 夜雨聆风
夜雨聆风





Chemist Eye:自驱动实验室的 AI 安全卫士 —— 硬件、软件与实验
一、硬件架构:分布式多模态感知网络
1. RGB-D 安全监测站

计算单元
Jetson Orin Nano(搭载 Jetpack 5.1.3),提供边缘推理能力,支持本地运行 YOLOv8 和轻量级 VLM 模型,无需依赖云端;
感知单元
Intel RealSense 435i RGB-D 相机,同时采集彩色图像和深度数据,可精确计算人员与相机的三维距离,误差小于 2cm;
交互单元
两个 Amazon 有线扬声器,用于播放定制化语音警告(如 “您的生命至关重要,请始终佩戴 PPE”);
机械结构
可调节铝制支架,支持水平和垂直角度调整,可安装在实验室墙壁、天花板或实验台上方,覆盖无死角监控区域。
2. 红外热成像监测站
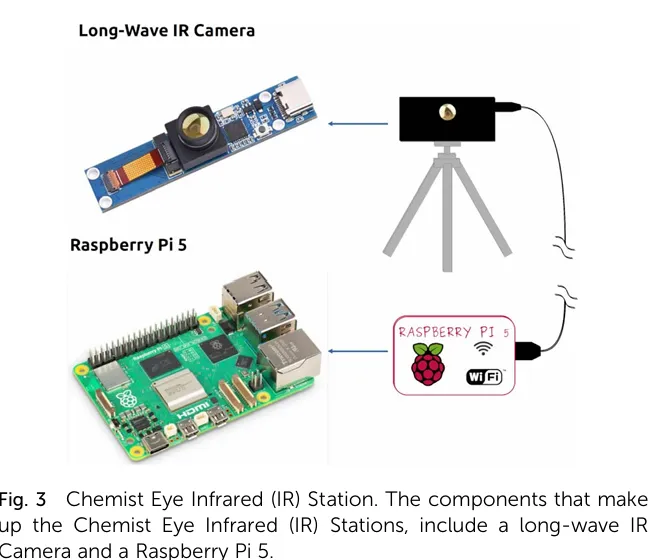
计算单元
Raspberry Pi 5(运行 Raspbian OS),低功耗、低成本,适合长期稳定运行;
感知单元
长波红外相机,测温范围 20℃-400℃,覆盖绝大多数有机化学反应的温度区间;
部署方式
三脚架或定制支架,可灵活移动和安装,甚至能放置在通风橱内部监测反应过程。
3. 网络与中央控制架构(Fig. 5)
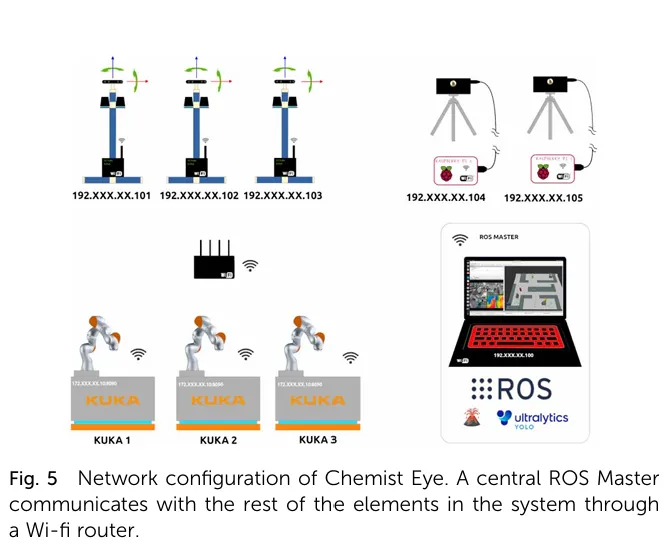
所有监测站和机器人均通过固定 IP 地址连接到实验室 Wi-Fi 网络;中央 PC 运行ROS Master 节,负责协调所有组件的通信、数据融合和指令下发;系统支持无缝集成所有 ROS 兼容的移动机器人,本文实验中使用了 3 台 KUKA KMR iiwa 移动机器人;数据传输延迟:红外数据约 300ms,RGB-D 数据约 100ms,满足实时监控需求。
二、软件架构:ROS+VLM 驱动的智能决策系统
1. 通信层:ROS 为核心的分布式总线
监测站节点:发布图像、深度、温度数据;
机器人节点:发布位置、状态信息,接收导航指令;
中央控制节点:订阅所有传感器数据,发布决策指令。
2. 感知层:YOLOv8 快速目标检测
输入:RGB-D 相机的彩色图像;
输出:人员边界框、17 个人体关键点、三维空间坐标;
性能:在 Jetson Orin Nano 上运行速度可达 30FPS,满足实时性要求。
3. 推理层:VLM 零样本语义理解
离线模型:LLaVA-7B、LLaVA-Phi3(完全本地运行,隐私性最佳);
在线模型:GPT-4o mini(响应速度更快,依赖互联网)。
PPE 检测提示
通过多轮提问和关键词匹配(WHITE、LAB COAT、COAT)判断人员是否穿着实验室外套;
事故检测提示
通过识别非站立姿势(LYING、KNEELING、SITTING 等)判断是否有人员摔倒或突发疾病。
4. 决策层:优先级驱动的响应机制
PPE 违规响应
冻结所有机器人→播放语音警告→10 分钟倒计时→Slack 通知管理人员;
人员事故响应
将人员标记为红色→Slack 紧急通知→VLM 规划机器人安全停靠点→清空救援通道;
火灾响应
红外相机检测异常高温→Slack 紧急通知→VLM 规划机器人远离火源→联动现有消防系统。
5. 可视化层:匿名化实时监控界面


使用匿名化的 “Meeples” 图标代表工作人员,不同颜色表示不同状态(灰色 = 正常,黄色 = PPE 违规,红色 = 事故);
显示机器人位置、导航路径和温度监测点,温度超过阈值时标记变为红色;
支持将地图截图嵌入 Slack 通知,让管理人员快速了解事故位置。
6. 隐私保护设计
三、实验设计:基于真实场景回放的安全验证

1. 数据集构建
NORMAL(400 张)
人员正常站立、行走或工作;
NOT_PPE(400 张)
人员未穿实验室外套;
PRONE(500 张)
人员模拟摔倒、跪地、爬行等事故姿势。
2. 六大核心实验验证
实验 1:PPE 合规检测准确率
目的:评估不同 VLM 模型和提示策略的 PPE 检测性能;
方法:使用 4 种不同的提示策略(Q1-Q4)测试 LLaVA-7B 和 LLaVA-Phi3;
结果:LLaVA-Phi3+Q4(多轮提问 + 关键词匹配)达到最高准确率 97.5%,平均响应时间 3.65 秒。
实验 2:人员事故检测准确率
目的:评估 VLM 的姿势识别能力;
方法:使用 6 种不同的提示策略(Q5-Q10)测试两种模型;
结果:LLaVA-Phi3+Q10(综合提问)准确率达 97%,在存在遮挡的情况下仍优于传统 YOLOv8-pose 关键点检测。
实验 3:PPE 违规自动响应
目的:验证系统的自动响应流程;
方法:模拟人员持续 10 分钟不穿实验室外套;
结果:系统 100% 准确执行了 “冻结机器人→语音警告→Slack 通知” 的完整流程。
实验 4:事故响应与机器人重定位
目的:评估 VLM 指导机器人移动到安全位置的能力;
方法:模拟人员摔倒,测试 3 种提示配置(无节点列表 / 完整节点列表 / 过滤后安全节点列表);
结果:使用过滤后安全节点列表时,平均成功率达 95%,机器人均能避开事故现场。
实验 5:火灾检测与机器人重定位
目的:验证火灾场景下的系统响应;
方法:通过红外相机模拟 55℃以上的异常高温;
结果:LLaVA-Phi3 在 3D 地图 + 过滤节点配置下成功率达 100%,红外数据传输延迟仅 300ms。
实验 6:复杂场景扩展评估
目的:对比离线 VLM、在线 VLM 和传统计算机视觉模型的性能;
结果:多人遮挡场景下,LLaVA-Phi3 事故检测准确率 90.33%,YOLOv8-pose 仅 80.5%;GPT-4o mini 响应时间仅 2.4 秒,成功率 95%,但依赖互联网连接;VLM 无需任何训练,部署时间从传统方法的数周缩短至数小时。
3. 实验结论
四、总结与展望
分布式多模态感知
融合 RGB-D 和红外技术,实现全方位安全监控;
VLM 零样本推理
通过结构化提示实现无需训练的安全语义理解;
机器人联动决策
主动控制机器人规避风险,而非仅仅报警;
隐私优先设计
本地推理 + 匿名化展示,完全符合数据保护法规。