 夜雨聆风
夜雨聆风





AscendNPU-IR | 源码构建与算子上板实操
上篇综述了基于MLIR的AscendNPU-IR分层架构与全链路优化能力。本文聚焦落地实操,带你完成环境搭建、源码编译,并以向量加法算子为例,完整跑通IR编译→上板执行全链路。
为什么要单独构建AscendNPU-IR
CANN提供的标准算子库可直接使用,但AscendNPU-IR开放的是编译中间层。当需要自定义算子融合策略、精细调控片上内存布局或扩展新方言时,需直接操作IR层。
截至2026年4月,该项目在GitCode上获得74位贡献者参与共建,累计提交超过1.17K次,C++与MLIR代码占比分别约为58.78%与39.15%。
依赖环境准备
AscendNPU-IR的构建依赖包括编译工具链、源码三方库与CANN运行环境。
编译工具链:
-
CMake ≥ 3.28 -
Ninja ≥ 1.12.0 -
Clang ≥ 10 与 LLD ≥ 10(推荐LLVM LLD以提升链接速度)
源码获取与子模块初始化:
git clone https://gitcode.com/Ascend/ascendnpu-ir.gitcd ascendnpu-irgit submodule update --init --recursiveCANN安装(连接昇腾硬件):
端到端运行依赖CANN环境。从昇腾社区下载与硬件对应的toolkit包及ops包。以x86系统A3环境为例:
chmod +x Ascend-cann_{version}_linux-x86_64.runchmod +x Ascend-cann-A3-ops_{version}_linux-x86_64.run./Ascend-cann_{version}_linux-x86_64.run --full./Ascend-cann-A3-ops_{version}_linux-x86_64.run --install安装后通过source命令配置环境变量(CANN 9.0及以上版本路径为cann/set_env.sh)。
若需启用端到端用例与BiShengIR模板库编译,需CANN 9.0.0及以上,并在构建脚本中加入对应编译选项。
源码构建
项目提供一键构建脚本,大幅简化编译流程。
首次构建
在项目根目录执行以下命令,首次构建必须启用--apply-patches以对三方子模块应用补丁,保证编译正常通过。
./build-tools/build.sh -o ./build --build-type Release --apply-patches脚本核心参数:
|
|
|
|---|---|
-o, --build PATH |
|
--build-type TYPE |
|
--apply-patches |
|
-r, --rebuild |
|
--build-test |
|
-t, --build-bishengir-template |
|
二次构建
若在已有构建目录基础上重新编译:
# 增量编译./build-tools/build.sh -o ./build --build-type Release# 清空重建(加-r参数可完全清理并重新配置)./build-tools/build.sh -o ./build --build-type Release -r构建完成后,bishengir-compile工具会自动加入系统路径,可直接全局调用。
算子编译与上板执行(VecAdd 实战)
昇腾AI处理器采用分离的Cube计算单元与Vector计算单元。AscendNPU-IR编译器可自动分析数据依赖,在核间插入同步指令,实现并行流水执行。向量加法属于Vector单元的基础操作。
-
编写MLIR描述文件
创建
add.mlir,用hivm.hir.vadd指令表达向量加法抽象。module { func.func @add(%arg0: memref<16xi16, #hivm.address_space<gm>>, %arg1: memref<16xi16, #hivm.address_space<gm>>, %arg2: memref<16xi16, #hivm.address_space<gm>>) attributes {hacc.entry, hacc.function_kind = #hacc.function_kind<DEVICE>} { %alloc = memref.alloc() : memref<16xi16, #hivm.address_space<ub>> hivm.hir.load ins(%arg0 : memref<16xi16, #hivm.address_space<gm>>) outs(%alloc : memref<16xi16, #hivm.address_space<ub>>) %alloc_0 = memref.alloc() : memref<16xi16, #hivm.address_space<ub>> hivm.hir.load ins(%arg1 : memref<16xi16, #hivm.address_space<gm>>) outs(%alloc_0 : memref<16xi16, #hivm.address_space<ub>>) %alloc_1 = memref.alloc() : memref<16xi16, #hivm.address_space<ub>> hivm.hir.vadd ins(%alloc, %alloc_0 : memref<16xi16, #hivm.address_space<ub>>, memref<16xi16, #hivm.address_space<ub>>) outs(%alloc_1 : memref<16xi16, #hivm.address_space<ub>>) hivm.hir.store ins(%alloc_1 : memref<16xi16, #hivm.address_space<ub>>) outs(%arg2 : memref<16xi16, #hivm.address_space<gm>>) return }}
-
编译生成NPU二进制
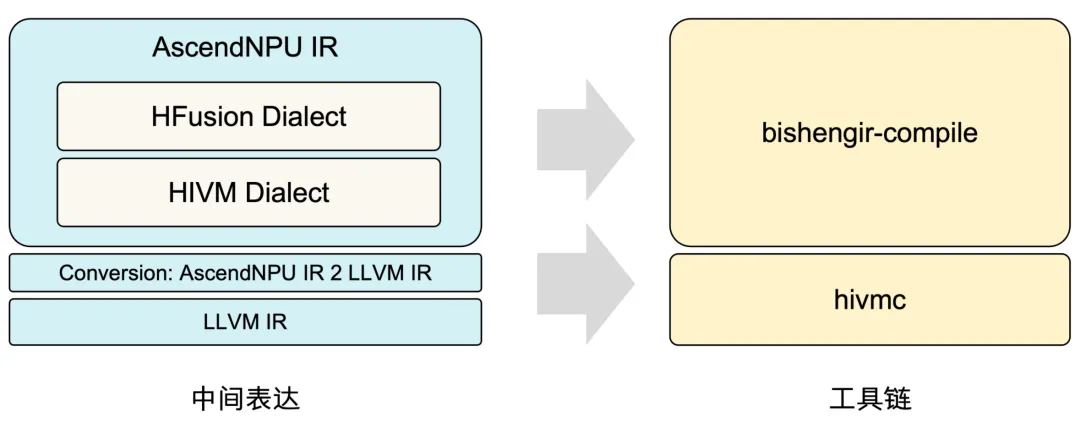
使用
bishengir-compile工具将IR编译为昇腾NPU可直接执行的二进制文件:bishengir-compile add.mlir -enable-hivm-compile -o kernel.o生成的
kernel.o即为算子二进制。
-
Runtime注册与执行
得到二进制后,需通过CANN Runtime接口将其注册到设备端并执行。以下C++代码展示核心流程:
// 读取二进制kernel文件char *readBinFile(constchar *fileName, uint32_t *fileSize){// ... 读取kernel.o内容到buffer}// 注册Binary Kernelvoid *registerBinaryKernel(constchar *filePath, char **buffer,constchar *stubFunc, constchar *kernelName){// ... 调用CANN Runtime接口加载算子}完整的
main.cpp还需包含设备内存分配、数据传输、launch kernel及结果校验。将这些代码与kernel.o一同编译链接,即可在昇腾NPU上执行向量加法。
编译器的自动优化
当模型中包含大量算子时,AscendNPU-IR会自动完成以下优化:
-
Mix Kernel融合:将连续的Vector与Cube计算单元算子拆分重组,在核间自动插入同步指令,通过CVPipeline实现并行流水执行,减少指令延迟。 -
自动内存规划:编译器自动推导片上内存(如Unified Buffer)空间,完成ND↔Fractal布局转换,并对访存进行自动对齐,避免手动管理导致的溢出或数据冲突。 -
自动同步:跨核协同场景下,编译器基于数据依赖图自动插入最优的 set/wait同步指令,提升多核并行效率。
这三层优化对开发者透明,只需关注算子逻辑表达。
总结
本文完整覆盖AscendNPU-IR依赖安装→源码构建→算子编译→上板执行全流程,是Triton IR转昇腾IR、TileLang等新编程模型使能昇腾硬件的技术基础。
后续文章将带来自定义编译优化Pass、HFusion到HIVM的转换等进阶内容。
参考链接
-
AscendNPU-IR官方项目:https://gitcode.com/Ascend/ascendnpu-ir -
AscendNPU-IR官方文档:https://ascendnpu-ir.gitcode.com -
AscendNPU-IR构建安装指南: https://ascendnpu-ir.gitcode.com/zh_cn/introduction/quick_start/installing_guide.html -
AscendNPU-IR编译与执行示例:https://ascendnpu-ir.gitcode.com/zh_cn/introduction/quick_start/examples.html

扫码添加编译小助手微信,
邀请您加入sig-AscendNPU-IR微信交流群