 夜雨聆风
夜雨聆风





【AI模型小百科】文档分块策略与语义切分算法——提升RAG检索质量的关键
一、引言:为什么分块策略决定RAG效果上限
在RAG(Retrieval-Augmented Generation)系统中,文档分块(Chunking)是连接原始数据与向量检索的核心桥梁。无论你的Embedding模型多强大、向量数据库多高效,如果分块质量不佳,检索到的上下文就会语义破碎或噪声泛滥,最终生成的回答也难以令人满意。
分块本质上是一个信息粒度控制问题:块太大,语义稀释,检索精度下降;块太小,上下文断裂,生成模型无法理解完整含义。可以说,分块策略直接决定了RAG系统的“检索天花板”。
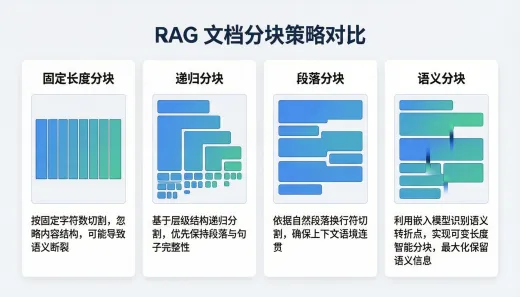
图1:不同分块策略对比示意图
二、传统分块方法
1. 固定长度分块
最简单直接的方式——按字符数或Token数将文档等分为固定大小的块。实现简单,但忽略了文档的语义结构,容易在句子中间截断。
def fixed_size_chunk(text, chunk_size=512, overlap=50):"""固定长度分块,支持重叠窗口"""chunks = []start = 0while start < len(text):end = start + chunk_sizeif end < len(text):last_period = text[start:end].rfind('。')if last_period > chunk_size * 0.8:end = start + last_period + 1chunks.append(text[start:end])start = end - overlapreturn chunks
2. 递归字符分块
LangChain默认采用的策略。使用一组分隔符(\n\n、\n、。、空格)依次尝试切分,若切分结果仍超过目标大小,则递归使用更细粒度的分隔符继续切分。
from langchain.text_splitter import RecursiveCharacterTextSplittersplitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=80,separators=["\n\n", "\n", "。", "!", "?", ".", " "])chunks = splitter.split_text(document)
3. 段落分块
以自然段落(双换行符)为边界进行切分。优点是保持段落级语义完整性,适合结构清晰的文档。缺点是段落长度差异大,可能产生过长或过短的块。
三、语义分块:基于语义相似度的智能切分
语义分块(Semantic Chunking)是当前最前沿的分块策略。其核心思想是:不依赖固定规则,而是根据相邻句子之间的语义相似度变化来动态确定切分边界。当相邻两个句子的语义相似度突然下降时,说明文档的主题发生了转换,此处应当插入分块边界。
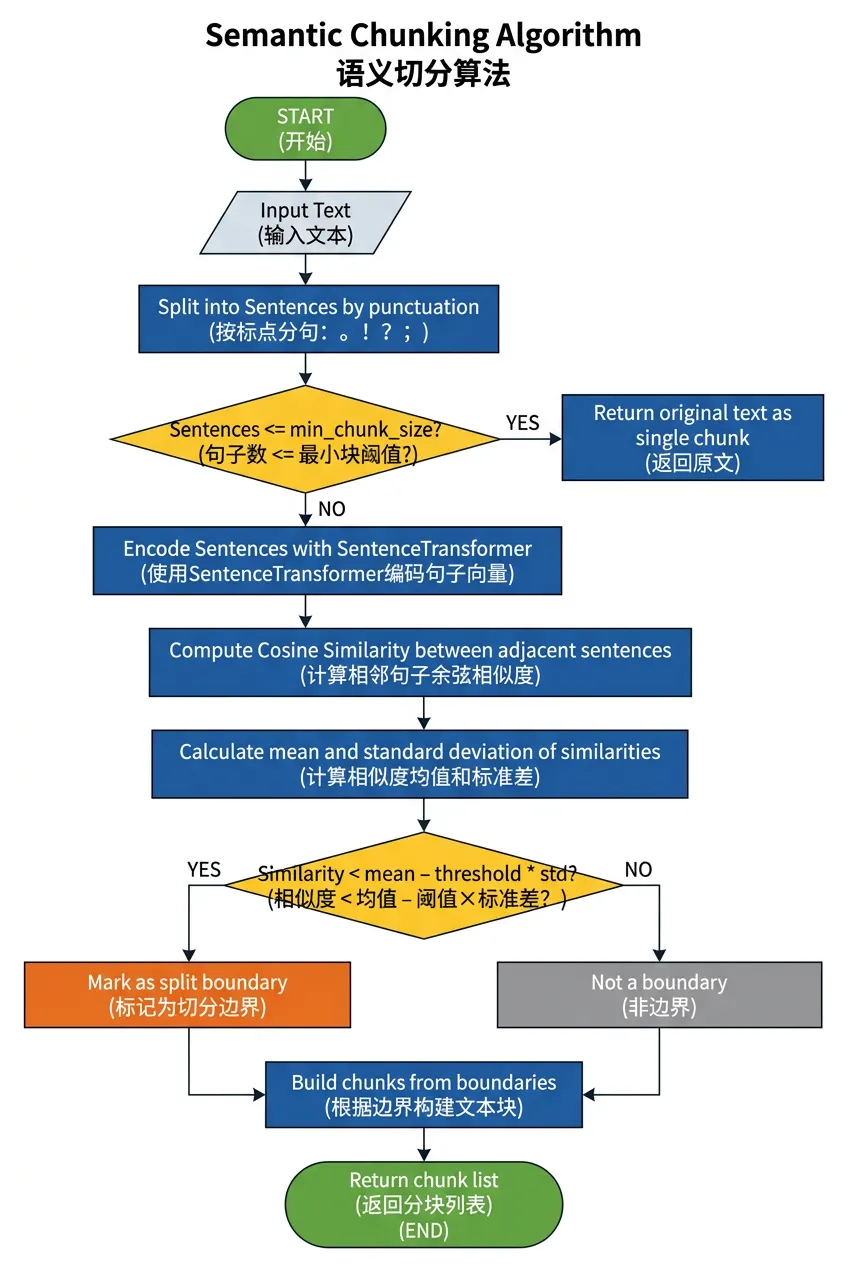
图2:语义切分算法流程图
算法流程
1.句子切分:将文档切分为句子序列 [s1, s2, …, sn]
2.向量编码:对每个句子计算Embedding向量 [e1, e2, …, en]
3.相似度计算:计算相邻句子对的余弦相似度 sim(ei, ei+1)
4.边界检测:识别相似度显著下降的位置作为分块边界
5.块合并:将边界之间的句子合并为语义一致的文档块
核心实现
import numpy as npfrom sentence_transformers import SentenceTransformerclass SemanticChunker:def __init__(self, model_name='BAAI/bge-small-zh-v1.5',similarity_threshold=0.5, min_chunk_size=2):self.model = SentenceTransformer(model_name)self.threshold = similarity_thresholdself.min_chunk_size = min_chunk_sizedef split_sentences(self, text):import resentences = re.split(r'(?<=[。!?;])\s*', text)return [s.strip() for s in sentences if s.strip()]def compute_similarity_drops(self, embeddings):similarities = []for i in range(len(embeddings) - 1):sim = np.dot(embeddings[i], embeddings[i + 1]) / (np.linalg.norm(embeddings[i]) *np.linalg.norm(embeddings[i + 1]))similarities.append(sim)if not similarities:return []mean_sim = np.mean(similarities)std_sim = np.std(similarities)drops = []for i, sim in enumerate(similarities):if sim < mean_sim - self.threshold * std_sim:drops.append((i + 1, sim))return dropsdef chunk(self, text):sentences = self.split_sentences(self, text)if len(sentences) <= self.min_chunk_size:return [text]embeddings = self.model.encode(sentences, normalize_embeddings=True)drops = self.compute_similarity_drops(embeddings)boundaries = [0] + [d[0] for d in drops] + [len(sentences)]chunks = []for i in range(len(boundaries) - 1):chunk_sents = sentences[boundaries[i]:boundaries[i + 1]]if len(chunk_sents) >= 1:chunks.append(''.join(chunk_sents))return chunks
上述实现使用了自适应阈值法——基于相似度分布的均值和标准差来动态确定切分阈值,而非使用固定的硬阈值。这使得算法对不同风格的文档具有更好的适应性。
四、高级策略
层次化分块
对于长文档或结构化文档(如论文、技术手册),可以采用层次化分块策略:先按章节(H1/H2标题)粗分,再在章节内部进行语义细分。检索时,可以结合“小块检索 + 大块上下文”的方式,即命中细粒度块后,将其所属的粗粒度块整体作为上下文返回给生成模型。
def hierarchical_chunk(markdown_text):"""层次化分块:章节 -> 段落 -> 语义块"""import resections = re.split(r'\n(?=#{1,3}\s)', markdown_text)hierarchy = []for section in sections:header_match = re.match(r'(#{1,3})\s+(.*)', section)header = header_match.group(2) if header_match else ""body = section[header_match.end():] if header_match else sectionsub_chunks = SemanticChunker().chunk(body.strip())hierarchy.append({"section": header,"chunks": sub_chunks,"full_text": section # 保留完整章节})return hierarchy
重叠策略优化
传统的固定重叠(如overlap=50)可能导致跨块语义断裂。更优的做法是基于句子边界的语义重叠:让前一块的末尾句子与后一块的开头句子保持重叠,确保跨块信息的连续性。
元数据增强
为每个文档块附加结构化元数据(来源文件名、页码、章节标题、创建时间等),在检索时支持元数据过滤,显著提升检索精度。
chunk.metadata = {"source": "technical_manual.pdf","page": 42,"section": "3.2 系统架构","chunk_id": "doc_042_chunk_03","parent_chunk": "section_3" # 支持层次化检索}
五、评估方法:如何量化分块效果
分块质量的评估需要结合内在指标和外在指标。
内在指标关注分块本身的语义一致性:
def chunk_coherence_score(chunker, text):"""评估分块语义一致性:块内相似度均值 / 块间相似度均值"""chunks = chunker.chunk(text)embeddings = chunker.model.encode(chunks, normalize_embeddings=True)intra_scores = []for chunk in chunks:sents = chunker.split_sentences(chunk)if len(sents) < 2:continuesent_embs = chunker.model.encode(sents, normalize_embeddings=True)for i in range(len(sent_embs) - 1):intra_scores.append(np.dot(sent_embs[i], sent_embs[i + 1]))inter_scores = []for i in range(len(embeddings) - 1):inter_scores.append(np.dot(embeddings[i], embeddings[i + 1]))intra_mean = np.mean(intra_scores) if intra_scores else 0inter_mean = np.mean(inter_scores) if inter_scores else 0return intra_mean / (inter_mean + 1e-8)
外在指标则通过端到端的RAG管道效果来评估:包括检索召回率(Recall@K)、命中率(Hit Rate)以及最终生成答案的准确率。通常使用标注的QA数据集来计算这些指标。
六、对比分析与最佳实践
结合实战经验,以下几点建议可以帮助快速提升分块质量:
1、根据文档类型选择策略:结构清晰的文档优先使用层次化分块,非结构化文本使用语义分块,表格数据使用专用解析器。
2、块大小建议:一般场景下256-512 tokens是较优的选择;对话类内容可适当缩小至128-256 tokens。
3、Embedding模型对齐:分块策略应与所用的Embedding模型协同优化。不同模型对文本长度的敏感度不同,需要通过实验确定最佳组合。
4、迭代评估:没有一种分块策略适用于所有场景。建议构建领域特定的评测集,持续迭代优化分块参数。
5、多路召回融合:可以同时使用不同分块策略生成多套索引,在检索时进行融合排序,往往能获得比单一策略更好的效果。
七、总结展望
文档分块看似是一个简单的预处理步骤,实则是RAG系统中最需要精心调优的环节之一。理解不同策略的原理与适用场景,结合量化评估方法持续迭代,是构建高质量RAG系统的必经之路。
展望未来,随着多模态RAG和Late Chunking等新技术的发展,分块策略将从静态预处理演进为动态、查询感知的智能分块,进一步突破检索质量的上限。