 夜雨聆风
夜雨聆风





OpenClaw �� 记忆系统全景:9个模块,3层架构,1篇讲完.
OpenClaw 的记忆系统,比大多数人想象的要复杂得多。
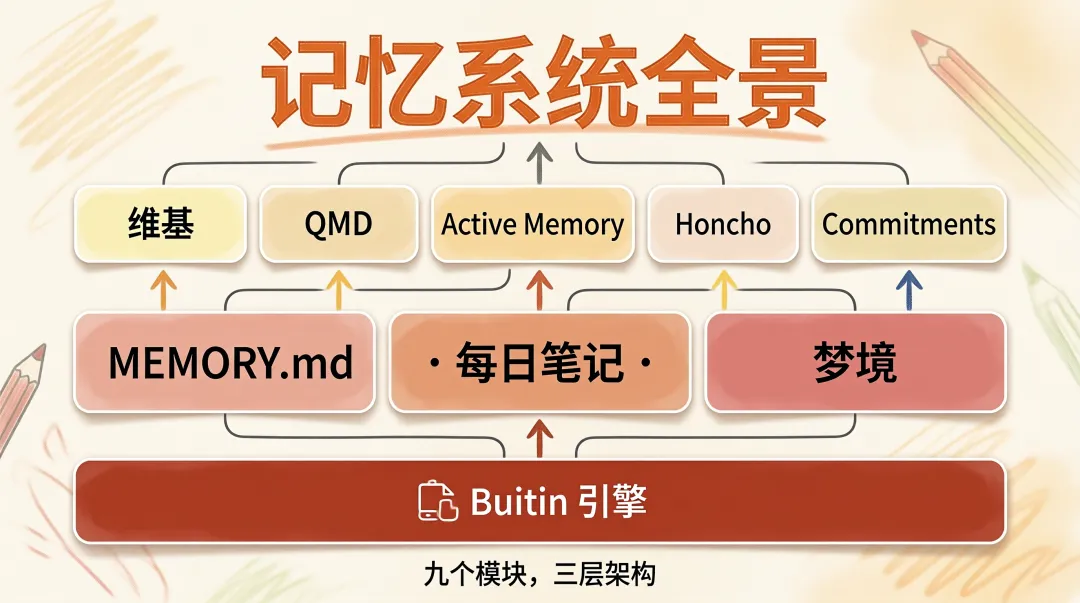
很多人对 OpenClaw 记忆的理解停留在 MEMORY.md 和每日笔记这几个文件上。写进去,就记住了。但我自己折腾下来发现,根本不是这么回事。从底层引擎到上层应用,OpenClaw 的记忆体系覆盖了五个关键模块。Builtin 引擎是索引地基,MEMORY.md 和每日笔记是文件存储,维基是结构化知识库,梦境是后台自动整理。外加 QMD 增强搜索、Active Memory 主动检索、Honcho 跨会话服务、Commitments 智能跟进四个进阶选项。
为了写这篇文章,我把 OpenClaw 官方文档里关于记忆的所有页面都读了一遍。从 MEMORY.md 到 Memory Wiki,从 Builtin 引擎到 QMD,从 Active Memory 到 Honcho,再到 Commitments,还有梦境。现在把这些内容整理出来,希望能帮你省下至少一周的摸索时间。
你如果也在用 OpenClaw,或者正准备用,这篇文章能帮你把整个记忆体系搞清楚。
记忆系统不是只有一个文件
很多人第一次接触 OpenClaw 的记忆,以为就是 MEMORY.md 这一个文件。写进去,就记住了。其实不是。
OpenClaw 的记忆系统是一个三层架构,每一层干的事不一样。
最底层是 MEMORY.md,这是长期记忆。你的偏好、你的持仓、你的投资规则、你姓什么叫什么,都在这。每次主会话启动,这个文件会被加载进上下文,所以 AI 一上来就知道你是谁。
中间层是 memory/YYYY-MM-DD.md,这是每日笔记。今天聊了什么、AI 发现了什么、你说了什么重要的事,都记在这。它不会每次启动都加载,但会被 memory_search 搜到。
最上面一层是 DREAMS.md,这是梦境日记。如果你开了梦境功能,系统会在后台自动整理短期记忆,把够格的内容推送到 MEMORY.md,把整理结果写在这。
这三层的关系,你可以这么理解。MEMORY.md 是 curated 的精选集,memory/*.md 是 raw 的素材库,DREAMS.md 是整理过程的记录。
举个例子,你的持仓数据可以同时写进 MEMORY.md 和维基。为什么写两处?因为 MEMORY.md 是给 AI 用的,维基是给人类用的。查 MEMORY.md 看到的是流水账,查维基看到的是结构化页面,有证据、有置信度、有关联链接。
内存引擎(Builtin)–记忆的地基
记忆系统最底层的东西,叫 builtin engine,也就是内建记忆引擎。它不需要安装任何额外依赖,装好 OpenClaw 就有。我当时第一次接触这个的时候还纳闷,啥也没配置怎么就能搜记忆了,后来才发现,这玩意是默认就有的。
它的核心是一个 SQLite 数据库,存在 ~/.openclaw/memory/<agentId>.sqlite 里。你的 MEMORY.md 和 memory/*.md 都会被切分成小段(每段大约 400 tokens,80 tokens 重叠),索引到这个库里。
它支持三种搜索方式。
关键词搜索靠的是 SQLite 的 FTS5 全文索引,用 BM25 算法打分。你搜「网关配置」,它能把含网关和配置的片段排在最前面。对中日韩文有专门的三元组分词支持,不是简单按空格切。
向量搜索靠的是嵌入模型。如果你配了 OpenAI、Gemini、Voyage、Mistral 或 DeepInfra 的 API Key,它自动检测到并启用向量搜索。没有 API Key 也可以用本地嵌入,装 node-llama-cpp 运行时包,指定一个 GGUF 模型就行。向量搜索的好处是能找到意思相近但字面不同的内容。比如你搜「跑在什么机器上」,它能匹配到「the machine running OpenClaw」这种英文记录。
混合搜索就是把关键词和向量两个结果按权重合并,取两者的优势。
索引是自动维护的。你改 MEMORY.md,系统等 1.5 秒(防抖)后自动重新索引。换了嵌入模型或改了分块参数,整个索引自动重建。想手动重建也行,openclaw memory index --force。
SQLite 还有个可选的加速方案叫 sqlite-vec,装了能在数据库里直接跑向量查询,不用在内存里做余弦相似度计算。没装也不影响,系统自动回退到内存计算。
听起来复杂,但对你来说完全不用管。它就在后台默默跑,你装好 OpenClaw 那天它就工作了。
记忆搜索–AI 怎么在记忆里翻东西
builtin 引擎建好索引后,AI 用的 memory_search 工具就是在它上面查的。那这个搜索到底怎么工作的?
它的核心是两条路并行跑。
第一条路是向量搜索。把问题转成向量,在索引里找意思相近的片段。比如问「用户什么职业」,它能匹配到「用户 35 岁,自由职业」。
第二条路是 BM25 关键词搜索。直接找字面匹配。比如问「股票代码 002734」,它能精确命中那条持仓记录。
两条路的结果合并后,按权重排序,取前几名返回给 AI。
如果嵌入模型不可用(没配 API Key,也没装本地嵌入),那只有关键词搜索能用。但即使在这种情况下,它也不会退化成简单的逐字匹配。仍然用 BM25 算法对 FTS 结果排序,按查询词覆盖度和文件路径相关性加权。
有两个可选功能可以提升搜索质量。
时间衰减。旧笔记的排名权重逐渐降低,半衰期默认 30 天。一个月前的笔记权重只有原来的 50%。但 MEMORY.md 不受衰减影响,因为它被标记为永久文件。如果你有好几个月的每日笔记,而且老信息总排在新信息前面,就可以开启这个。
MMR(多样性)。如果五条结果都在说同一个路由配置,MMR 会确保前几条覆盖不同主题,而不是重复。如果你发现 memory_search 返回的片段总是很相似,可以开启这个。
两个都开的话,配置像这样。
memorySearch:{ query:{ hybrid:{ mmr:{ enabled:true}, temporalDecay:{ enabled:true},},},}还有个有意思的功能叫多模态记忆。用 Gemini Embedding 2 的话,可以连图片和音频文件一起索引。你用文字搜「上次那个截图」,它能匹配到图片内容。我当时看到这个功能就觉得,好家伙,以后找东西不用翻相册了。
QMD–更强大的本地搜索引擎
builtin 引擎够用,但它有个限制。只能搜你工作区里的记忆文件。如果你想搜项目文档、团队笔记、甚至以前的对话记录,就需要更强大的东西。
QMD 就是干这个的。全称是 Quantum Memory Device,一个本地运行的搜索侧车,跟 OpenClaw 一起跑。
它的作者叫 Tobi(@tobilu/qmd),一个独立的开源项目。QMD 把 BM25、向量搜索和重排序(reranking)打包成一个二进制文件,能索引任何 Markdown 文件。
QMD 比 builtin 引擎强在哪?三个核心优势。
重排序和查询扩展。builtin 只做一次搜索,QMD 可以搜完再重排一次,把更相关的结果提上来。查询扩展能自动帮你把问题改写一下再搜,提高召回率。
索引额外目录。你可以让 QMD 索引 ~/notes/、~/projects/ 甚至整个文档目录,这些内容也能被 memory_search 搜到。
索引对话记录。QMD 可以把过去的会话记录也索引进来,这样 AI 就能搜到几天前甚至几周前聊过的东西。
而且它完全是本地的。装 node-llama-cpp 后自动下载 GGUF 模型(大约 2GB),不需要任何 API Key。如果 QMD 出问题了,系统自动回退到 builtin 引擎,不会中断使用。
但 QMD 也有门槛。安装需要 npm install -g @tobilu/qmd,macOS 和 Linux 开箱即用,Windows 最好用 WSL2。第一次搜索很慢,因为要下载 GGUF 模型。我自己的话,暂时没上 QMD,因为 builtin 对我目前来说够用了。
什么时候该从 builtin 换到 QMD?三种场景。
你已经有好几个月的每日笔记,关键词搜索不够用了,需要重排序提高准确率。你想搜索工作区以外的文档,比如项目文档或团队笔记。你想让 AI 能回忆之前的对话记录。
如果你觉得 builtin 已经够用,那就继续用着。QMD 不是必需品,是进阶选项。
梦境–AI 的后台整理
梦境是记忆系统里最玄学但最有意思的部分,值得单独拿出来讲。
梦境(Dreaming)是 memory-core 插件里的后台记忆巩固系统。它的作用是帮 OpenClaw 把短期信号变成持久记忆,同时保持这个过程可解释、可审查。
梦境是 opt-in 的,默认关闭。如果你开启了,DREAMS.md 里就会有内容。我自己是开了的,因为懒,不想每天手动整理记忆。
梦境干的事,可以用一个比喻。你白天看了很多东西,晚上睡觉时大脑会自动整理,把重要的东西存进长期记忆,把不重要的忘掉。梦境就是 AI 的夜间整理过程。
梦境有三个阶段,叫 phase。
Light phase 是浅睡。它读取最近的每日记忆信号和回忆痕迹,去重,暂存候选条目。它不会写入 MEMORY.md,只是把材料准备好。
Deep phase 是深睡。它决定什么东西能成为长期记忆。它用加权评分和阈值门控来排名候选条目。要求 minScore、minRecallCount、minUniqueQueries 都达标才能通过。它会把促推的条目追加到 MEMORY.md,把总结写入 DREAMS.md。
REM phase 是快速眼动睡眠。它提取模式和反思信号。从短期痕迹里构建主题和反思摘要。它也不会写入 MEMORY.md。
这三个阶段是内部实现细节,不是用户配置的独立模式。一个完整的梦境扫描按 light 到 REM 到 deep 的顺序运行。
梦境的评分信号有六个,每个有权重。
频率占 0.24,看一个条目积累了多少短期信号。相关性占 0.30,看平均检索质量。查询多样性占 0.15,看多少不同的查询上下文触发了它。近期性占 0.15,时间衰减的新鲜度分数。巩固占 0.10,多天重复的强度。概念丰富度占 0.06,片段路径的概念标签密度。
Light 和 REM 阶段的命中会给 deep 排名加一个小的近期衰减 boost。
梦境的输出有两种。机器状态在 memory/.dreams/ 里,包括回忆存储、阶段信号、摄入检查点、锁。人类可读输出在 DREAMS.md 里,还有可选的阶段报告文件在 memory/dreaming//YYYY-MM-DD.md 下。
长期推送只写入 MEMORY.md。DREAMS.md 是给人类看的梦境日记,不是推送源。
梦境的默认调度是每天凌晨 3 点跑一次完整扫描。cron 表达式是 0 3 * * *。你可以在 config 里改这个频率,比如改成每 6 小时一次。
梦境还提供了一个 grounded historical backfill 车道。你可以用 openclaw memory rem-backfill 从历史每日笔记里回放,预览哪些东西值得推送,然后再决定要不要真的推。这个流程是可逆的,推错了可以 rollback。
命令行有几个有用的。openclaw memory promote 预览推送候选,openclaw memory promote –apply 真正推送,openclaw memory promote-explain 解释为什么某个候选会或不会推送,openclaw memory rem-harness 预览 REM 反思。
如果梦境已开启,意味着你和 AI 聊天的内容,系统会在后台自动整理。聊的持仓数据、维基结构、记忆系统研究,这些短期信号会被 Light phase 暂存,Deep phase 会评估哪些值得推送到 MEMORY.md,REM phase 会提取主题和反思。
梦境的好处是,你不用手动把每个重要细节都写进 MEMORY.md。系统会自动帮你筛选。坏处是,推送是自动的,你可能不知道什么东西被推了、什么东西被过滤了。好在 DREAMS.md 会记录整理过程,你可以 review。
什么时候该开梦境?如果你希望 AI 自动整理记忆,不想手动维护 MEMORY.md,那就开。如果你希望完全控制什么进长期记忆,那就关,自己写。我自己是开着用的,省心。
维基不是记忆的替代品
维基和 MEMORY.md 的关系,可以用一个比喻。MEMORY.md 是你大脑里的长期记忆,维基是你写的笔记。你脑子里记得住的东西,不一定都写进笔记。但笔记里的东西,不一定都在脑子里。
很多新手会想,既然有了维基,那 MEMORY.md 是不是可以不要了。答案是绝对不行。
OpenClaw 的维基插件叫 memory-wiki,它编译的是一个结构化知识库。它有 entities(实体,比如人、公司、股票)、concepts(概念,比如资产配置方案)、syntheses(合成,比如持仓总览)、sources(原始材料)、reports(系统生成的报告,比如矛盾检查)。
每个页面都可以带 structured claims 和 evidence。比如紫金矿业 Q1 净利 200 亿这个 claim,可以追溯到具体的证据来源,可以标注置信度,可以标记是否被反驳。
这比 MEMORY.md 的纯文本强大得多,但代价是需要手动维护。维基不会自动从 MEMORY.md 同步内容,你得告诉 AI 要更新什么,两边都要改。
维基有两种运行模式。isolated 模式下维基自己管自己的内容,不依赖记忆插件,你清楚知道维基里有什么、为什么有。bridge 模式下维基会自动从记忆插件拉取内容,但你没法精确控制哪些内容进维基。
对于刚接触维基的用户,我建议先用 isolated 模式,手动同步,等用熟了再考虑 bridge 模式。
主动记忆–让 AI 自动查记忆
Active Memory 这个功能挺有意思。
传统的记忆系统是被动的。你得说「帮我查一下记忆」或者「记住这个」,记忆才会被搜索。但很多时候,最好的记忆时机已经过去了。
比如你说明天有个面试,传统系统不会主动在面试后问你面试怎么样。但 Active Memory 会。
Active Memory 的工作原理是,在你发消息之后、AI 回复之前,系统会偷偷跑一个子代理去搜索你的记忆,把相关内容塞进上下文里。你感觉不到这个过程,只觉得这个 AI 怎么记得住你上次说的事。
它有三个查询模式。message 模式只看你最新那条消息,速度最快。recent 模式看最新消息加最近几轮对话,最平衡。full 模式看完整对话历史,最慢。
它还有六种提示风格。balanced 是通用默认。strict 最保守,只返回明显相关的。contextual 最连续,对话历史权重高。recall-heavy 更愿意返回弱匹配的记忆。precision-heavy 只返回明显匹配的。preference-only 只返回偏好习惯常规。
多数用户适合用 recent 模式加 balanced 风格。日常聊天经常有上下文依赖,recent 能覆盖这些。preference-only 也适合,可以记住投资偏好、持仓习惯、公众号定位这些长期稳定的东西。
但这个功能默认不开启。原因很简单。如果你现有的记忆系统已经够用(MEMORY.md 加维基加梦境),主动记忆是锦上添花。而且它有额外延迟,每次回复都要等子代理搜记忆,recent 模式大概 800 到 1500 毫秒。我暂时没开,因为我比较在意回复速度。
什么时候该开?如果你觉得这个 AI 怎么老记不住你上次说的事,或者你希望每次聊天自动带上你的偏好和习惯,那就开。
Honcho–AI 原生的记忆服务
Honcho 是目前记忆体系里最重的一个。
Honcho 是一个 AI 原生的记忆服务,它把对话持久化到一个专门的服务里,然后自动构建用户画像和智能体画像。
它的核心卖点是跨会话记忆。传统记忆系统需要手动写 MEMORY.md,Honcho 会自动从对话里提取信息,跨会话记住你。
它提供的工具包括 honcho_context(跨会话的完整用户表示)、honcho_search_conclusions(语义搜索存储的结论)、honcho_search_messages(跨会话查找消息)、honcho_session(当前会话历史和摘要)、honcho_ask(问关于用户的问题)。
Honcho 和 builtin 记忆系统的区别很明显。builtin 的存储是工作区 Markdown 文件,跨会话靠手动维护文件,用户建模靠手动写 MEMORY.md。Honcho 的存储是专门服务,跨会话自动,用户建模自动画像。
但 Honcho 对大多数用户暂时不用。原因有几个。你只用一台设备,跨设备同步不是刚需。如果你已经有维基加 MEMORY.md,信息已经结构化存储了。持仓、资产配置、公众号运营这些敏感信息,传到第三方服务需要慎重。自托管 Honcho 需要额外运维成本。
我自己没装 Honcho,原因也很简单。我就一台电脑,没有跨设备的需求,现有的记忆方案已经够用了。
什么时候该用?你要在多设备间切换,或者你有多个智能体在协作需要共享记忆,或者你愿意自托管 Honcho 服务器确保数据在自己手里。
Commitments–AI 学会记住自己的承诺
Commitments 是目前记忆体系里最有意思的一个。
Commitments 是智能推断的短期跟进记忆。不是用户明确要求的提醒,而是 AI 从对话中感觉到应该在未来跟进的事情。
比如你说明天有个面试,你没说「提醒我」,但 Commitments 会在面试后主动问你面试怎么样。你说「今天累死了」,Commitments 会在第二天问你昨晚睡得好吗。AI 说「等收盘后我帮你分析」,Commitments 会在收盘后主动把分析给你。
它和定时任务的区别很重要。定时任务是用户明确要求的。下午 3 点提醒我开会、20 分钟后提醒我、每个工作日跑报表,这些都用定时任务。Commitments 是推断的。明天有个面试、今天累死了、收盘后帮我分析持仓,这些用 Commitments。
Commitments 的工作流程是,AI 回复之后,系统会跑一个隐藏的背景提取 pass,检查有没有应该跟进的事情。找到高置信度候选就存储 commitment,包括 agent id、session key、原始频道和交付目标、到期窗口、简短的跟进建议。到期时通过 heartbeat 触发,AI 可以主动发跟进消息,或者回复 HEARTBEAT_OK 忽略。
这个功能可以开,但先小范围试。最有价值的场景是跟进分析。如果你已经有收盘分析的 cron 任务,但某天你主动说「帮我看看今天持仓怎么样」,Commitments 可以在收盘后主动把分析推给你,不用你再来找 AI。
但要注意几个问题。每次回复后都要跑一个隐藏 pass 提取承诺,增加 token 消耗。跟进消息通过 heartbeat 发送,heartbeat 没开就收不到。只在创建时的 agent 加 channel 范围内生效,换频道就失效。到期窗口是大概时间,不是精确到分钟。每天最多 3 个,多了会被截断。
我自己还没开 Commitments,主要因为我现有的 cron 任务已经覆盖了定时提醒的需求。不过那个「收盘后主动推分析」的场景确实挺诱人的,以后可以试试。
九个模块怎么配合
研究了这么多,你可能会晕。MEMORY.md、每日笔记、梦境、维基、Builtin 引擎、QMD、Active Memory、Honcho、Commitments,这九个模块怎么配合?
MEMORY.md 是长期记忆,存持久化事实。每日笔记是原始素材,存当天对话记录。Builtin 引擎是记忆索引,把文件切成片段供搜索。QMD 是增强搜索,能索引外部目录和会话记录。维基是结构化知识库,存实体、概念、合成内容。梦境是后台整理层,自动把短期信号推送到长期记忆。Active Memory 是自动检索层,在你发消息时自动搜记忆。Honcho 是跨会话服务,自动构建用户画像。Commitments 是短期跟进,记住 AI 自己的承诺。
大多数用户的默认配置是。MEMORY.md 在用,每日笔记在用,Builtin 引擎默认开启。维基、梦境、QMD、Active Memory、Honcho、Commitments 都是可选模块,按需开启。
这个配置是合理的。MEMORY.md 加维基加梦境覆盖了大部分需求,Builtin 引擎在后台默默索引所有记忆文件,QMD 和 Active Memory 和 Honcho 是进阶选项,Commitments 可以开但先小范围试。
九个模块的时间尺度是这样的。Commitments 是分钟到小时级别,短期跟进。Active Memory 是秒级别,实时检索。每日笔记是天级别,当天记录。梦境是小时到天级别,后台整理。MEMORY.md 是周到天级别,长期记忆。维基是任意级别,结构化存储。Honcho 是跨会话级别,持久化服务。QMD 是随时可用,搜索增强。Builtin 引擎是时刻在跑,索引地基。
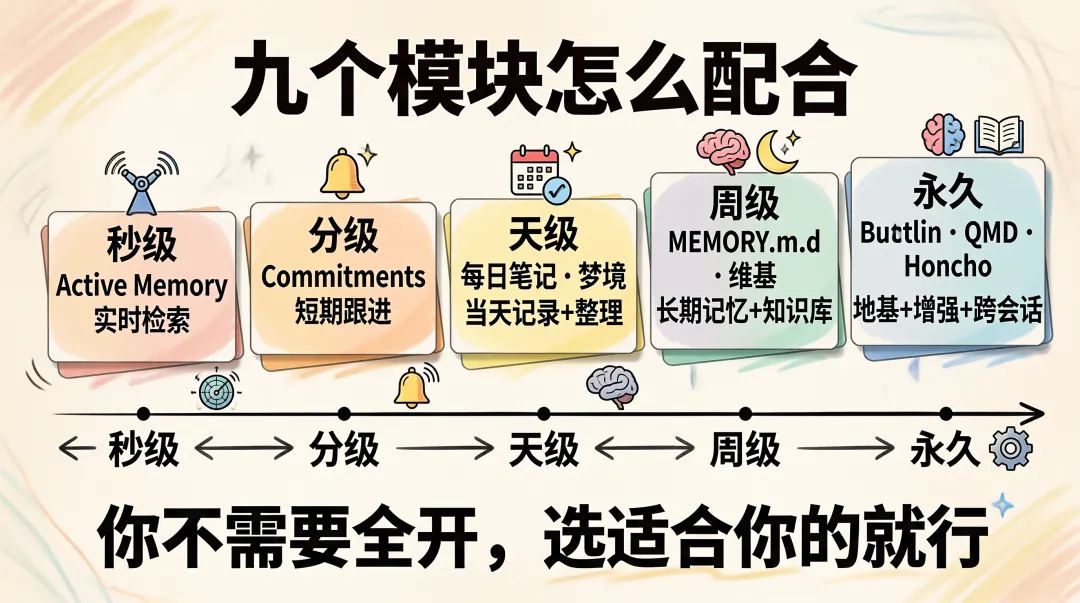
你不需要把所有模块都开了。选适合你场景的,剩下的放着就行。
最后说两句
记忆系统这东西,看着复杂,其实核心就一句话。OpenClaw 通过多层记忆架构,让 AI 能在不同时间尺度上记住你。短期靠 Commitments 和 Active Memory,中期靠每日笔记和梦境,长期靠 MEMORY.md 和维基,跨会话靠 Honcho,地基靠 Builtin 引擎,增强靠 QMD。
你不需要把所有系统都开了。选适合你场景的,剩下的放着就行。
我自己折腾了一圈下来,最深的感受是。OpenClaw 这套记忆体系,设计得确实用心。每个模块各管一摊,互不干扰,你需要什么就开什么。不是那种「我给你一个大而全的东西,你用不用都得扛着」的设计。
如果你也在用 OpenClaw,或者正准备用,希望这篇文章能帮你少走点弯路。
以上,如果觉得不错,随手点个赞、在看、转发三连吧。谢谢你看我的文章,我们,下次再见。
文章内容基于OpenClaw版本2026.5.12。
我的Openclaw教程