 夜雨聆风
夜雨聆风





MinerU-Popo来了:让文档解析从“看懂每页”走向“读懂整篇”

近年来,以 MinerU 为代表的智能文档解析系统,已经能在单页范围内识别标题、正文、图片、表格等元素,并输出文本内容、边界框和阅读顺序。
这种方式已经能很好地回答“这一页有什么”,但是 RAG、知识库和 Agent 工作流真正需要的,不只是每一页识别出了哪些文字和表格,更是整篇文档能否被还原成连续、准确、可检索、可分析的文档级语义结构。
日前,上海人工智能实验室OpenDataLab团队联合上海交通大学等单位提出 MinerU-Popo,一个面向 OCR 输出的轻量、通用后处理框架,基于4B 参数的微调模型,适用于修复跨页表格合并、跨页段落拼接、标题层级补齐、图文关联问题,可以将页面级解析结果转化为连贯的、可用于检索和分析的文档树结构,有效增强各类文档解析模型能力。
MinerU-Popo 支持本地私有化部署,模型轻量高效,适合大规模文档处理场景,欢迎使用。

技术报告:
https://arxiv.org/abs/2605.24973
代码仓库:
https://github.com/opendatalab/MinerU-Popo
开源模型:
https://huggingface.co/DreamEternal/MinerU-Popo

要解决跨页表格合并、跨页段落拼接、标题层级补齐、图文关联问题,传统做法要么继续提升单页 OCR 精度,要么用规则拼接段落、归并标题或合并表格。但前者受限于页面边界,后者面对金融报告、学术论文、政务材料、医疗文书等多样版式时,往往难以泛化和持续迭代。
更重要的是,不同 OCR 系统的输出标签、元素粒度和结构格式并不完全一致,单独为每个系统维护一套后处理逻辑,成本高且复用性有限。
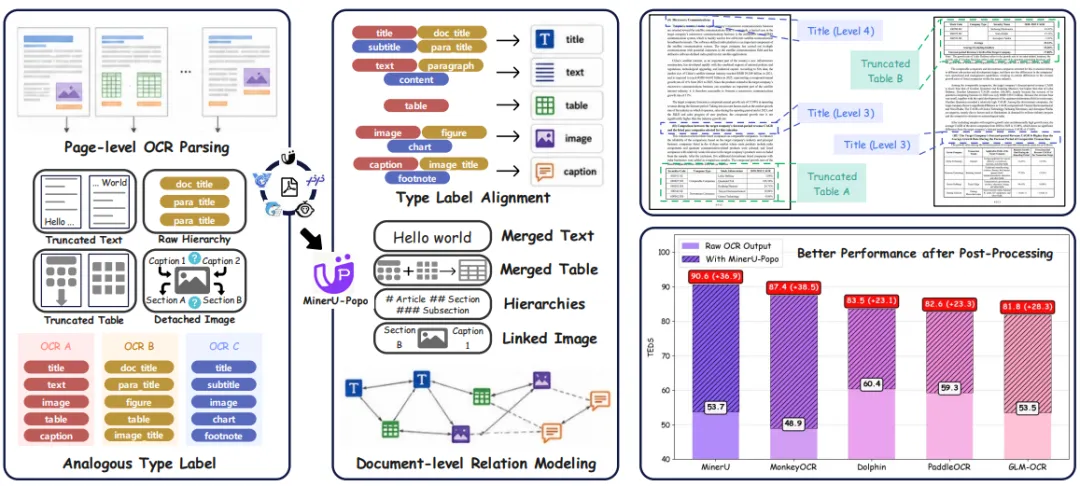
MinerU-Popo 的思路更直接,不是重新训练一个庞大的端到端文档解析系统,也不是让模型把 PDF 再识别一遍,而是选择复用已有 OCR 或版面解析模型的页面级结果,并在统一标签空间中进一步恢复文档级逻辑结构。通过标签对齐机制支持对接多种主流 OCR 系统——不同 OCR 模型的输出标签可以通过轻量规则归一化为统一标准(如 title、text、image、table 等),从而实现即插即用。

MinerU-Popo 将文档后处理拆解为四个核心任务:文本截断恢复、表格截断恢复、标题层级重建和图文关联。通过这些任务,它可以判断断开的段落是否应合并,分页表格是否属于同一张表,标题之间的父子关系如何组织,以及图片、表格与 caption 应该挂载到哪个章节下。
围绕这些任务,MinerU-Popo 设计了面向任务的数据引擎、动态分块与同步、文档丰富化三大模块:先筛掉无关元素,再处理长文档分块边界,最后生成文档树和节点摘要,让输出更适合检索、问答和分析。
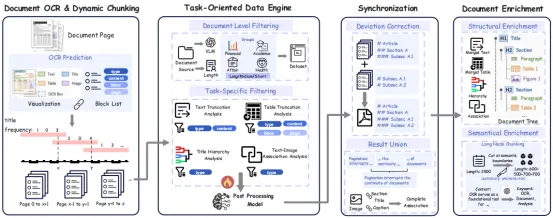
1. 面向任务的数据引擎:先筛出真正有用的信息
训练数据质量直接影响模型效果。MinerU-Popo 会先从大规模真实 OCR 文档中,利用 VLM 按视觉外观、版面特征、文档格式、内容领域和页面长度等维度进行筛选,并按领域和长度分组采样,确保数据覆盖金融、学术、政务、医疗等多种文档类型。
随后,它会针对不同子任务做任务特定过滤:标题层级分析主要保留 title,图文关联保留 title、caption、image、table,文本截断只关注候选文本块的首尾句,表格截断则重点定位页面边界处的表格候选对。这样模型不必处理整篇文档里的所有冗余信息,而是聚焦最相关的结构线索。
2. 动态分块与同步:让长文档既能切开处理,又保持全局一致
即使经过过滤,长文档仍然很难一次性处理。简单固定分块又会带来新问题:分块边界处的文本截断可能被漏掉,后续块也可能因为缺少全局标题上下文而误判章节层级。
为此,MinerU-Popo 采用动态分块与同步策略:通过三页重叠分块保留跨页参考信息,在搜索窗口内动态确定分块边界;再利用重叠区域中相同元素的预测结果计算层级偏差,校正后续块预测;对不涉及层级偏差的任务,则合并各块结果。消融实验显示,这一策略使标题层级 TEDS 从 85.8% 提升至 90.6%,文本截断召回率从 86.6% 提升至 93.8%。
3. 文档丰富化:把预测结果组装成可用的文档树
模型完成段落连接、表格合并、标题层级和图文关联预测后,还需要把结果转成下游真正能用的文档表示。
MinerU-Popo 会基于标题层级构建章节父子关系,把文本段落、合并后的表格和关联图片挂载到对应章节节点下,形成结构化文档树。为了让这棵树更适合检索和分析,它还会做语义丰富化:当节点内容过长时,在段落边界处切分;当标题过短、检索粒度不足时,利用 LLM 为节点生成摘要,提炼关键论点、方法、趋势或结论。最终得到的文档树兼顾结构、粒度和信息完整性,可为 RAG、问答和文档分析提供高质量输入。

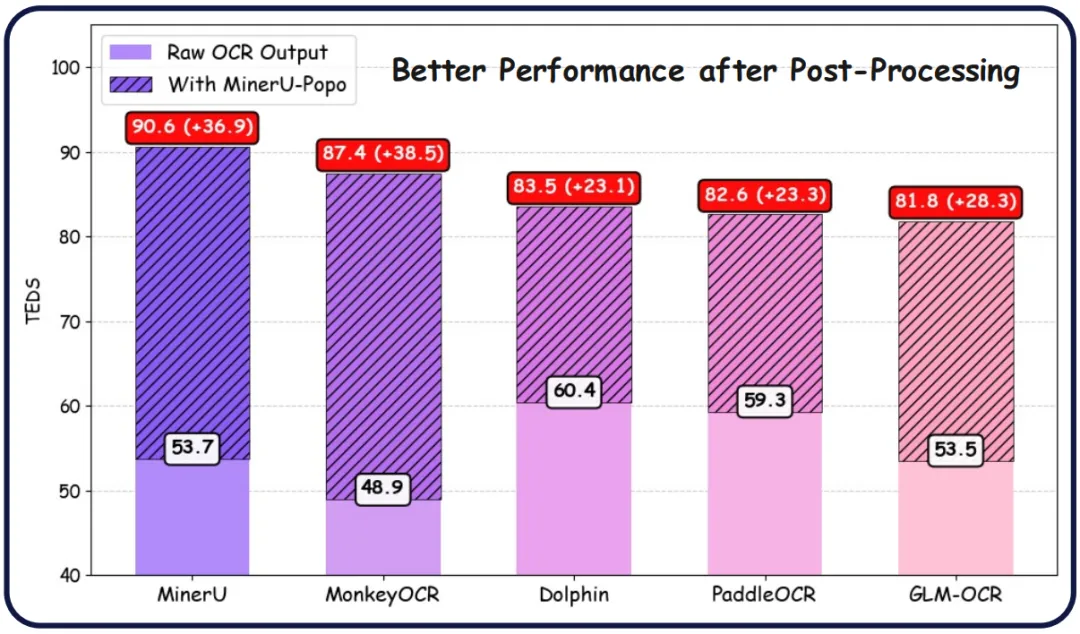
实验显示,五种主流 OCR 模型经过 MinerU-Popo 后处理后,标题层级 TEDS 提升均超过 20 个百分点。充分验证了后处理框架的通用性和有效性。
在完整训练集上,MinerU-Popo :
● 文本截断分析精确率 87.8%、召回率 93.8%;
● 图文关联分析精确率 87.0%、召回率 79.5%;
● 标题层级 TEDS 达到 90.6%;
● 表格截断合并方法预测准确率 92.7%。
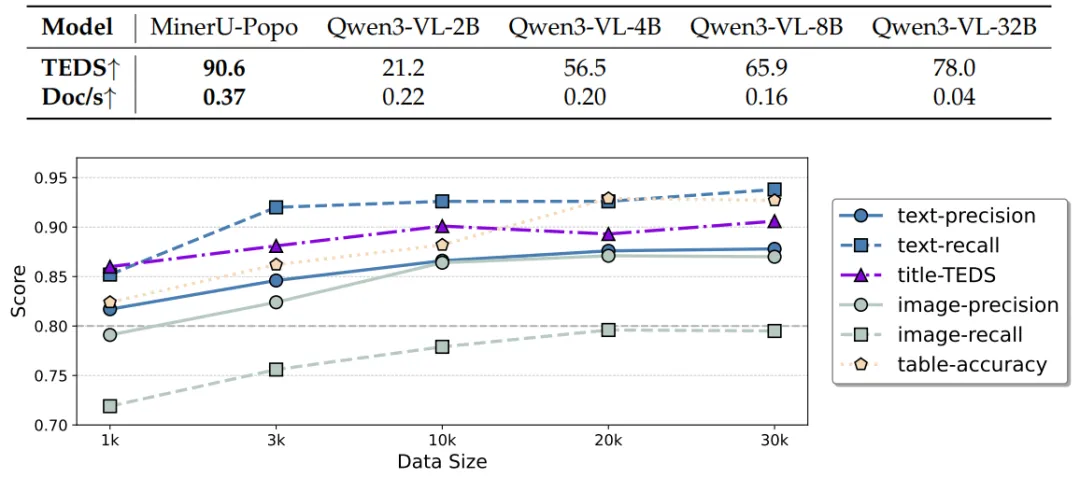
更有意思的是,MinerU-Popo 以 4B 参数量超越了 32B 的无微调通用模型(90.6 vs. 78.0),同时推理速度是同等规模模型的近两倍(0.37 vs. 0.20 文档/秒)。
下游检索分析与直接问答任务中,经过 MinerU-Popo 后处理后的文档结构,在多个 RAG 子集上超过原始 OCR 基线,并通过更简洁的节点标题和摘要降低检索延迟。

在端到端问答任务中,从文档树导出的 JSON 和 Markdown 格式也取得了更好的整体准确率。
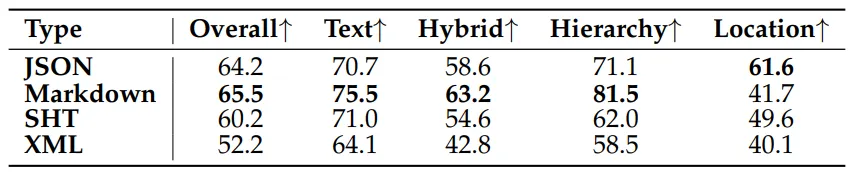
这意味着,MinerU-Popo 解决的并不是“多识别几个字”的问题,而是复杂文档进入知识库和 Agent 工作流后,信息能被稳定召回、准确理解、可靠使用。

从 MinerU2.5 到 MinerU-Popo,文档解析正在从单页精度竞争,进一步走向文档级语义结构恢复。前者让模型更准确地看懂页面,后者让系统更完整地读懂整篇文档。
面向未来,复杂文档能否高质量转化为 AI-Ready 数据,将直接影响大模型应用的可用性。MinerU-Popo 正是在这条链路上补上关键一环:让页面级 OCR 输出,真正变成可检索、可分析、可进入智能工作流的文档结构。
技术报告:
https://arxiv.org/abs/2605.24973
代码仓库:
https://github.com/opendatalab/MinerU-Popo
开源模型:
https://huggingface.co/DreamEternal/MinerU-Popo
END
它来了!MinerU 2.5-Pro 正式上线 SaaS 端,解锁 Office 全能解析新战力
2026-05-13

科学智能数据库 Sciverse 正式发布:让科学数据成为 Agent 可调用的资源
2026-03-30

j2026-05-20
