 夜雨聆风
夜雨聆风





LLM Wiki:把文档变成会生长的知识库
你可能也有这种时刻:资料越囤越多,真正要用时却找不到;每次提问都像“从零检索”,上下文永远不连贯。
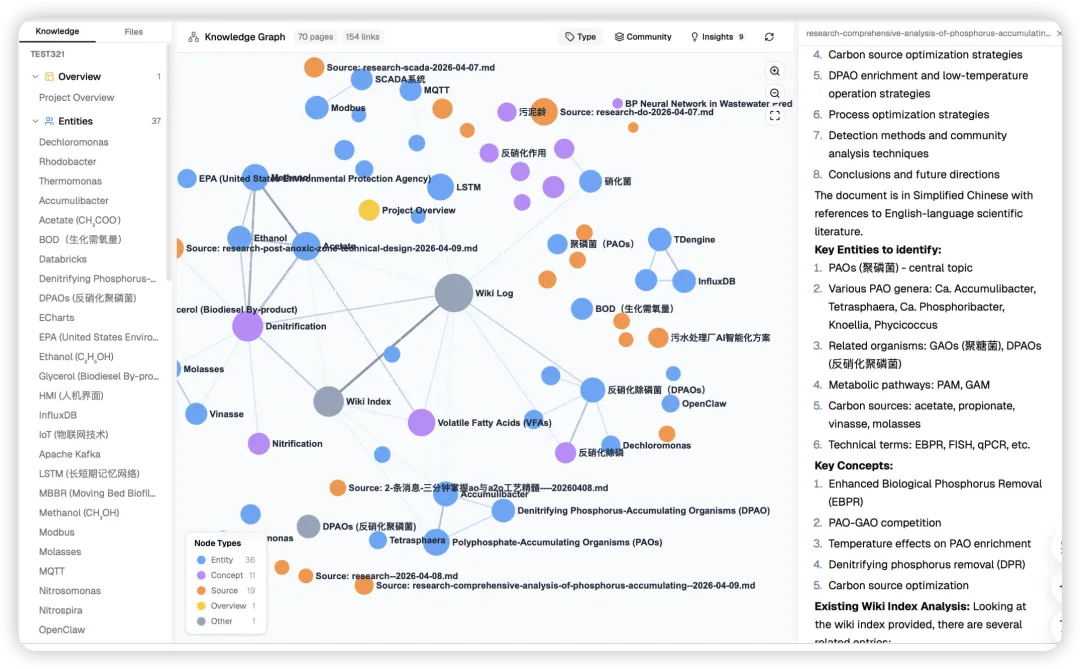
LLM Wiki 想解决的正是这个问题:不是一次次临时问答,而是把你的资料沉淀成一个可持续演化的知识系统。📚
它到底在解决什么问题?
很多人把它和常见 RAG 工具放在一起看,但它的核心思路不同:
-
传统 RAG:每次查询都“临时拼上下文”,回答结束后系统几乎不长记性。 -
LLM Wiki:把文档持续编译成 Wiki,知识被结构化保存,并随着新资料不断更新。
它基于 Karpathy 提出的 llm-wiki 模式实现,并扩展成完整桌面应用(macOS/Windows/Linux)。
你可以把它理解为:让 LLM 从“即时回答器”变成“长期知识维护者”。
哪些场景会非常受用?
-
研究型学习:论文、报告、网页资料持续导入,自动形成实体页、概念页和交叉链接。 -
团队知识沉淀:把项目文档、会议纪要、方案评审结果沉淀成可检索的知识网络。 -
长周期课题:主题会不断变化,但知识库保持“增量更新”而非反复重建。 -
内容创作与咨询:快速定位历史结论、证据来源和关联概念,减少重复检索。
简单说,它特别适合“资料会不断增长、问题会不断迭代”的工作流。
真正有价值的地方,不止是“能问答”
从工程和业务角度看,LLM Wiki 的价值主要在四点:
-
持续复利:同一份资料只需高质量摄入一次,后续查询持续受益。 -
来源可追溯:生成页面带 sources[],可回跳原始文档,降低“说了但无据可查”的风险。 -
结构化组织: index.md、overview.md、[[wikilink]]形成可导航知识骨架。 -
人机分工清晰:人负责策展与判断,LLM 负责整理、关联、更新与检索。
当资料规模上来后,这种“沉淀式知识工程”比一次次临时检索更稳,也更省时间。⏱️
技术机制拆开看:它是怎么“长出知识网络”的?
从三层架构开始:Raw → Wiki → Schema
核心架构延续 llm-wiki 设计:
-
Raw Sources:原始资料层,保留输入,不随意改写。 -
Wiki:LLM 生成的知识层,包含实体、概念、来源摘要、综合页等。 -
Schema(加上 purpose):约束结构规则,并定义知识库目标与研究方向。
其中 purpose.md 是一个很实用的增强:它让系统在摄入和问答时都带着“目标意识”。
摄入不是一步到位,而是“两段式”
它把 ingest 拆成两次 LLM 调用:
-
分析阶段:先抽取实体、概念、矛盾点、与已有知识的关系。 -
生成阶段:再生成 Wiki 页面、更新索引和日志,并产出待审查项。
配合增量缓存(按文件哈希跳过未变化内容)和持久化队列(崩溃恢复、重试、进度可视化),在质量和稳定性上都明显优于“单次读写”。
查询链路是“关键词 + 图谱 + 可选向量”
它的检索不是单一向量召回,而是多阶段融合:
-
第一段:分词检索(中英文都做了针对性处理)。 -
第二段:可选向量语义检索(LanceDB,OpenAI 兼容 embedding 接口)。 -
第三段:图谱扩展(基于页面关联关系做 2-hop 拓展)。 -
第四段:上下文预算分配(按比例把 token 留给 Wiki 内容、对话历史、索引和系统提示)。
这类组合策略的好处是:既能命中“字面相关”,也能发现“语义相关”和“结构相关”。
图谱不是摆设,它能发现“盲区”
LLM Wiki 里知识图谱做了完整工程化:
-
4 信号相关性模型:直接链接、来源重叠、Adamic-Adar、类型亲和。 -
社区发现:Louvain 自动聚类并给出凝聚度评分。 -
Graph Insights:提示“意外连接”和“知识缺口”,可一键触发 Deep Research。
这一步把知识库从“被动查询”推进到“主动提示下一步研究”。
它背后到底依赖哪些工具?
如果只看表面,你会觉得它像一个“文档问答器”;但真拆开看,LLM Wiki 更像一套拼装得很完整的知识工程流水线。它背后主要依赖三层能力:
-
第一层是桌面应用外壳: Tauri v2负责跨平台桌面能力,前端用React 19、TypeScript、Vite组织界面。 -
第二层是知识处理引擎:文档导入、结构化生成、图谱关联、检索排序都在这一层完成。 -
第三层是外部智能服务:包括 LLM、embedding,以及 Deep Research 用到的搜索服务。
换句话说,它不是单靠一个大模型“硬答”,而是把模型、检索、图谱、文档解析和桌面交互串成了一条完整链路。
如果你是普通用户,真正离不开的其实不多
对大多数人来说,最低可用依赖只有两个:
-
一个可用的 LLM 提供商:比如 OpenAI、Anthropic、Google、Ollama或兼容接口。 -
一批你自己的资料:比如 PDF、DOCX、Markdown、网页剪藏内容。
也就是说,如果你只是想体验“导入资料 -> 自动长出 Wiki -> 再用聊天方式提问”,其实并不需要关心太多底层细节。
想把效果拉满,就要补上这些增强组件
当你开始追求“召回更准、研究更深、采集更顺”时,下面这些工具就派上用场了:
-
LanceDB:可选的向量检索层,用来承接语义搜索。 -
OpenAI 兼容的 embedding接口:让系统不止能按关键词找,还能按语义找。 -
Tavily、SerpApi、SearXNG:给 Deep Research 提供外部搜索能力。 -
Chrome 插件配套的 Readability.js和Turndown.js:负责把网页内容提纯并转成 Markdown。
这一层很像给知识库装“雷达”和“采集器”。不开也能用,开了之后,系统会明显更聪明。🔍
文档解析这块,它也准备得很全
为了让“什么都能喂进去”不只是一句口号,LLM Wiki 还接入了多种解析工具:
-
PDF: pdf-extract -
DOCX: docx-rs -
XLSX/XLS/ODS: calamine -
网页剪藏: Readability.js + Turndown.js
这意味着它并不是只偏爱 Markdown 用户,而是在尽量适配真实世界里更杂、更乱的知识来源。
如果你想自己编译或二开,还需要开发工具链
这一部分主要面向开发者:
-
Node.js 20+ -
Rust 1.70+ -
npm install -
npm run tauri dev
因为桌面端基于 Tauri,前端和原生层都要参与构建,所以源码运行时比“下载一个安装包直接用”要多一层准备。但好处也很明显:你可以自己改界面、改流程、改接入模型,甚至把它变成适合团队内部的知识平台。
5 分钟上手:从安装到第一轮知识沉淀
如果你想本地跑起来,按这条路径即可:
# 前置:Node.js 20+、Rust 1.70+
git clone https://github.com/nashsu/llm_wiki.git
cd llm_wiki
npm install
npm run tauri dev
首次使用建议:
-
新建项目并选择模板(Research/Reading/Business 等)。 -
在 Settings 配置 LLM Provider(API Key + Model)。 -
导入 PDF/DOCX/Markdown 等资料到 Sources。 -
观察 Activity Panel 的摄入进度与失败重试。 -
用 Chat 提问,并在 Graph/Review/Deep Research 持续完善知识网络。
另外,Chrome 插件可一键剪藏网页并自动进入 ingest 流程,适合日常碎片化采集。🧩
这类工具的三个使用提醒
-
别把它当“自动真理机”:Review 队列一定要用,人要做最终判断。 -
先定好 purpose.md:目标越清晰,后续结构化效果越好。 -
分层管理来源:按主题或目录导入,图谱质量会比“混投文件”更高。
官方链接(建议收藏)
https://github.com/nashsu/llm_wiki
最后一句
如果你已经厌倦了“资料很多,但知识不增长”的循环,LLM Wiki 值得试一次。
它真正有意思的地方是:把 LLM 的能力从“回答问题”推进到“持续建设你的知识系统”。🚀
#LLMWiki #知识管理 #RAG进化 #开源工具 #AI效率