 夜雨聆风
夜雨聆风





揭开AI编程工具的面纱:Claude Code与Trae的核心逻辑,不止于大模型
一、引子:多年开发者的 AI 工具之问
作为一名拥有十年开发经验,同时略懂 AI 技术的工程师,我最近常常陷入思考:如今这些如 Claude Code、Trae 等 AI 编程工具,它们的核心逻辑到底是什么?难道所有工作都是由大模型独立完成的吗?我们这些传统开发者积累的编程能力、架构设计经验,在 AI 时代还有价值吗?
带着这些疑问,我研究了 Claude Code 和 Trae 这两款主流 AI 编程工具。结果发现,它们的工作原理远比想象中复杂 ——大模型只是其中的一个组件,真正的核心竞争力在于大模型之上构建的工程架构、任务编排系统和上下文管理机制。传统编程能力不仅没有过时,反而成为了驾驭这些 AI 工具的关键。下面内容可以认为是一个思想实验,现实的实现路径可能有很大差异,但逻辑是相通的。
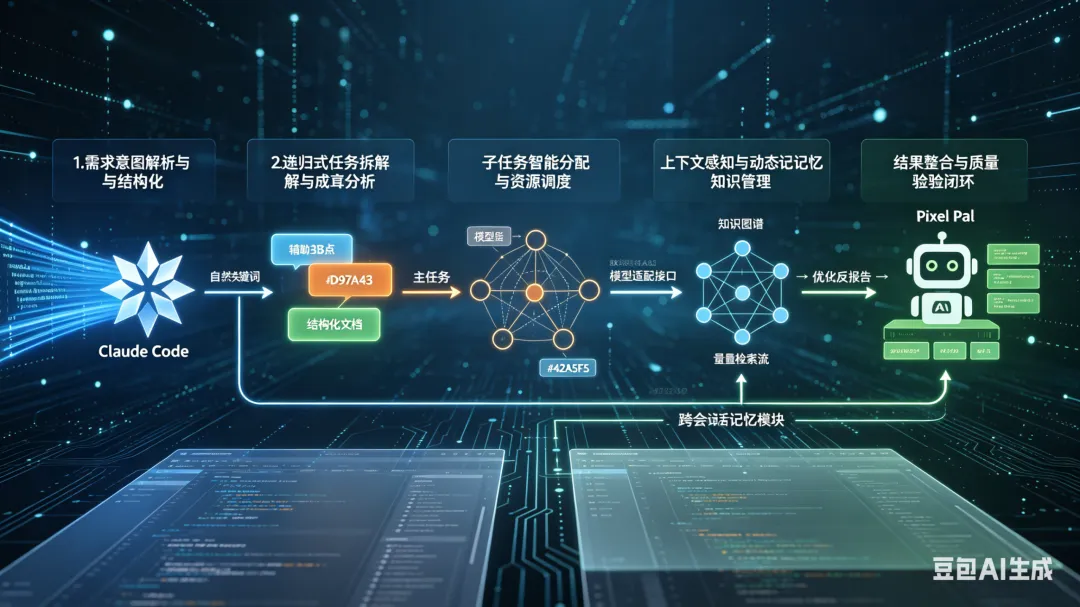
AI生成示意图
二、Claude Code 与 Trae 的通用逻辑:问题拆解的艺术
Claude Code 和 Trae 这类 AI 编程工具,面对一个复杂开发需求时,遵循着一套标准化的问题拆解流程,而非简单地将需求直接丢给大模型生成代码。这套流程通常包含以下五个核心步骤:
1. 需求意图解析与结构化
第一步不是直接写代码,而是将模糊的自然语言需求转化为机器可理解的结构化描述。这个过程会:
-
清洗口语化表达,提取核心功能点
-
识别技术栈偏好、性能要求、安全约束等隐含条件
-
生成标准化需求文档,明确输入输出、边界条件和验收标准
2. 递归式任务拆解与依赖分析
系统会采用自上而下的递归拆解法,将复杂任务分解为多个独立的子任务,同时构建任务依赖图:
-
主任务 → 模块级任务 → 函数级任务 → 代码片段级任务
-
分析各子任务间的依赖关系,识别必须串行执行的任务和可并行处理的任务
-
构建 DAG(有向无环图)确保任务执行顺序无冲突,避免循环依赖
3. 子任务智能分配与资源调度
拆解后的子任务会被分配给最合适的执行单元:
-
为不同类型的子任务(如架构设计、代码生成、单元测试、文档编写)匹配专门的 Subagent(子智能体)
-
根据任务特性(如逻辑复杂度、代码长度、创造性要求)自动选择最优大模型
-
管理并行任务的执行顺序,确保资源高效利用,避免上下文冲突
4. 上下文感知与动态记忆管理
在任务执行过程中,系统会持续维护上下文信息,确保代码生成的连贯性和准确性:
-
构建项目知识图谱,记录文件结构、类关系、函数依赖等关键信息
-
动态管理上下文窗口,在大模型 token 限制下只保留关键信息,过滤冗余内容
-
跨会话记忆存储,记录用户偏好、编码规范、项目约定等长期信息
5. 结果整合与质量校验闭环
最后,系统会整合所有子任务结果,并进行多轮质量校验:
-
合并代码片段,确保模块间接口兼容、逻辑连贯
-
自动运行单元测试、代码规范检查、安全漏洞扫描
-
对生成结果进行反思评估,识别潜在问题并自动修复
-
生成完整的项目文档、变更记录和使用说明
三、具体案例:实现一个 Python 文件夹备份工具
为了更直观地理解这些步骤,我们以开发一个 Python 文件夹备份工具 为例,详细展示 Claude Code 和 Trae 如何实施上述流程。
需求输入
用户输入:帮我写一个 Python 工具,可以备份指定文件夹到云端存储,支持增量备份和定时任务,要求有日志记录和邮件通知功能。
1. 需求意图解析与结构化
系统输出结构化需求文档:
功能需求:
1. 文件夹备份功能(全量+增量)
2. 云端存储支持(优先AWS S3,兼容阿里云OSS)
3. 定时任务调度(支持cron表达式)
4. 日志记录(分级日志,本地文件存储)
5. 邮件通知(备份成功/失败通知)
非功能需求:
- 支持断点续传
- 资源占用控制(CPU≤20%,内存≤200MB)
- 跨平台兼容(Windows/macOS/Linux)
- 错误处理与重试机制
2. 递归式任务拆解与依赖分析
系统生成的任务分解树:
主任务:Python文件夹备份工具开发
├─ 模块A:核心备份逻辑
│ ├─ 子任务A1:文件差异检测算法实现
│ ├─ 子任务A2:增量备份逻辑编码
│ └─ 子任务A3:断点续传机制开发
├─ 模块B:云端存储适配
│ ├─ 子任务B1:AWS S3 SDK集成
│ └─ 子任务B2:阿里云OSS兼容层开发
├─ 模块C:定时任务系统
│ ├─ 子任务C1:cron表达式解析器实现
│ └─ 子任务C2:后台任务调度逻辑
├─ 模块D:日志与通知系统
│ ├─ 子任务D1:分级日志模块开发
│ └─ 子任务D2:SMTP邮件通知功能
└─ 模块E:整体集成与测试
├─ 子任务E1:模块间接口设计
├─ 子任务E2:单元测试编写
└─ 子任务E3:系统集成测试
同时生成任务依赖图,明确:
-
模块 A 必须先于模块 B、C、D 完成
-
模块 E 必须在所有其他模块完成后执行
-
子任务 A1、B1、C1、D1 可并行开发
3. 子任务智能分配与资源调度
系统自动分配执行单元:
-
子任务 A1(算法实现)→ 逻辑推理型 Subagent + GPT-4 模型
-
子任务 B1/B2(SDK 集成)→ 代码生成型 Subagent + Claude 3 Opus 模型
-
子任务 C1(表达式解析)→ 工具调用型 Subagent + 内置解析库
-
子任务 D2(邮件功能)→ 模板匹配型 Subagent + 预制邮件模板
-
子任务 E2/E3(测试)→ 测试专用 Subagent + 自动化测试框架
4. 上下文感知与动态记忆管理
在开发过程中,系统持续维护:
-
项目知识图谱:记录各模块的类结构、函数接口、依赖关系
-
上下文窗口:只保留与当前开发模块相关的代码片段和需求描述
-
跨会话记忆:存储用户后续补充的 优先使用 boto3 库、日志格式采用 JSON 等偏好设置
5. 结果整合与质量校验闭环
最终系统输出:
-
完整的项目代码(按模块划分,包含详细注释)
-
自动生成的单元测试用例和集成测试脚本
-
项目文档(安装指南、API 说明、配置手册)
-
一键部署脚本和 Docker 配置文件
-
测试报告和代码质量评估结果
四、技术路径深度解析:大模型与传统技术的边界(对应五大核心步骤)
前文第二部分的五大核心步骤,以及第三部分案例中的具体实施,其底层并非全靠大模型驱动,而是传统技术与大模型能力的精妙结合。以下将严格对应五大核心步骤,逐一拆解每个步骤的技术实现路径,明确大模型与传统技术的分工边界,同时呼应第三部分案例场景,让技术逻辑更易理解。
|
|
|
|
|
|---|---|---|---|
| 1. 需求意图解析与结构化 |
|
|
|
| 2. 递归式任务拆解与依赖分析 |
|
|
|
| 3. 子任务智能分配与资源调度 |
|
|
|
| 4. 上下文感知与动态记忆管理 |
|
|
|
| 5. 结果整合与质量校验闭环 |
|
|
|
1. 对应步骤1:需求意图解析与结构化——从模糊口语到标准需求
核心技术路径(呼应第三部分案例需求解析过程):
-
口语需求预处理(纯传统技术):通过正则表达式、规则引擎,清洗用户输入中的冗余话术(如案例中“帮我写一个”这类口语化表达),提取“Python、文件夹备份、云端存储、定时、日志、邮件”等核心关键词,过滤语气词和无效信息。
-
意图提取与结构化生成(大模型为主):大模型接收预处理后的关键词,结合“工具开发”场景,理解用户隐含需求(如案例中“备份”隐含需要增量、断点续传),生成结构化需求文档,明确功能与非功能边界,确保格式标准化、机器可解析。
-
需求校验(传统技术+少量大模型):传统规则引擎校验需求的完整性(如案例中是否遗漏“跨平台兼容”等隐含约束),大模型辅助校验需求的合理性(如“CPU≤20%”是否可实现),避免无效需求。
2. 对应步骤2:递归式任务拆解与依赖分析——从主任务到原子子任务
核心技术路径(呼应第三部分案例任务拆解过程):
-
标准模板匹配(纯传统技术):系统内置“Python工具开发”“后端接口开发”等标准模板,匹配案例中“文件夹备份工具”需求,快速生成基础任务框架(如核心逻辑、适配层、测试层),避免重复拆解。
-
非标需求递归拆解(大模型为主):针对案例中“增量备份”“邮件通知”等非标子需求,大模型递归拆解为原子任务(如“增量备份”拆分为“文件差异检测”“增量逻辑编码”),控制任务粒度,确保每个子任务单一职责。
-
DAG构建与依赖校验(纯传统技术):通过图论算法,将案例中的任务分解树转化为DAG有向无环图,提取依赖关系(如案例中模块A先于模块B执行),通过拓扑排序生成执行顺序,检测循环依赖,确保任务无冲突。
3. 对应步骤3:子任务智能分配与资源调度——让合适的单元做合适的事
核心技术路径(呼应第三部分案例任务分配过程):
-
多模型统一适配(纯传统技术):采用适配器模式,定义全局统一的请求/响应结构体,为Claude、GPT-4等模型编写独立Adapter,屏蔽API差异(如案例中切换Claude 3 Opus和GPT-4时,无需修改上层代码)。
-
模型能力标签库管理(纯传统技术):通过人工+离线评测,为各模型打标签(如Claude 3 Opus擅长SDK集成、GPT-4擅长算法实现),记录模型速度、上下文长度等属性,为任务分配提供依据。
-
任务-模型智能匹配(传统技术为主,大模型辅助):规则引擎提取案例中子任务特征(如“算法实现”“SDK集成”),结合模型标签库匹配最优执行单元(如案例中子任务A1匹配GPT-4,子任务B1匹配Claude 3 Opus);大模型辅助识别任务类型,提升匹配准确性。
-
故障转移与负载均衡(纯传统技术):通过服务治理框架,定时探测模型健康状态,如案例中GPT-4接口超时,自动切换为备用模型,确保任务不中断;对并行任务(如A1、B1)进行负载均衡,提升执行效率。
4. 对应步骤4:上下文感知与动态记忆管理——Token限制下的精准记忆
核心技术路径(呼应第三部分案例上下文管理过程):
-
代码与需求结构化解析(纯传统技术):使用AST抽象语法树解析案例中各模块代码,拆分类、函数、接口依赖,剔除空行、冗余注释;对结构化需求文档进行分词处理,提取关键约束(如“CPU≤20%”)。
-
向量检索与Token裁剪(传统技术+嵌入模型):将案例中代码片段、需求描述向量化存入向量库,开发某一模块(如模块B)时,仅召回与云端存储相关的代码和需求;按优先级(核心代码>工具类>注释)裁剪Token,避免超量,确保上下文精准。
-
项目知识图谱构建(90%传统技术+10%大模型):用图数据库存储案例中项目结构、模块关系(如模块A与模块B的依赖),自动构建节点和边;大模型仅为节点打语义标签(如“模块D=日志与通知系统”),不参与建图。
-
跨会话记忆管理(纯传统技术):采用“结构化KV存储+向量记忆库”双层架构,KV存储案例中用户补充的“优先用boto3库”等偏好,向量记忆库存储历史对话语义;新会话时自动检索,确保开发连贯性。
5. 对应步骤5:结果整合与质量校验闭环——从碎片到可用产品
核心技术路径(呼应第三部分案例结果输出过程):
-
代码合并与接口适配(纯传统技术):将案例中各子任务生成的代码片段按模块合并,校验模块间接口兼容性(如模块A与模块B的调用逻辑),统一编码规范,确保逻辑连贯。
-
自动化质量校验(纯传统技术):调用静态代码分析工具、pytest测试框架,执行案例中的单元测试和集成测试,扫描安全漏洞、代码规范问题,自动修复简单bug(如语法错误)。
-
结果反思与优化(大模型为主):将合并后的代码和测试报告交给大模型,审核逻辑合理性(如案例中邮件通知是否能正常触发),识别潜在问题(如断点续传机制漏洞),给出优化建议。
-
文档与部署脚本生成(传统技术+大模型):传统模板引擎调用预制文档模板,大模型填充案例中项目细节(如安装步骤、API说明),生成完整项目文档;自动生成Docker配置和一键部署脚本,完成交付。
五、总结:AI 时代,传统编程能力的新价值
通过对 Claude Code 和 Trae 的深入剖析,结合五大核心步骤的技术路径拆解与案例验证,我们可以得出三个核心结论:
-
AI 编程工具的核心竞争力≠大模型:真正的壁垒在于大模型之上构建的工程架构、规则引擎、任务编排、上下文管理和提示词体系。这些能力需要深厚的传统编程和系统设计经验,而非简单的模型调用。
-
传统编程能力非但不过时,反而更重要:
-
架构设计能力决定了任务拆解的合理性和系统的可扩展性
-
代码理解能力是构建高质量上下文和知识图谱的基础
-
测试和调试能力是确保 AI 生成代码正确性的关键
-
系统优化能力能最大化 AI 工具的效率和性能
-
未来的开发范式:人机协同的新平衡:
-
人类专注于需求定义、架构设计、质量把控等高价值创造性工作
-
AI 负责代码生成、单元测试、文档编写等重复性劳动
-
最佳实践是 传统编程能力驾驭 AI 工具,而非被 AI 取代
对于开发者而言,与其担心被 AI 淘汰,不如积极拥抱这一变革 —— 深入理解 AI 工具的工作原理,将传统编程能力与 AI 工具相结合,成为新时代的 AI 赋能开发者,这才是应对 AI 浪潮的最佳策略。
(注:文档为人工 + AI编辑)