一个模型 -
3.1:InstructGPT / ChatGPT [11],RLHF 把”怎么和模型对话”从工程问题变成自然语言问题 -
3.2:o1 [12],test-time scaling 把推理也变成可花算力的一根轴 -
3.3:Agent,模型开始自己拆任务、调工具、看反馈、做纠错
这个划分有漏洞,尤其 3.2 和 3.3 在产品层面仍在交叠演化。但作为”人继续退后一步”的轴线,已经足够清晰。
人类先验、计算、数据:三条非线性的曲线
把三幕拉成一张表:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这张表里的数字都是代表性数量级,不是 census。真正重要的不是某个数精确到几位,而是三条曲线的相对方向:人类先验在变轻,计算尺度在变大,数据矿脉在迁移。
模型先验为什么能一路减下去?不是因为通用结构本身更聪明,而是因为结构和算力都只是手段,learn from data 才是目的。
评估一个结构创新有没有机会进入主流,看两件事:它能不能让算力进一步 scale,它能不能再去掉一部分人类先验。
CNN 让 convolution 在 GPU 上高效运行,同时去掉了 SIFT 那种手工尺度先验;Transformer 让 attention 在集群上高效运行,同时去掉了 RNN 的递推先验。两个判据它们都满足。新结构如果两个判据都不满足,再”优雅”也只是局部改良,很难带来浪潮。
但结构和算力的合奏只是一半。每一次大浪潮真正的源头,都是新的”数据矿藏”被接上了训练管线:AlexNet 之于 ImageNet,GPT-3 之于大规模互联网文本。
结构的演进、算力的扩展、新数据矿藏的发现,三者同时到位,浪潮才会出现。其中任意一个滞后,都只是隐性积累。
AI 的飞跃从来不是线性的,而是某一条线突然找到了新的指数维度。
代际分工,而非取代
这里得补一句,不然这篇容易写得太单边。
每一代 AI 兴起时,都会听到相似的辩护:新方法不可解释、不可控、黑盒。但新一代出现,不等于老一代立刻被推下历史舞台。很多领域里,老技术至今仍在运行,不是因为它强过新方法,而是因为它最适合那个场景。
举两个例子。
在不少量化金融工作里,因子工程、统计学习和深度模型仍然是更常见的生产组合。LLM 更多进入投研辅助、信息抽取、代码生成、报告生成,而不是直接替代 alpha 建模的主干。
原因不是 LLM 不强,而是金融时间序列的 SNR 极低,分布漂移长期存在,回测和实盘之间的 gap 远大于视觉 / NLP,可解释性还涉及合规和风控审查。在这套场景里,2.0 时代的方法论仍是更合身的工具组合:因子工程保留了 1.0 时代的人类先验,深度学习叠加了 2.0 时代的表示学习,而 3.0 的通用范式短期内还没找到最自然的入口。
工业检测和部分医疗影像系统里,也仍然保留大量传统视觉模块。原因同样很朴素:光源、相机、工件、流程高度固定;可重复、可解释、低延迟、低算力依赖,是比”模型是否最新”更硬的约束。对于一个成熟产线来说,可维护性有时比上限能力更重要。
可解释性研究的另一面意义也常被忽略:每一代技术的可解释性研究,都在帮助下一代理解上一代留下的归纳偏好。
CNN 可视化、saliency map、CAM、Grad-CAM,让我们理解网络在图像中看到了什么;树模型、线性模型和概率图模型留下的那套解释语言,也被后来的 reward modeling、preference modeling、model editing 重新吸收。所谓”老技术”,常常不是消失了,而是变成了下一代技术的直觉、约束和工具箱。
一代技术真正”过时”的时刻,不是新一代刚出现的时候,而是它最擅长的场景被新一代以更低成本覆盖的时候。在那之前,老和新只是分工不同。
计算托举人
回到主旨:AI 进步不是计算取代人,而是计算托举人。
每一幕里,人和机器的分工变化,其实都在指向同一件事——人正在从”替机器思考”的位置上,一寸一寸走出来。
1.0 时代,人做特征,把世界翻译给机器。
2.0 时代,人做任务定义,把已知问题翻译成可学习的形式。
3.0 时代,人不再只是翻译已知问题,而是借机器之力,去发现尚未被定义的问题。
这是一次思想的解放。人在前两幕的工作,本质上都是在替机器消化存量——”我知道这件事怎么做,让我教会机器”。3.0 把这一步交了出去:通用模型自己会消化存量,人于是被释放出来,可以去问那些原本没人问的问题。
能用 AI 把哪些原本做不到的事做成?哪些原本不存在的工作流,可以重新设计?哪些被资源门槛挡在门外的方向,现在突然有了入场券?
当存量问题的解可以被 AI 批量生成,最贵的资源就不再是答案,而是认知与想象力。
人原本就是一个能自主迭代、有超长记忆、能灵活融合多模态信号的智能体。只是在过去的三幕里,这些能力被大量消耗在重复抽象的劳作上,无暇朝更长、更深的尺度展开。
当代 AI 的演进方向,几乎是在沿着”人本来的样子”逐步逼近:长上下文之于长期记忆,agent 之于自主迭代,多模态模型之于跨模态信号融合。
模型能力线和人的原生能力线靠近的那一刻,人才真正被托举到一个不必再为机器思考、可以全力去想象世界的位置。
3.0 不是让人变得多余的时代,是让人重新发现自身有多大空间的时代。这一代生产力的爆发,不会发生在已知问题的更优解里,而会发生在那些以前没人敢去想、现在突然可以去做的方向上。
Whatever you can imagine, build it. AI is barely starting.
几点声明
以上分析基于 2022 年所做的内部研究报告与之后几年的个人观察,是从人类先验、计算、数据三条线索做的一阶推演;具体数字以引用资料为准 仅代表作者在 2026-05 时的观点,后续可能不定期更新 均属作者个人观点,不代表所在机构立场
引用与参考
-
[1] Sutton, R. (2019). The Bitter Lesson. http://www.incompleteideas.net/IncIdeas/BitterLesson.html -
[2] Lowe, D. G. (2004). Distinctive Image Features from Scale-Invariant Keypoints. IJCV. -
[3] Dalal, N., & Triggs, B. (2005). Histograms of Oriented Gradients for Human Detection. CVPR. -
[4] Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5–32. -
[5] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. NeurIPS. -
[6] Mikolov, T., et al. (2013). Efficient Estimation of Word Representations in Vector Space. -
[7] Deng, J., et al. (2009). ImageNet: A Large-Scale Hierarchical Image Database. CVPR. -
[8] Brown, T., et al. (2020). Language Models are Few-Shot Learners. NeurIPS. -
[9] Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS. -
[10] Kaplan, J., et al. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361. -
[11] Ouyang, L., et al. (2022). Training Language Models to Follow Instructions with Human Feedback. NeurIPS. -
[12] OpenAI (2024). Learning to Reason with LLMs. -
[13] Hoffmann, J., et al. (2022). Training Compute-Optimal Large Language Models (Chinchilla). -
[14] Sevilla, J., et al. / Epoch AI. Training compute trend and model compute estimates. -
[15] NVIDIA. NVLink / NVSwitch / GB200 NVL72 / Spectrum-X product materials. -
上一篇:墨水里的胖头鱼,《智矿:高智力密度数据之争》, 2026-04.