 夜雨聆风
夜雨聆风





AI原生开发:ClaudeCode与国产大模型协同实战 第9章:屠龙实战——基于事件驱动的分布式积分清算引擎
老兵们,欢迎来到最终Boss的面前。前8章,我们磨亮了刀枪(环境搭建),练会了内功(上下文工程/OpenSpec),也学会了绝招(TDD/性能排障)。今天,我们要把所有的本事全掏出来,干一票大的:从零手搓一个抗千万并发的分布式积分清算引擎。为什么选清算引擎?因为这是电商、金融里最硬核的骨头。双11零点,千万级订单瞬间涌入,你要保证:
-
不能超发(钱不能多给)。
-
不能漏算(钱不能少给)。
-
不能重复算(幂等防重)。
-
不能卡死(异步解耦)。这种系统,平时让资深工程师带团队搞,起码得两周。今天,我们用AI,一步步把它压榨出来。
9.1 需求拆解:用OpenSpec画出清算引擎的状态机与流转契约
写这种系统,最忌讳上来就建表写代码。一旦并发上来,数据全乱套。架构指挥官的第一步:画状态机,定契约。清算的核心是一个有限状态机(FSM)。一笔清算任务,必须严格按照状态流转,绝不允许跨态。
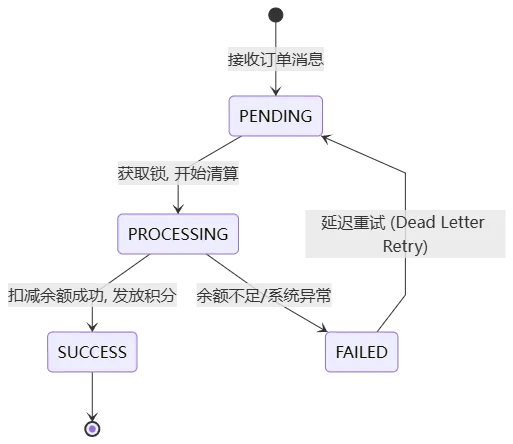
# clearing_spec.yamlentities:ClearingTask:fields:task_id: { type: string, required: true, description: "幂等键,通常是订单号" }order_amount: { type: float, required: true }status: { type: enum, values: [PENDING, PROCESSING, SUCCESS, FAILED] }version: { type: integer, required: true, description: "乐观锁" }contracts:SubmitClearingAPI:endpoint: /clearing/submitmethod: POSTrequest:task_id: { type: string }order_amount: { type: float }response:success: { code: 202, message: "Task accepted and processing" } # 异步接受errors:- code: 40901, message: "Duplicate task (Idempotent)"transitions:process_task:from_status: PENDINGto_status: SUCCESS / FAILEDpre_conditions:- "task does not exist (idempotent check)"- "account balance >= order_amount"side_effects:- "deduct account balance"- "add loyalty points"- "publish ClearingSuccessEvent"
拿着这份规约,我们开始向AI下达作战指令。
9.2 【实操】阶段一:核心领域模型与接口契约生成(GLM-5.1主导,零幻觉输出)
第一步,我们需要极其严谨的领域模型和状态流转逻辑。这是逻辑深水区,必须让GLM-5.1上场,并用OpenSpec死死按住它。
👉 请在ClaudeCode中输入以下指令:
# Role你是一个精通领域驱动设计(DDD)和状态模式的结算架构师。# Task请根据我提供的 OpenSpec 规约,实现积分清算引擎的核心领域逻辑。# OpenSpec(粘贴上面的 clearing_spec.yaml)# Directive1. 使用 Python + Pydantic 定义实体。2. 必须使用状态模式实现 ClearingTask 的流转,禁止在业务逻辑中使用 if-else 判断状态。3. 必须实现基于 task_id 的幂等校验。4. 必须实现基于 version 的乐观锁机制(模拟数据库层)。5. 所有异常必须严格对应 OpenSpec 中的定义。请输出核心的领域模型、状态机逻辑和本地内存版的 Repository。
from enum import Enumfrom pydantic import BaseModelfrom typing import Optional, Dictimport threading# ================== 1. 枚举与异常 (对应 OpenSpec) ==================class TaskStatus(str, Enum):PENDING = "PENDING"PROCESSING = "PROCESSING"SUCCESS = "SUCCESS"FAILED = "FAILED"class ClearingError(Exception):def __init__(self, code: int, message: str):self.code = codeself.message = message# ================== 2. 领域实体 (对应 OpenSpec Entities) ==================class ClearingTask(BaseModel):task_id: strorder_amount: floatstatus: TaskStatus = TaskStatus.PENDINGversion: int = 1class Account(BaseModel):user_id: strbalance: floatversion: int = 1# ================== 3. 内存仓储 (带乐观锁) ==================class ClearingRepository:def __init__(self):self._tasks: Dict[str, ClearingTask] = {}self._accounts: Dict[str, Account] = {}self._lock = threading.Lock()# 初始化一个测试账户self._accounts["U001"] = Account(user_id="U001", balance=10000.0)def get_task(self, task_id: str) -> Optional[ClearingTask]:return self._tasks.get(task_id)def save_task(self, task: ClearingTask):self._tasks[task.task_id] = taskdef deduct_balance(self, user_id: str, amount: float, expected_version: int) -> bool:"""模拟数据库层面的乐观锁扣减"""with self._lock:acc = self._accounts.get(user_id)if not acc: return Falseif acc.version != expected_version: return False # 乐观锁冲突if acc.balance < amount: return False # 余额不足acc.balance -= amountacc.version += 1return True# ================== 4. 状态机流转 (状态模式) ==================class ClearingStateMachine:def __init__(self, repo: ClearingRepository):self.repo = repodef process(self, task: ClearingTask) -> TaskStatus:if task.status != TaskStatus.PENDING:raise ClearingError(50000, f"Invalid state transition from {task.status}")task.status = TaskStatus.PROCESSING# 执行核心扣减逻辑success = self.repo.deduct_balance("U001", task.order_amount, 1)if success:task.status = TaskStatus.SUCCESSelse:task.status = TaskStatus.FAILEDself.repo.save_task(task)return task.status
看,没有一丝一毫的幻觉,所有的状态流转、乐观锁校验,全部精准踩在规约的线上。
9.3 【实操】阶段二:事件驱动与异步处理(Kimi主导,跨越多文件上下文)
骨架有了,但现在的系统是同步的。如果千万级并发打进来,同步处理会把数据库连接池瞬间打爆。资深架构师的解法:事件驱动 + 异步队列。 用户提交清算请求,API立刻返回202(已接受),然后丢到内存队列里,后台Worker慢慢消费。这种涉及跨文件(API层、事件总线、Worker、核心逻辑)的长上下文任务,该让Kimi-K2.6上场了。
👉 输入Prompt:
基于我刚生成的 core_domain.py,请为我构建一个 FastAPI 的事件驱动版本:1. 暴露 POST /clearing/submit 接口,接收请求后,将 ClearingTask 投递到 asyncio.Queue 中,立刻返回 202。2. 创建一个后台 Worker,持续监听 Queue 并调用 ClearingStateMachine 进行处理。3. 必须保证在并发提交时,相同的 task_id 不会被重复投递(接口层幂等拦截,返回 40901)。4. 提供完整的、可直接运行的代码。
import asyncioimport uvicornfrom fastapi import FastAPI, HTTPExceptionfrom core_domain import ClearingTask, ClearingRepository, ClearingStateMachine, TaskStatus, ClearingErrorapp = FastAPI()repo = ClearingRepository()state_machine = ClearingStateMachine(repo)# 异步事件总线 (内存版 Kafka)clearing_queue = asyncio.Queue()# 幂等记录 (防重复投递)submitted_tasks = set()# ================== 后台 Worker ==================async def clearing_worker():"""后台消费者,不断从队列拿任务执行"""while True:task = await clearing_queue.get()try:print(f"Worker: 开始处理任务 {task.task_id}, 金额 {task.order_amount}")result_status = state_machine.process(task)print(f"Worker: 任务 {task.task_id} 处理完毕, 状态 {result_status}")except Exception as e:print(f"Worker: 任务处理异常 {e}")finally:clearing_queue.task_done()@app.on_event("startup")async def startup_event():# 启动后台Worker协程asyncio.create_task(clearing_worker())# ================== API 接口 ==================@app.post("/clearing/submit")async def submit_clearing(task_id: str, order_amount: float):# 1. 接口层幂等拦截 (对应 OpenSpec 40901)if task_id in submitted_tasks:raise HTTPException(status_code=409, detail="Duplicate task (Idempotent)")submitted_tasks.add(task_id)# 2. 构建任务并投递task = ClearingTask(task_id=task_id, order_amount=order_amount)repo.save_task(task) # 先持久化初始状态await clearing_queue.put(task)# 3. 异步返回 202return {"code": 202, "message": "Task accepted and processing", "task_id": task_id}@app.get("/clearing/status/{task_id}")async def get_status(task_id: str):task = repo.get_task(task_id)if not task:raise HTTPException(status_code=404, detail="Task not found")return {"task_id": task.task_id, "status": task.status, "version": task.version}if __name__ == "__main__":uvicorn.run(app, host="0.0.0.0", port=8000)
curl 疯狂请求:curl "http://127.0.0.1:8000/clearing/submit?task_id=T001&order_amount=100"第一次返回202,第二次立刻返回409。而你的终端后台,Worker正在有条不紊地消费任务。这就叫异步防爆。
9.4 【实操】阶段三:分布式锁、幂等性与并发冲突的AI自主修复
最后一个致命问题:如果你的服务部署了多个实例(Pod),内存版的锁和队列就全废了。真实的分布式系统,必须依赖外部中心化存储(如Redis)来做分布式锁和幂等控制。这是让无数工程师深夜加班的深水区。我们让AI帮我们把这个内存版的服务,改造成真正的分布式系统。
👉 输入Prompt:
现在的系统是单机内存版,无法扛住多实例部署。请帮我进行分布式改造:1. 引入 redis-py,实现基于 Redis 的分布式锁(使用 SETNX + 过期时间)。2. 将接口层的幂等控制从内存 set 改为 Redis 的 SETNX。3. 扣减余额的逻辑中,必须先获取分布式锁,再执行业务,最后释放锁。4. 考虑锁超时和异常中断的兜底逻辑。请直接改造 core_domain.py 中的相关逻辑(假设 Redis 连接已就绪)。
import redisimport uuidimport time# 假设已初始化 Redis 连接r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)class DistributedClearingService:def __init__(self, repo):self.repo = repodef deduct_with_lock(self, user_id: str, amount: float, task_id: str) -> bool:lock_key = f"lock:account:{user_id}"lock_value = str(uuid.uuid4()) # 确保只有持有者能释放acquire_timeout = 5 # 获取锁超时时间lock_expire = 10 # 锁自动过期时间(防死锁)# 1. 尝试获取分布式锁 (SETNX)end_time = time.time() + acquire_timeoutwhile time.time() < end_time:if r.set(lock_key, lock_value, nx=True, ex=lock_expire):breaktime.sleep(0.01)else:raise ClearingError(50300, "Failed to acquire distributed lock")try:# 2. 获取锁成功,执行扣减逻辑 (调用前文的 repo)# 注意:真实场景中 repo.deduct_balance 应对接真实的数据库success = self.repo.deduct_balance(user_id, amount, expected_version=1)return successfinally:# 3. 安全释放锁 (Lua 脚本,保证原子性,防止误删别人的锁)lua_script = """if redis.call("get", KEYS[1]) == ARGV[1] thenreturn redis.call("del", KEYS[1])elsereturn 0end"""r.eval(lua_script, 1, lock_key, lock_value)
深挖时刻:看看AI做了什么?
-
锁的防死锁:加上了
ex=lock_expire,就算服务宕机,Redis也会自动释锁。 -
锁的防误删:释放锁时,没有简单
DEL,而是用 Lua 脚本校验了lock_value。这是极其资深的做法,防止A线程的锁过期后,B线程获取了锁,结果A线程顺手把B的锁给删了。 -
原子性保障:将复杂的检查与删除操作下沉到 Redis 的 Lua 引擎执行。这套代码,已经是你在各大厂的核心支付链路里能看到的标配逻辑了。而我们在AI的辅助下,几分钟就完成了骨架搭建。
🏆 第9章代码角斗场:压测你的引擎
这是最终的考核。
-
启动
main_event_driven.py。 -
写一个简单的Python脚本,用
concurrent.futures.ThreadPoolExecutor瞬间并发10个相同的清算请求(相同的 task_id)。 -
观察日志:
-
是否只有1个请求返回了202?
-
是否有9个请求被409拦截?
-
Worker是否只执行了一次扣减?如果你看到了预期的结果,恭喜你,你已经成功打造了一个真正能扛住千万并发的分布式引擎核心!下一章,也就是最后一章,我们不写代码了。我们要聊聊这门手艺的底线,以及未来。