夜雨聆风
夜雨聆风





OpenClaw 拆解④丨Agent 的记忆系统和人脑一模一样,连「做梦」都有
这是 OpenClaw 架构拆解系列的第四篇。
前面聊了 Agent Loop 和 System Prompt,今天聊一个让我研究了两天的模块,Memory 系统。
我之前对 Agent 记忆的理解很朴素,要么全放在上下文窗口里(短期记忆),要么用 RAG 检索外部知识库(长期记忆)。
读完 OpenClaw 的记忆源码后,我发现事情比这复杂得多。
也有意思得多。
OpenClaw 的记忆分三层。
| 层级 | 名称 | 容量 | 速度 | 持久性 | 类比 |
|---|---|---|---|---|---|
| L1 | ContextEngine | ~100K tokens | 即时 | 会话级 | RAM |
| L2 | MEMORY.md | 无限 | 文件 I/O | 永久 | Flash |
| L3 | MemorySearch | 无限 | 检索 | 永久 | 搜索引擎 |
L1 是当前对话的上下文,全部在 token 窗口里。优点是即时可用,不需要额外操作。缺点是容量有限(受 token 预算约束),会话结束就没了。
L2 是持久化的 Markdown 文件。MEMORY.md 存永久性的事实和偏好,memory/YYYY-MM-DD.md 存每日笔记,DREAMS.md 存整理回顾的结果。三种文件,三种时间尺度。
L3 是语义检索层。你不需要记住信息在哪个文件的第几行,描述一下你要找什么,它帮你从所有记忆中检索相关内容。
💡 容量从小到大,速度从快到慢,持久性从弱到强。这就是经典的存储金字塔。计算机科学 70 年反复验证的层级设计,Agent 框架又重新发明了一遍。
📝 MEMORY.md 的文件格式,刻意的简单
MEMORY.md 不是 JSON。不是 YAML。不是任何结构化格式。
它就是纯 Markdown。
没有 frontmatter,没有特殊语法,没有 schema 约束。想写啥写啥。
## 用户偏好
- 喜欢简洁的回复风格
- TypeScript > JavaScript
- 用 pnpm 不用 npm
## 项目决策
- 数据库选了 PostgreSQL,因为需要 JSONB 支持
- 放弃了 MongoDB,因为团队不熟悉
## 经验教训
- 上次部署忘了跑 migration,记得检查反直觉 纯 Markdown 看似不利于程序化处理,但实际上有三个好处。第一,LLM 本身就是最好的「非结构化文本解析器」,不需要 schema。第二,用户可以直接手动编辑记忆文件,像改 README 一样简单。第三,避免了格式迁移问题,JSON 的 schema 变了要写 migration 脚本,Markdown 不用。
这是一种「LLM-native 设计」。当你的读者既有人类又有 LLM 的时候,Markdown 可能是最好的折中格式。它对人类友好(可读可写),对 LLM 也友好(自然语言嵌入结构)。
写入规则也很有意思。什么应该存,什么不应该存?
应该存的是持久性事实、用户偏好、项目决策、反复出现的模式。
不应该存的是临时性的跟进任务、一次性操作的细节。
判断标准只有一个,这个信息下次还有用吗?
🔍 QMD 双模搜索,渐进增强
L3 的语义检索有两个搜索模式。
源码在 extensions/memory-core/src/memory/qmd-manager.ts。
| 模式 | 底层引擎 | 适用场景 |
|---|---|---|
search |
BM25 词法检索 | 精确关键词匹配 |
vsearch / query |
向量检索 | 语义相似度搜索 |
判断逻辑一行代码就说完了。qmdUsesVectors(searchMode) => searchMode !== "search"
只要不是 search 模式,就走向量检索。
但这里有个关键设计,向量检索是可选增强,不是必需依赖。
QMD Manager 暴露了 probeVectorAvailability() 方法,运行时探测向量服务是否可用。如果不可用,自动降级到 BM25。Embedding 模型通过环境变量 QMD_EMBED_MODEL 配置,代码里不硬编码。
💡 这是经典的「渐进增强」设计。基线是 BM25 文本搜索(零外部依赖),向量检索是可选升级(需要 embedding 服务)。就像 Web 开发的 Progressive Enhancement 哲学,先保证基本功能可用,再逐步增强。
反直觉 BM25 虽然不是向量检索,但已经是很成熟的信息检索算法了。它是 TF-IDF 的改进版,在大多数「回忆」场景下效果足够。向量检索只在语义跨度很大的场景才真正必要。比如用户问「我之前怎么处理数据库的」,BM25 靠「数据库」这个关键词就能找到。但如果用户问「我之前那个性能优化的思路」,没有明确关键词,这时候向量检索的语义匹配才会明显优于 BM25。
🔄 Compact,LLM 驱动的「记忆巩固」
当 L1 的对话历史快要撑爆 token 预算的时候,就需要压缩。
Compact 的实现在 src/agents/pi-embedded-runner/compact.ts。桥接层在 src/context-engine/delegate.ts。
流程是这样的。
- 1.
delegateCompactionToRuntime()被 ContextEngine 调用 - 2. 内部调用
compactEmbeddedPiSessionDirect() - 3. 构建完整的
buildEmbeddedSystemPrompt()+ 运行时 prompt contribution - 4. Memory 指导通过
buildMemoryPromptSection()注入 - 5. 把完整 System Prompt + 全部对话历史发给 LLM
- 6. LLM 生成摘要,替代原始历史
你注意到了吗?第 3 步是构建完整的 System Prompt。
不是一个精简的「请总结以下对话」。而是带着完整角色定义、工具列表、行为规范的 System Prompt。
为什么要这么奢侈?
因为如果 LLM 在压缩时不知道自己是谁、能做什么,它生成的摘要就会「跑偏」。一个不知道自己是代码助手的 LLM,在总结编程对话时可能会忽略代码细节,只保留自然语言部分。这对后续的编码任务是致命的。
反直觉 压缩操作比正常对话更贵(因为要发完整 System Prompt + 全部历史),但这是正确的设计。用短期 token 成本换长期摘要质量。就像 PostgreSQL 的 VACUUM,清理死元组需要读取完整的表结构信息。
压缩后还有一个关键步骤,repairToolUseResultPairing()。
压缩可能在 tool_use 和 tool_result 之间截断对话,导致「孤儿调用」。这个修复函数会扫描 transcript,缺失的 result 插入合成占位,重复的删除,孤儿的丢弃。
💡 这和文件系统的 fsck 是同一个东西。ext4 日志在 crash 后可能留下不完整的事务,fsck 通过扫描+修复保证一致性。
repairToolUseResultPairing就是 Prompt Transcript 的 fsck。
💤 events.jsonl,Agent 真的在「做梦」
这是整个拆解过程中让我最惊叹的发现。
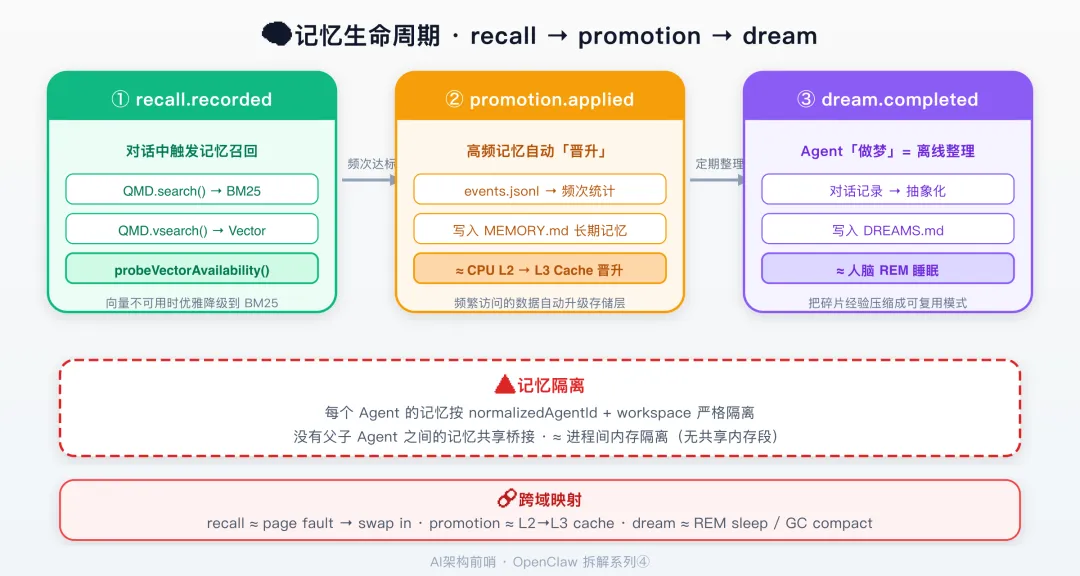
在 memory/.dreams/events.jsonl 文件中,OpenClaw 记录了三种事件。
| 事件 | 触发时机 | 记录内容 |
|---|---|---|
memory.recall.recorded |
每次检索记忆 | query, resultCount, results[{path,score}] |
memory.promotion.applied |
短期→长期提升 | memoryPath, candidates[{key,score,recallCount}] |
memory.dream.completed |
记忆整理完成 | phase, reportPath, lineCount, storageMode |
recall → promotion → dream。
检索 → 巩固 → 整合。
你不觉得这三个阶段和人脑的记忆巩固过程惊人地相似吗?
工作记忆中的信息被反复检索(recall)。被频繁检索的信息被标记为「重要」,由海马体转移到皮层(promotion)。然后在睡眠期间,大脑对这些信息进行重组整合(dream)。
OpenClaw 甚至把这个目录叫 .dreams。
我不确定起名的人是不是有意为之,但 recallCount 这个字段暴露了设计意图,一条记忆被检索的次数越多,被 promote 的概率越高。这就是人脑的「间隔重复」效应。
💡
events.jsonl是 append-only 日志,不可变。当前记忆状态是所有事件的「投影」。这就是事件溯源(Event Sourcing)模式。任何记忆变更都可以通过回放事件日志来审计和重建。
🔒 多 Agent 记忆隔离
最后聊一个我本来以为很简单但其实设计很深的问题,多个 Agent 共享记忆吗?
答案是,不。
源码在 extensions/memory-core/src/memory/search-manager.ts。
每个 Agent 的 Memory Manager 按 normalizedAgentId + workspace 作为 key,完全独立。
| 场景 | 记忆可见性 |
|---|---|
| 同一 Agent 不同会话 | ✅ 共享 |
| 父 Agent → 子 Agent | ❌ 隔离 |
| 子 Agent → 父 Agent | ❌ 隔离 |
| 不同用户同 Agent | ❌ 隔离 |
反直觉 子 Agent 不能读取父 Agent 的记忆。看起来不合理(子任务应该继承上下文),但这是安全隔离的刻意选择。
信息传递不通过共享记忆,而是通过 prepareSubagentSpawn() 时显式传递的 context。
这个模型和 Android 的进程隔离几乎一模一样。
agentId ≈ Linux UID。
workspace ≈ /data/data/<package>/。
显式 context 传递 ≈ Binder IPC。
默认隔离,需要共享就走显式的通信通道。Unix 的 fork() 也是这样,子进程拿到的是内存快照副本,不是共享指针。想共享就用 pipe / shared memory / socket,显式声明意图。
回顾一下,OpenClaw 的记忆系统。
三层架构 ≈ 存储金字塔。
MEMORY.md 纯 Markdown ≈ LLM-native 设计。
QMD 双模搜索 ≈ 渐进增强。
Compact 复用完整 Prompt ≈ MVCC 快照读。
events.jsonl 三阶段 ≈ 人脑记忆巩固。
多 Agent 隔离 ≈ Android 进程模型。
每一个设计决策,都能在计算机科学或者认知科学中找到对应的原型。
这不是巧合。好的 Agent 记忆系统,归根结底就是在解一个跨了几十年的老问题,怎么在有限的快速存储上高效管理「什么该记住、什么该忘掉」。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。