 夜雨聆风
夜雨聆风





Word2Vec原理大白话讲解
🤔 想过这个问题吗?
你跟手机说”我饿了”,它能猜你想吃什么;你打”今天天”,它会蹦出”气””真好”。
电脑明明只认 0 和 1,它是怎么知道”汉堡”和”披萨”是一类东西,”苹果”和”香蕉”是一类东西的?
答案藏在一个叫 Word2Vec(词转向量)的小魔法里。
🎯 一句话先讲清楚
Word2Vec 就是一个”翻译器”:
👉 把人类用的”词”,翻译成电脑能算的”一串数字”。
而且翻译得特别巧妙——意思相近的词,数字也长得像。
第一步:先学会”用数字描述一个人”
咱们先放下”词”,从描述一个人开始。
假如让你用 一个数字 来形容你朋友小王,你会怎么打分?比如外向程度,0 分最内向、100 分最外向。小王打 70 分。
小王 = 70
但光一个”外向程度”太单薄了。再加一个数字——比如”爱不爱冒险”,小王打 30 分:
小王 = 外向 70冒险 30
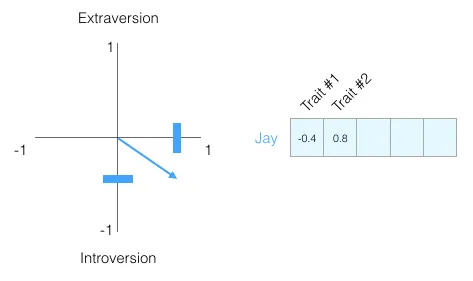
图:用两个数字描述一个人,可以画在平面上
再多加几个维度,比如”爱聊天””有耐心””爱学习””脾气好不好”……一共 5 个数字,是不是就比一句话描述得更清楚了?
💡 这里有个特别厉害的地方:
两个人长得像不像?只要他们的这串数字长得像,那他们性格就像。
比如小王是 [70, 30, 80, 50, 90],小李是 [72, 28, 78, 52, 88]——一看就是同款人!
这个”用一串数字描述一样东西”的方法,专业上叫 嵌入(Embedding)。听着唬人,其实就是给每个东西发一张”数字身份证”。
第二步:给每个”词”也发一张身份证
既然人能用一串数字描述,那词当然也能。
下面是真实训练出来的”king(国王)”这个词的身份证(50 个数字):
[ 0.50, 0.69, -0.60, -0.02, 0.60, -0.13, -0.09, 0.47, -0.62, -0.31, -0.08, 1.49, -0.03, -0.98, 0.68, 0.82, ...... -0.64, -0.51 ] ← 这就是 king 这个词
数字看不懂?没事,把它染上颜色就一目了然了——数字越大越红,越小越蓝:

图:king 这个词的”数字身份证”,用颜色画出来就是这样
把 king(国王)、man(男人)、woman(女人)三张身份证摆一起对比:

图:king/man/woman 的身份证对比,竖着看会发现某些”列”长得很像
👀 仔细看这张图:
• king 和 man 在某几列颜色几乎一样 → 都是“男性”属性
• woman 和 girl 整体很像 → 都是“女性”属性
• 这些数字把词的”意思”都偷偷编码进去了!
最神奇的彩蛋:词可以做加减法 🤯
真正的魔法来了。既然词都变成数字了,那能不能加减?
king 👑 − man 🧔 + woman 👩 = ?
人话翻译:把”国王”减掉”男性”再加上”女性”,会得到什么?
答案:queen 👸(女王)
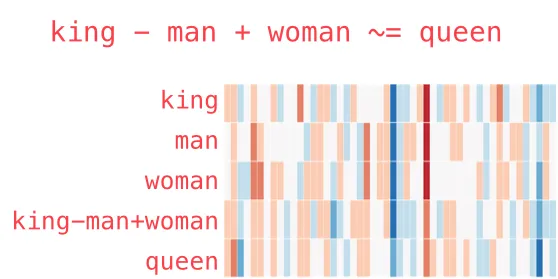
图:词的加减法在几何上是这样的——国王减男性的方向,加上女性的方向,正好落到女王附近
是不是有点小震撼?这说明 Word2Vec 不光把词变成了数字,还把词与词之间的关系也偷偷学到了!
那它到底是怎么”学会”的?
关键问题来了:电脑是怎么自己学出这些神奇的数字的?
核心思想就一句话:
🌟 “看一个词跟谁是邻居,就知道它是啥意思” 🌟
—— 这叫”分布假说”,是语言学的老观点了
举个例子。你不认识”鳟鱼”这个词,但如果天天看到这种句子:
• 我去钓鳟鱼了
• 这条鳟鱼真好吃
• 鳟鱼生活在清澈的河里
你不用查字典也能猜到——这是某种”鱼”。Word2Vec 学的就是这个套路。
🎮 训练过程:玩一个”猜邻居”的游戏
电脑打开海量文本(维基百科、几百万本书……),玩一个简单的小游戏:
- 开个滑动窗口
:每次只看 5 个词的小段落,比如”我 喜欢 吃 红色 苹果” - 盯住中间那个词
:”吃” - 问电脑
:”吃”周围最可能出现哪些词? - 对答案
:实际邻居是”我、喜欢、红色、苹果” - 调整身份证
:电脑发现自己猜错了,就把”吃”和那 4 个词的身份证各微调一点点,让它们更”靠近”
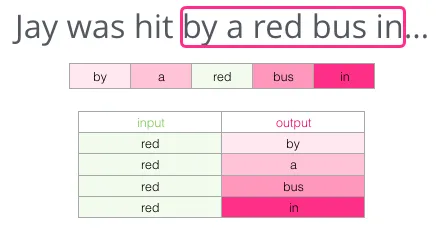
图:每个滑动窗口拆出”中心词 → 邻居词”这样的训练样本
这个游戏在海量文本上玩个几亿次,神奇的事情就发生了:经常一起出现的词,身份证就越来越像。”猫”和”狗”老在养宠物的句子里一起出现 → 它俩身份证变像;”皇帝”和”国王”老在历史书里一起出现 → 它俩身份证也变像。
🎯 这种”中心词猜邻居”的玩法叫 Skip-Gram。
另一种反过来——”邻居们猜中间词”——叫 CBOW(连续词袋)。原理一样,方向反了。
一个聪明的小优化:负采样
原本的训练有个大问题——太慢了。
你想啊,每次让电脑回答”吃 这个词后面接什么”,它要从词典里 10 万个词里挑一个,每次都做一遍 10 万选 1 的题,这怎么扛得住?
💡 聪明人想了个办法:把”选择题”改成”判断题”!
原来:吃 → ?(10 万选 1,超慢)
现在:吃 + 苹果 → 是邻居吗?是 / 否(2 选 1,超快)
但这又有个问题——训练样本里全是”是”(因为都是真实句子里挑出来的真邻居)。电脑会偷懒:管你问啥,我都答”是”,正确率 100%。这没学到东西。
怎么办?人造一些”假邻居”。从词典里随便抽几个词配进去,告诉电脑”这是假的”:
真 吃 + 苹果 → 是邻居 ✅
假 吃 + 火箭 → 不是邻居 ❌
假 吃 + 量子 → 不是邻居 ❌
这就是大名鼎鼎的负采样(Negative Sampling)。配上 Skip-Gram,就是 Word2Vec 真正的训练方法,叫 SGNS。
📌 一张图看懂全过程
🔄 Word2Vec 训练流水线
1. 给每个词随机发一张身份证(一串随机数字)
2. 翻开海量文本,开滑动窗口
3. 制造正样本(真邻居)+ 负样本(假邻居)
4. 让电脑判断:是不是邻居?
5. 答错了?把相关词的身份证微调一下
6. 重复几亿次,身份证就越来越靠谱
7. 🎉 训练完成!把所有身份证保存下来 = Word2Vec 词向量
🌍 这玩意儿能干啥?
别小看这串数字,它是现代 AI 的地基:
🔍 搜索引擎:你搜”减肥食谱”,它能找到讲”轻食套餐”的文章——因为这俩词向量很像
🎵 推荐系统:网易云、Spotify 不光把”词”变向量,还把”歌””用户”都变向量,给你推相似的
🛒 电商推荐:阿里、Airbnb 用同样思路把”商品””房源”变向量
🤖 所有现代 AI:ChatGPT、文心一言、豆包……它们的”理解词”的第一步,本质都是 Word2Vec 思想的升级版
📝 30 秒回顾
① 核心点子:给每个词发一张”数字身份证”
② 训练方法:看大量文本,让”经常一起出现的词”身份证变像
③ 加速诀窍:把”猜词”改成”判断真假邻居”
④ 神奇彩蛋:词可以加减——国王−男+女=女王
⑤ 它的意义:第一次让电脑真正”理解”了词与词的关系