 夜雨聆风
夜雨聆风





CiteVQA:可信文档智能的证据归因基准测试

CiteVQA: Benchmarking Evidence Attribution for Trustworthy
Document Intelligence
报告原文地址:https://arxiv.org/pdf/2605.12882
报告概述
上海人工智能实验室于2026年5月发布CiteVQA基准测试,首次将文档理解的评估标准从“答案对错”升级为“答案+证据溯源”双重验证。通过对20个主流多模态大模型(MLLM)在1897个问题上的测试,研究发现模型普遍存在“归因幻觉”:即便给出正确答案,也可能引用完全错误的文档区域。当前最强模型Gemini-3.1-Pro的联合准确率仅为76.0%,而开源模型最高仅22.5%,暴露出高风险领域应用的可靠性缺口。
核心洞察
“答对题但抄错笔记”是行业通病:现有评测只关注最终答案,掩盖了模型推理过程的致命缺陷。在法律、医疗等场景,引用来源错误比答案错误更具隐蔽性和破坏性。
开源模型与闭源差距拉大:在证据溯源任务上,开源模型表现出现断崖式下跌,最高SAA不足25%。这意味着企业若直接使用开源模型处理专业文档,风险极高。
多文档场景是落地瓶颈:当需要从多个文件中交叉验证信息时,即便是顶尖模型,其定位证据的召回率也会骤降超过13个百分点。
一、为什么我们需要“带证据”的问答?
现在的AI看文档,很像考试时只写答案不写解题过程的“蒙题党”。以往评测Doc-VQA(文档视觉问答)只看答案匹不匹配,导致一个怪象:模型可能靠预训练里的常识“猜”对了答案,或者引用了完全不相关的段落却得出了正确结论。
这在刷短视频、查百科时问题不大,但在金融审计、法律文书、临床诊疗中,这种“黑盒推理”是不可接受的。你必须知道AI的结论是从哪一页、哪一段、哪张表里抠出来的。
为此,上海AI实验室推出了CiteVQA。它不再只问“答案是什么”,而是强制要求模型在回答时,必须附带元素级(Element-level)的边界框(Bounding-box)引用——就像你在论文里标注参考文献的页码和段落一样精确。
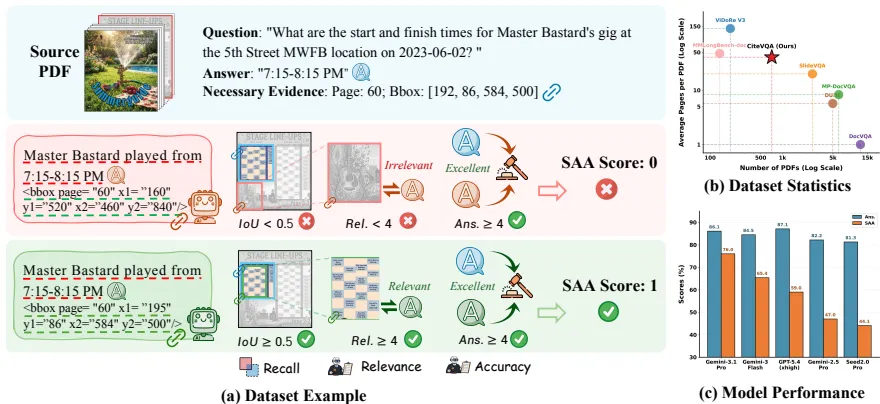
为了构建这个高难度数据集,研究团队设计了一套自动化流水线。他们从超过1亿份PDF中筛选出711份高质量文档,利用“掩码消融”技术自动识别关键证据:如果把某个段落遮住,模型就答不对题,那这个段落就是必须引用的“关键证据”。
二、残酷的测试结果:归因幻觉
CiteVQA引入了一个核心指标:严格归因准确率(Strict Attributed Accuracy, SAA)。只有当你答案正确且引用的证据区域也完全正确时,才算得分。
测试结果令人警醒。在对20个主流模型的全面“体检”中,几乎所有模型都表现出严重的“归因幻觉”。
表:主流MLLM在CiteVQA上的表现(Overall SAA)
|
模型类别 |
代表模型 |
SAA得分 |
答案准确率(Ans.) |
关键证据召回率(Rec.) |
|---|---|---|---|---|
|
闭源SOTA |
Gemini-3.1-Pro-Preview |
76.0 |
86.1 |
66.0 |
|
闭源第二梯队 |
GPT-5.4 |
59.0 |
87.1 |
31.0 |
|
开源最强 |
Qwen3-VL-235B-A22B |
22.5 |
72.3 |
11.3 |
|
开源小模型 |
Qwen3-VL-8B |
7.5 |
61.2 |
1.0 |
案例解析:
在一个查询药品NDC编码的任务中,Qwen3-VL-235B虽然给出了完全正确的编码(Ans.=5),但由于它引用的截图区域完全不包含这些信息(Rec.=0),最终SAA得分为0。这证明模型只是在“背诵”知识,而非“阅读”文档。
1. 多文档是“照妖镜”
任务越复杂,模型的“幻觉”越严重。在单文档任务中,Gemini-3.1-Pro还能保持68.9的召回率;但当面对需要从多个文件中找线索的“多金文档(Multi N-Gold)”场景时,其召回率暴跌至55.3。
这意味着,目前的AI在处理投行研报对比、竞品分析等需要跨文档整合信息的任务时,极其容易“张冠李戴”。
2. 分辨率决定生死
实验还发现,证据定位对图像清晰度极度敏感。将输入分辨率减半,SAA分数会直接腰斩(从22.5降至11.8)。这说明低质量的扫描件或压缩过度的图片,会直接导致AI“指鹿为马”。
三、不仅仅是评测,更是改进方向
虽然现状严峻,但研究也带来了积极的信号。当研究人员人为缩小模型的搜索范围(例如直接告诉它“答案在第5页”),所有模型的准确率都显著上升。这表明,提升模型的“检索定位能力”,可能是解锁其深层推理潜力的关键。
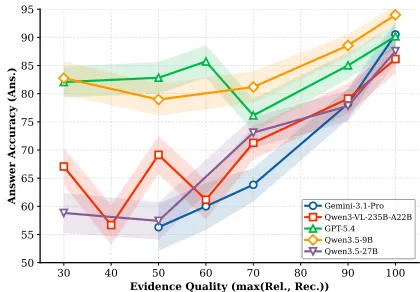
此外,研究还发现,随着证据质量的提升,答案准确率也呈现正相关。也就是说,强迫模型“引经据典”,反而能让它变得更聪明。
表:缩小搜索空间对性能的提升(Ablation Study)
|
模型 |
基础设置 (SAA) |
仅提供GT页面 (SAA) |
提升幅度 |
|---|---|---|---|
|
Qwen3.5-27B |
73.1 |
81.6 |
+8.5 |
|
Qwen3-VL-8B |
53.3 |
66.7 |
+13.4 |
结语:信任建立在可追溯之上
CiteVQA的发布给火热的“文档智能”赛道泼了一盆冷水,但也指明了方向。对于普通用户,在使用AI处理合同、财报等重要文件时,务必人工核对其引用的原文片段,不要轻信单纯的文本回复。对于行业,这意味着未来的竞争焦点将从“参数规模”转向“溯源精度”。一个能在长文档中精准“指路”的模型,远比一个只会“侃侃而谈”的模型更有商业价值。