 夜雨聆风
夜雨聆风





OmniDocBench:一个全面评估文档解析能力的基准测试
一、背景:文档解析为何难以评估?
随着数字化浪潮的推进,大量 PDF 文档——学术论文、教材、财务报告、试卷——需要被精准地提取为结构化文本,以供后续检索、问答、知识库构建等应用使用。文档解析(Document Parsing)因此成为一项核心基础任务:给定一张 PDF 页面的图片,系统需要输出包含文字、公式、表格、图片位置的结构化 Markdown 文档。
然而,不同方法的解析结果良莠不齐,如何客观、全面地评估成了一大难题。一个好的评测基准需要覆盖多样的文档类型、多种语言、多种复杂版面,还需要针对文字、公式、表格等不同内容类型设计合适的评测指标。
为此,上海人工智能实验室提出了 OmniDocBench,于 2025 年发表在计算机视觉顶会 CVPR 上,专门用于评估基于 Pipeline、通用 VLM 和专有 VLM 的文档解析方法。
二、文档解析的三大技术路线
在介绍评测之前,先梳理当前文档解析的主流方法,这也是 OmniDocBench 重点覆盖的评测对象。
2.1 基于 Pipeline 的方法
Pipeline 方法采用”分而治之”的思路,将文档解析拆解为多个子任务,依次用专门的模型处理:
-
1. 版面检测:识别页面中各区域(文字块、表格、图片、公式)的位置和类别 -
2. 阅读顺序识别:确定各区域在文档中的阅读顺序 -
3. 内容识别:对文字块做 OCR,对公式做数学识别,对表格做结构化提取
这类方法的优点是各子模块独立可控、易于调试,缺点是错误会在级联过程中不断累积——版面识别一旦出错,后续所有结果都会受到影响,且整体工程复杂度较高。代表性工具有 Marker 等。
2.2 基于通用 VLM 的方法
以 Gemini 3 Pro、GPT-5.2、Qwen3-VL 为代表的通用视觉语言大模型(VLM),可以直接接受页面图像作为输入,通过 prompt 引导输出 Markdown 文档,无需任何额外的版面分析步骤。
这类方法对文字、复杂排版、表格、公式乃至图片都有一定的处理能力,但图片处理是通用 VLM 的固有软肋,原因是多方面的:
-
• 图片内容千差万别:文档中的图片可能是统计图表、示意图、照片、手绘插图……不同类型的图片需要截然不同的处理方式,有时不仅要提取文字,还需要理解图表含义、识别图注关系,通用 VLM 难以用一套 prompt 兼顾所有情况。 -
• 复杂页面的信息过载:当一张 PDF 页面同时包含大段正文、公式、表格和多张图片时,要求模型在单次调用中准确提取所有内容,本身就是极高的挑战。图片的存在会显著干扰模型对文本和公式的识别质量。 -
• 图片定位难以满足工程需求:实际工程中,图片往往需要被裁剪下来单独保存,在解析结果里用占位符标记位置,后续再用专门的图片理解模型处理。这要求系统能精确输出图片的边界框坐标。通用 VLM 中虽然有支持 Grounding(视觉定位)的方法,能够在图像中定位特定目标,但这类方法通常面向”找猫”、”找桌子”这样的自然图像目标检测场景,直接用于文档图片定位时精度有限;更关键的是,用于文档解析时需要同时完成文字识别、公式转换、表格结构化等大量其他任务,与 Grounding 任务相互干扰,整体输出的可靠性难以保证。
因此,通用 VLM 在实践中更常见的做法是直接忽略图片,将其跳过不处理,以保证文字、公式、表格部分的识别质量。以下是一个典型的通用 VLM 文档解析 prompt 示例:
You are an AI assistant specialized in converting PDF images to Markdown format.1. Text Processing: - Accurately recognize all text content without guessing or inferring. - Maintain the original document structure (headings, paragraphs, lists).2. Mathematical Formula Processing: - Convert all formulas to LaTeX format. - Inline formulas: \( E = mc^2 \) - Block formulas: \[ \frac{-b \pm \sqrt{b^2-4ac}}{2a} \]3. Table Processing: - Convert tables to HTML format, wrapped with <table></table>.4. Figure Handling: - Ignore figures. Do not describe or convert images.Please convert the PDF page to Markdown without extra explanations.注意 prompt 中明确要求模型忽略图片内容(Figure Handling: Ignore figures),这正是通用 VLM 处理文档的常见折中策略——以舍弃图片为代价,换取其他内容的高质量识别。
2.3 基于专用 VLM 的方法
这类方法是在通用 VLM 的基础上,针对文档识别场景进行专门微调,分为两种架构:
一步识别(如 olmOCR):模型一次调用完成整个页面的解析,包括文字、公式、表格识别。与通用 VLM 最关键的区别在于:微调时引入了图片位置的专项监督信号,训练数据中明确标注了每张图片的边界框坐标,使模型学会在输出 Markdown 的同时精确定位图片区域,并在对应位置插入图片占位符(如 )。这从根本上解决了通用 VLM 无法可靠定位图片位置的短板。
两步识别(如 MinerU2.5):随着专用 VLM 的发展,越来越多的工具将版面分析(Layout Analysis)和内容提取(Content Extraction)统一到同一个模型中。以 MinerU2.5 为例,这一个模型既能完成版面分析——识别页面中所有区域的位置和类别(文字块、表格、图片、公式等)——又能完成内容提取——对各区域的文本做 OCR、对公式做 LaTeX 识别、对表格做结构化输出。
相比一步识别,这种架构针对性地解决了一个痛点:分辨率与识别精度的矛盾。一步识别需要将整张 PDF 页面图像一次性送入模型,为了确保文字清晰可辨,必须使用很高的输入分辨率,这带来显著的计算压力,且模型需要同时”看清”整张大图中的每一个细节,超出了模型的感受野和注意力上限,容易漏识或误识。两步识别则将任务拆开:版面分析阶段只需识别各区域的大致位置和类别,不需要很高的分辨率即可完成;内容提取阶段则将各 block 的图像区域裁剪后单独送入模型,每次输入的只是一小块局部图像,分辨率充足、内容聚焦,可以对不同类型的 block(文字段落、公式、表格)分别应用最适合的识别策略,识别更精细。此外,由于图片区域在版面分析阶段已经获得精确的坐标框,后续还可以按需引入定制化的图片理解模型(如图表分析模型)做针对性的深度处理。
三、评测数据集
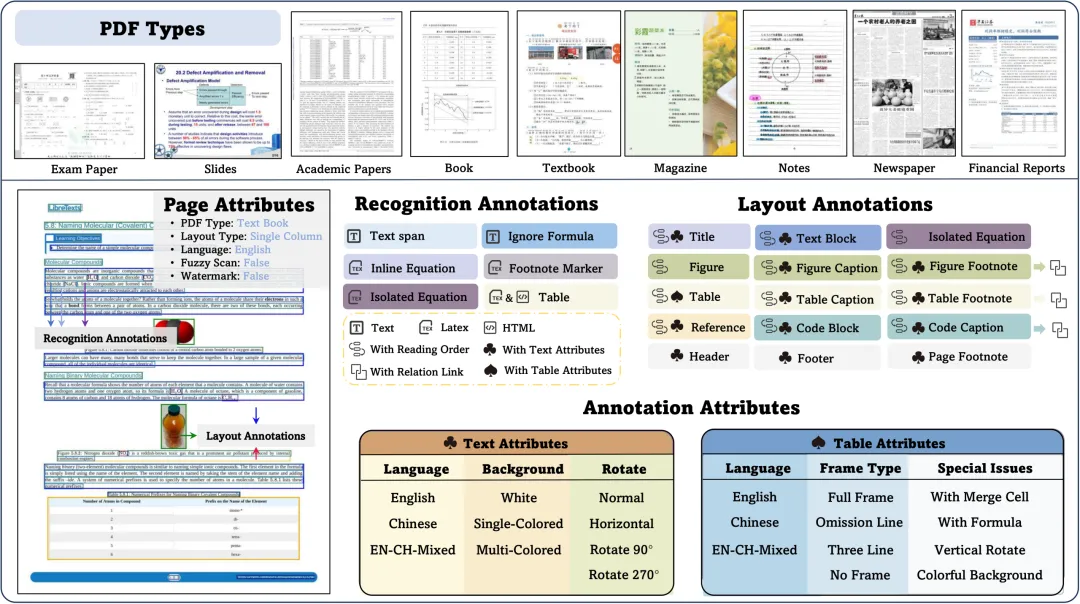
OmniDocBench 的标注集包含 1651 个 PDF 页面,覆盖 10 种文档类型:
-
• 学术论文(Academic Paper)、教材(Textbook)、书籍(Book) -
• 试卷(Exam Paper)、PPT 幻灯片(Slides)、杂志(Magazine) -
• 笔记(Notes)、报纸(Newspaper)、财务报告(Financial Reports)
3.1 页面级属性
每个页面附带 6 种维度的属性标签,便于后续按维度分析各方法的优劣势:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2 Block 级别标注
文档解析流程中,版面分析(Layout Analysis)阶段的核心任务就是识别页面中各区域的位置和所属类别——即对每一个内容区域打上以下类别标签之一。OmniDocBench 的 block 级别标注正对应了这一阶段的输出,共覆盖 18 种类别:
标题(title)、段落文本(text_block)图片(figure)、图片说明(figure_caption)、图片注释(figure_footnote)表格主体(table)、表格说明(table_caption)、表格注释(table_footnote)行间公式(equation_isolated)、公式序号(equation_caption)页眉(header)、页脚(footer)、页码(page_number)、页面注释(page_footnote)代码块(code_txt)、代码说明(code_txt_caption)参考文献(reference)、其他舍弃类(abandon)3.3 Span 级别标注
对于文字类 block(如标题、段落),标注进一步细化到 span 级别,支持混排文本的精细表示:
纯文本(text_span)、行内公式(equation_inline)上下角标(footnote_mark)、需忽略的公式(equation_ignore)例如,一段包含行内公式的文本会被标注为:
{ "text": "Which fraction is less than $\\frac{4}{8}$", "line_with_spans": [ {"category_type": "text_span", "text": "Which fraction is less than"}, {"category_type": "equation_inline", "latex": "$\\frac{4}{8}$"} ]}3.4 细粒度属性标注
除了类别之外,各 block 还附带细粒度属性,方便按特征维度分析识别难度:
表格(7 种属性):方向(竖版/横版)、合并单元格、线框类型(全线框/漏线框/三线框/无线框)、语种、是否含公式、是否有底色、是否旋转 90°/270°
文本(3 种属性):语种(英/中/混合)、背景色(白色/单色/混合色)、旋转角度(正常/旋转 90°/180°/270°/竖排文字)
公式(1 种属性):类型(打印体 / 手写体)
3.5 数据格式
标注集以 JSON 格式存储,每条记录包含三个顶层字段:
-
• layout_dets:页面所有 block 的标注列表,每个 block 包含类别、位置坐标(左上→右上→右下→左下)、文本/LaTeX/HTML 内容、阅读顺序、span 级标注等 -
• page_info:页面元信息(页码、宽高、图片路径、页面属性标签) -
• extra:关联关系标注,记录 figure/table 与其 caption/footnote 的父子关系,以及跨栏/跨页段落的截断关系
下面是一个完整的示例,展示了上述三个字段的完整结构:
[{ "layout_dets": [ { "category_type": "text_block", "poly": [ 136.0, 781.0, 340.0, 781.0, 340.0, 806.0, 136.0, 806.0 ], "ignore":false, "order": 0, "anno_id": 0, "text": "xxx", "latex": "$xxx$", "html": "xxx", "attribute": {"xxx": "xxx"}, "line_with_spans": [ { "category_type": "text_span", "poly": [...], "ignore":false, "text": "xxx", "latex": "$xxx$" } ], "merge_list": [ { "category_type": "text_block", "poly": [...], "line_with_spans": [...] } ] } ], "page_info": { "page_no": 0, "height": 1684, "width": 1200, "image_path": "xx/xx/", "page_attribute": {"xxx": "xxx"} }, "extra": { "relation": [ { "source_anno_id": 1, "target_anno_id": 2, "relation": "parent_son" }, { "source_anno_id": 5, "target_anno_id": 6, "relation_type": "truncated" } ] }}]poly 字段按左上、右上、右下、左下的顺序存储四个顶点坐标,共 8 个数值,支持旋转文本框的表示。
merge_list 字段专门处理列表类内容和单换行分割的小段落。文档中存在一类特殊情况:视觉上紧邻的多个短段落(如有序列表的各条目、被单个换行符分割的小段),在语义上属于同一内容块,但排版上被切分为多个独立区域。merge_list 将这些本属于同一逻辑单元的多个子段落聚合到父 block 中——父 block 的 text 字段存储合并后的完整文本,merge_list 则列出每一个子段落的标注细节。评测时,OmniDocBench 会先将 merge_list 中的子段落拼接还原为完整段落,再作为一个整体与预测结果进行比对,避免因排版切分导致的评测误差。


extra.relation 记录两类跨 block 关联关系:parent_son 标注 figure/table 与其对应 caption/footnote 之间的从属关系;truncated 标注因双栏排版或跨页导致被截断的段落,评测时会将截断的两部分拼接后再整体评分。
四、评测流程
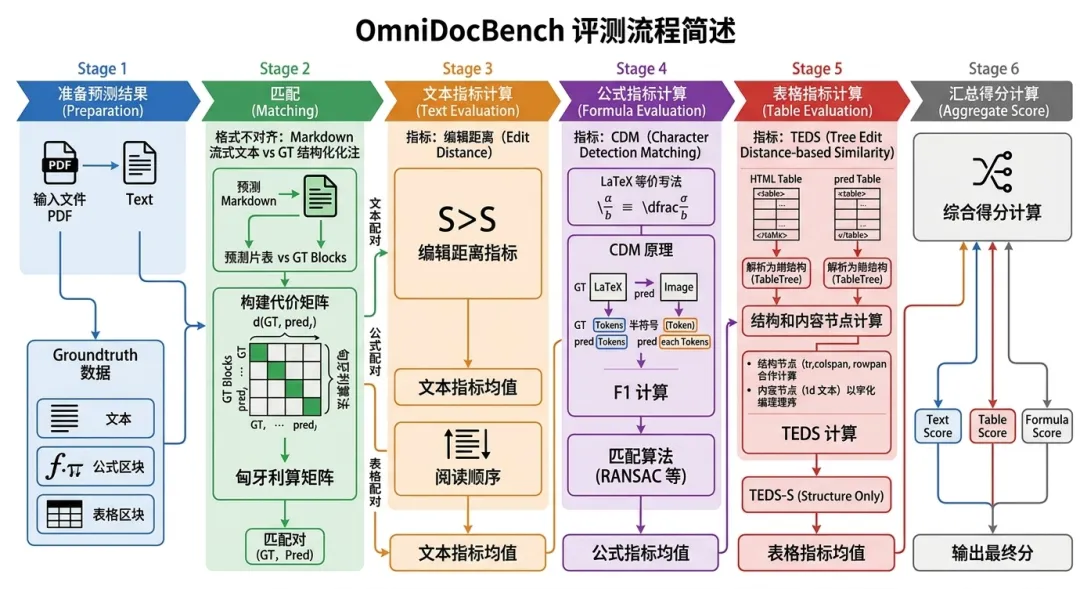
OmniDocBench开发了一套基于文档组件拆分和匹配的评测方法,对文本、表格、公式、阅读顺序这四大模块分别提供了对应的指标计算,精准定位模型文档解析的痛点问题。
整个评测流程可以分为以下几个步骤:
-
1. 准备预测结果:待评测的文档解析方法对评测集中每一张 PDF 页面图像运行,输出对应的 Markdown 文本文件。 -
2. 匹配(Matching):由于方法输出的 Markdown 是流式文本,而 groundtruth 是按 block 结构化标注的,两者格式不同,无法直接比对。匹配阶段的任务是将 Markdown 中的各段内容与 groundtruth 的各个 block 一一对应,为后续指标计算建立配对基础。 -
3. 文本指标计算:对匹配好的每一对(GT 文本 block,预测文本片段),用编辑距离度量识别准确率;对阅读顺序同样用编辑距离度量顺序一致性。 -
4. 公式指标计算:对匹配好的每一对(GT 公式,预测公式),用 CDM 指标在视觉空间度量公式识别质量。 -
5. 表格指标计算:对匹配好的每一对(GT 表格,预测表格),用 TEDS 指标在树结构层面度量表格识别质量。 -
6. 汇总综合得分:将文本、公式、表格三类指标按公式合并,输出最终综合分及各维度分项分。
下面逐步展开各阶段的细节。
4.1 评测输入
OmniDocBench 的评测流程以 Markdown 文档为接口:待评测的文档解析方法对评测集中的每一个 PDF 页面图像运行,输出一个 Markdown 格式的文本文件。评测系统随后将这些 Markdown 文件与 groundtruth JSON 标注进行比对,输出量化得分。
因此,评测的两个输入是:
-
• 预测输出:每页 PDF 对应的 Markdown 文本(由待评测方法生成) -
• 标注 groundtruth:OmniDocBench 的 JSON 标注文件
4.2 匹配阶段:为什么需要 Match?
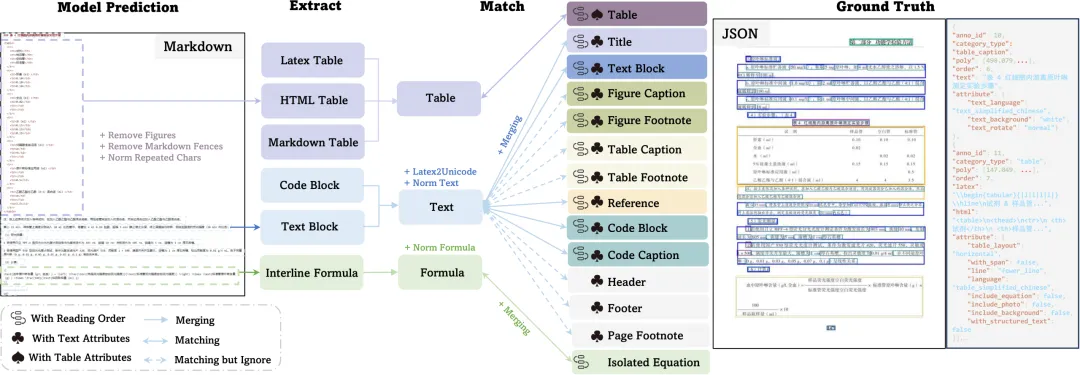
这里存在一个根本性的格式不对齐问题:
-
• Markdown 是流式文本:方法输出的 Markdown 是一段连续的文字流,其中各类内容(标题、正文、公式、表格)混合在一起,按阅读顺序排列。 -
• Groundtruth 是结构化标注:标注是按 block 切分的,每个 block 有明确的类别(文本、公式、表格),且带有位置坐标。
两者无法直接逐行对比。为了计算指标,必须先找到 Markdown 中每一段内容对应的是哪个 groundtruth block。这一步就是匹配(Matching)。
Match 的大致过程:
-
1. 拆分 Markdown:将预测的 Markdown 文本按照自然结构(段落、标题、公式块、表格块)切分成若干预测片段。 -
2. 构建代价矩阵:计算每个 groundtruth block 与每个预测片段之间的编辑距离,形成一个矩阵——矩阵的第 i 行第 j 列表示”第 i 个 GT block 与第 j 个预测片段的编辑距离有多大”。 -
3. 匈牙利算法(Hungarian Algorithm)求最优匹配:这是一个经典的最优二分图匹配算法。它在代价矩阵上寻找一种一一对应的配对方案,使所有匹配对的总编辑距离最小,且每个 GT block 和每个预测片段都只被分配一次。 匈牙利算法的核心价值在于找到全局最优解,而非贪心地每次选局部最小值——贪心策略很容易因为”抢占”了某个最优片段,导致其他 block 只能匹配到很差的片段,整体代价反而更高。
-
4. 输出匹配对:每个 GT block 都找到了与之对应的预测片段,形成一系列 (GT block, 预测片段) 的配对。后续所有指标的计算都基于这些配对。
4.3 文本识别:编辑距离(Edit Distance)
为什么选编辑距离?
文本识别的错误本质上是字符级别的偏差:漏识别几个字、多识别几个字、把某个字识别错了。编辑距离(Levenshtein 距离)直接量化了”把一个字符串改成另一个字符串所需的最少字符操作次数”,每次操作包括插入一个字符、删除一个字符或将一个字符替换为另一个字符。这种度量方式与文本识别错误的直觉完全吻合,且计算高效。
编辑距离的大致原理:
给定两个字符串 A 和 B,编辑距离通过动态规划逐步求解:用一个二维表格记录将 A 的前 i 个字符转化为 B 的前 j 个字符所需的最少操作数,最终右下角的值就是 A 转化为 B 的总编辑距离。
举个例子:”kitten” → “sitting” 需要 3 次操作(k→s、e→i、末尾加 g),编辑距离为 3。
OmniDocBench 如何使用编辑距离:
-
• 输入:一对配对后的文本,即 (GT block 文本, 预测片段文本) -
• 计算:先用 Levenshtein 算法计算原始编辑距离,再除以两段文本长度的最大值,归一化到 [0, 1] 区间(0 表示完全一致,1 表示完全不同) -
• 输出:所有 GT block 的归一化编辑距离的均值,作为最终的文本指标(越低越好)
阅读顺序的评测同样使用编辑距离:将各 block 的阅读顺序编号序列化为字符串后,计算预测顺序与 GT 顺序之间的编辑距离,衡量方法对文档结构的把握能力。
4.4 公式识别:CDM 指标
为什么不用编辑距离?
数学公式的 LaTeX 表示存在大量等价写法:\frac{a}{b} 与 \dfrac{a}{b} 视觉效果相同,\left( 与 ( 在很多场景可以互换,x^{2} 与 x^2 完全等价。传统的编辑距离只做字符串比较,会把这些等价写法判断为”不同”,导致评测结果与实际视觉质量脱节——一个公式识别器可能输出了视觉上完全正确的公式,却因为 LaTeX 风格不同而得到很低的编辑距离得分。此外,编辑距离对训练数据分布敏感,容易造成不同方法之间的不公平比较。
CDM 的提出背景:
CDM(Character Detection Matching)由王等人在 CVPR 2025 论文《Image Over Text: Transforming Formula Recognition Evaluation with Character Detection》中提出,专门针对公式识别评测中字符串比较的固有缺陷而设计,其核心思想是从字符串空间转移到视觉空间进行比较。
CDM 的大致原理:
-
1. 渲染为图像:将 GT LaTeX 和预测 LaTeX 分别用 LaTeX 引擎渲染成图片,让视觉等价的公式在图像层面呈现一致。 -
2. 检测数学符号(Token):在两张图片上分别检测每一个数学符号的位置,得到 GT token 集合和预测 token 集合,每个 token 附带颜色和位置信息(bounding box)。 -
3. 匈牙利算法匹配:在 GT tokens 和预测 tokens 之间构建匹配代价矩阵,用匈牙利算法求最优一一对应关系。 -
4. RANSAC 几何一致性过滤:对匹配结果进行几何验证——真正正确的 token 对应关系在空间上应当满足某种仿射变换关系,RANSAC 算法迭代地找出满足几何约束的”内点(inlier)”并剔除异常匹配。 -
5. 计算 F1 分数:其中 TP 为经过几何过滤后的正确匹配数, 和 分别为 GT 和预测的 token 总数。
OmniDocBench 如何使用 CDM:
-
• 输入:一对匹配好的公式,即 (GT LaTeX 字符串, 预测 LaTeX 字符串) -
• 输出:CDM F1 分数,范围 [0, 1](越高越好) -
• 聚合:对所有公式 pair 的 CDM 分数取均值,乘以 100 得到最终公式得分
4.5 表格识别:TEDS 指标
为什么不用编辑距离?
表格在本质上是一种树形结构(table->tr->td):表格(table)包含若干行(tr),每行包含若干单元格(td),单元格之间还可能存在合并(colspan、rowspan)。编辑距离处理的是线性序列,而表格被序列化为字符串后,一个单元格的错位会带来大范围的字符串变化,导致编辑距离严重高估结构差异——即使两个表格整体结构相似,只是有几个单元格的内容稍有偏差,字符串编辑距离也可能非常大。
TEDS 的提出背景:
TEDS(Tree Edit Distance-based Similarity)由 IBM Research 的 Xu Zhong 等人提出,发表于 ECCV 2020 论文《Image-Based Table Recognition: Data, Model, and Evaluation》,同期发布了大规模表格数据集 PubTabNet。TEDS 将表格的 HTML 表示解析为树,在树的层面进行比较,能够自然地处理合并单元格、跨行列等复杂结构。
TEDS 的大致原理:
-
1. 解析为树结构:将 HTML 格式的表格(如 <table><tr><td>...</td></tr></table>)解析为 TableTree,树的节点对应各个 HTML 标签(table、tr、td 等),节点上携带标签名、colspan、rowspan、单元格文本内容等属性。 -
2. 计算树编辑距离:使用 APTED(All-Path Tree Edit Distance)算法计算两棵 TableTree 之间的树编辑距离——即通过插入、删除、修改节点将一棵树转化为另一棵树所需的最少操作次数。 -
• 对于结构节点(tr、colspan、rowspan),若属性不完全一致则代价为 1(视为替换) -
• 对于内容节点(td 的文本),用归一化 Levenshtein 距离衡量内容相似度 -
3. 归一化:其中 为树的节点总数,归一化后 TEDS 的范围为 [0, 1],1 表示完全一致,0 表示完全不同。 -
4. TEDS-S(Structure Only):在计算 TEDS-S 时,忽略 td 节点的文本内容,只比较表格的结构(行数、列数、合并关系),适合专门评估表格结构识别能力。
OmniDocBench 如何使用 TEDS:
-
• 输入:一对匹配好的表格,即 (GT HTML 字符串, 预测 HTML 字符串) -
• 输出:TEDS 分数([0,1],越高越好)和 TEDS-S 分数(仅结构) -
• 聚合:对所有表格 pair 的 TEDS 分数取均值,乘以 100 得到最终表格得分
4.6 综合得分
将三类指标合并为一个综合分:
文本编辑距离越低越好,因此用 1 减去它转化为”越高越好”的形式,与 TEDS 和 CDM 保持一致方向,再取三者平均。
五、评测结果对比
下表汇总了主流文档解析方法在 OmniDocBench(v1.6_full)上的评测结果:
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|---|---|
|
|
MinerU2.5-Pro |
|
95.75 | 0.036 | 97.45 | 93.42 | 95.92 | 0.120 |
|
|
|
|
95.22 |
|
97.18 | 92.83 | 95.39 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
从结果可以看出几个规律:
专用 VLM 整体领先。MinerU2.5-Pro 以 95.75 分居首,仅用 1.2B 参数便超过了参数量高达 235B 的 Qwen3-VL(89.78 分),说明针对文档解析场景的专项微调效果显著——领域专用数据的质量远比参数规模更关键。
通用 VLM 处于中游。Gemini 3 Pro(92.91 分)表现最好,甚至超过了部分专用 VLM,但仍低于顶级专用模型。值得注意的是,通用 VLM 在表格(Table TEDS)维度相对文本和公式的劣势更明显,复杂表格结构仍是通用模型的弱项。
Pipeline 方法明显落后。Marker 以 78.44 分垫底,尤其在表格识别(TEDS 65.77)和阅读顺序(Read Order Edit 0.243)上差距较大,反映出级联误差积累的固有缺陷。
小结
OmniDocBench 的价值在于:用一套精心设计的多维评测体系,客观地衡量了文档解析这一复杂任务的各个子维度。其评测流程的核心设计——用匹配+编辑距离对齐异构格式,分别用编辑距离、CDM、TEDS 针对文本、公式、表格的不同特性设计专属指标——既保证了评测的公平性,也推动了社区对各类内容识别能力的精细认知。
对于研究者和工程师而言,OmniDocBench 既是一把尺子,也是一面镜子:它告诉你自己的方法在哪些文档类型、哪种内容类型、哪种版面布局上还有提升空间,从而为下一步的技术迭代指明方向。
OmniDocBench github地址:https://github.com/opendatalab/OmniDocBench/tree/main