 夜雨聆风
夜雨聆风





OpenClaw核心Coding Agent:Pi 的极简设计哲学与智能编码最佳实践
“如果你给智能体足够的自由度和权限,它就能自我修改。这是我对这种可塑的、自修改软件的第一次尝试。”
— Mario Zechner,Pi 作者
背景:为什么 Pi 值得关注
一、Pi 的设计哲学:极简作为核心竞争力
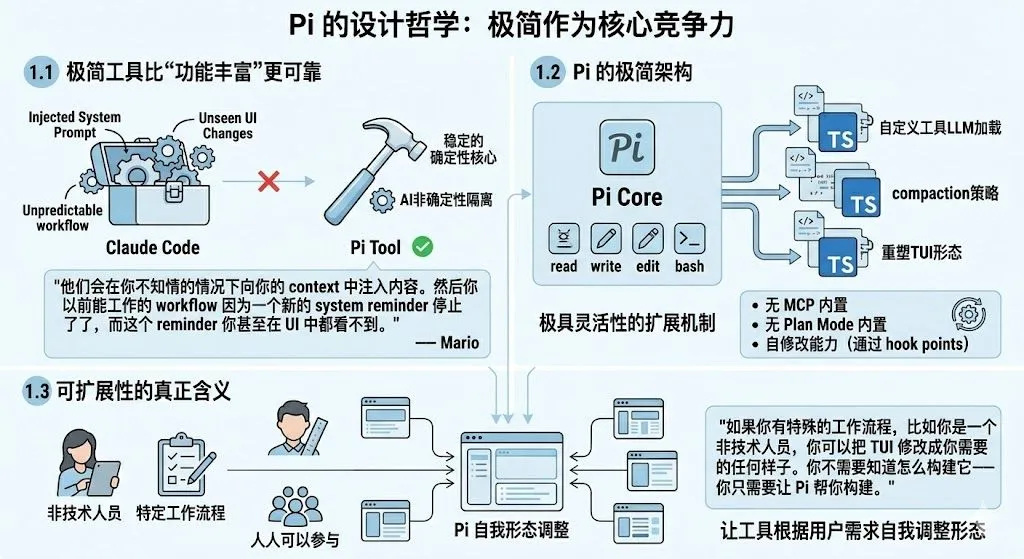
1.1 极简工具比”功能丰富”更可靠
“它会在你不知情的情况下向你的上下文中注入内容。然后你以前能正常工作的工作流因为一个新的系统提示词而停止了,而这个提示词你甚至在用户界面中都看不到。“
1.2 Pi 的极简架构
read / write / edit / bash-
无 MCP 内置——用户可以直接让 Pi 为自己构建 MCP 支持 -
无 plan mode 内置——用户可以自行实现并比较不同方案 -
自修改能力——Pi 可以修改自己,因为有足够的 hook points
1.3 可扩展性的真正含义
“如果你有特殊的工作流程,比如你是一个非技术人员,你可以把 TUI 修改成你需要的任何样子。你不需要知道怎么构建它——你只需要让 Pi 帮你构建。”
二、30+ 工程团队的访谈教训:质量下滑的真实原因
2.1 采用曲线的”假期效应”
“每次有人休假,就会有更多时间去尝试这些工具。感恩节、暑假、圣诞节——之后,超过一半的公司都迎来了真正的爆发。”
2.2 PR 越来越大、越来越难审查
“PR 变得越来越大、越来越长、越来越频繁,工程师很难跟上PR的节奏。”
2.3 AI 感受不到痛苦,人类才会
“人类会感受到代码库的疼痛。当代码变得太复杂时,工程师会感受到问题所在,这种技术债的痛苦会推动重构和重写。但 AI 根本不会这样——它们只是不断累积复杂度。”
三、复杂度是 AI 编码智能体最大的敌人
3.1 上下文窗口陷阱
“如果你的代码库有 600,000 行代码,而智能体的有效上下文窗口约为 200,000 tokens,智能体能看到多少代码?最多三分之一。”
“AI 自己产生的复杂度是它们最大的敌人。最终代码库会变得如此之大、如此互联,以至于智能体在技术上根本无法摄入完成新任务所需的所有上下文。”
3.2 来自互联网的”均值”训练数据
“互联网上有我们的旧代码,有 Linux 等精心维护的项目,但与所有其他垃圾相比,它们只是沧海一粟。机器学习模型会趋向于均值——而这个均值不是少数精心设计的项目,而是互联网上的所有垃圾。”
3.3 避免复杂度的策略
-
定期无情重构——强迫自己进入代码库,理解结构,而不仅仅是逐行修改 -
保持关键代码用手工——Pi 的 agent loop 和扩展加载机制是他手工维护的,不让 AI 碰 -
接受某些功能“看起来正确就行”——比如 HTML 导出功能,”我从没看过一行代码,只要输出看起来对就行”
四、”慢下来”的哲学:故意注入摩擦力
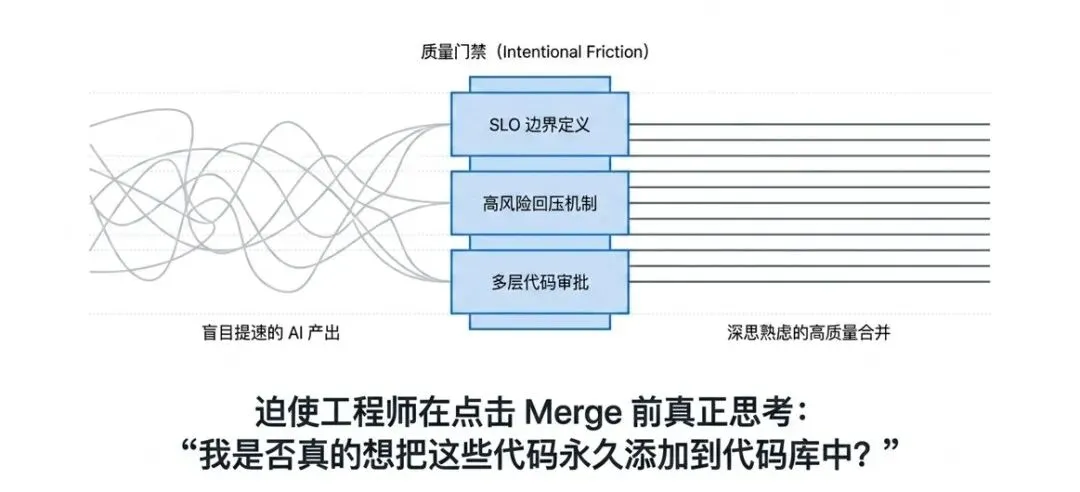
4.1 摩擦力的真正价值
“我们过去常常谈论消除所有挡路的东西,让开发者愉快地交付代码。但有些变更——比如删除数据库、执行可能锁表的迁移——这些时刻你真的需要思考。”
-
迫使工程师在提交代码前真正考虑:“我是否真的想把这个添加到代码库?” -
在高风险变更上建立回压机制(back pressure)
回压(back pressure)源自流体力学,在软件工程中指对过快或过量的变更施加阻力,使其减速或排队等待审批。在高风险变更场景下,回压机制的作用是:当变更风险达到阈值时,自动阻断或降速,强制要求人工审查、额外验证等,防止系统被不可控的变更压垮。本质是一种安全阀门。
-
保护关键系统的稳定性
4.2 Dark Factory 的数学陷阱
“你的智能体现在每天生成的代码量是你的 10 倍,但它也会生成 10 倍的错误。即使错误率只有你的一半,绝对错误数仍然更多。100 个智能体同时这样工作,最终结果是什么?”
4.3 走出黑灯工厂的路径
“让我们先把那些我们讨厌做的、但智能体确实能做好的事情自动化,这样我们就有时间思考我们真正想构建什么、用户真正需要什么。然后我们再动用智能体把它构建好——用时间和工具把它做到极致。”
五、MCP vs CLI:工具哲学的两种路线
5.1 MCP 的局限
-
非组合性——需要组合来自不同 MCP server 的工具输出时,必须经过 LLM 的 context,而 LLM 难以可靠地做跨源数据转换 -
过度工程化——很多公司只是简单地把 OpenAPI spec 转成一个 MCP server,生成数十个工具,反而让情况更糟 -
剥夺了模型的创造性——Mario 观察到,当 Pi 在 bash 中运行时,如果输出太多行,它会主动判断”这个文件 20MB,太大了”,然后只读取文件的一部分。”智能体在这些时刻有相当的创造力,而 MCP 把这个拿走了。”
5.2 CLI 的优势
“我们把所有 MCP server 以 TypeScript 函数的形式暴露出来,让模型直接写代码来调用这些服务——这本质上不需要 MCP server 本身。”
5.3 正确的工具选择
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
六、Clankers 问题:AI 自动发送 PR 的治理
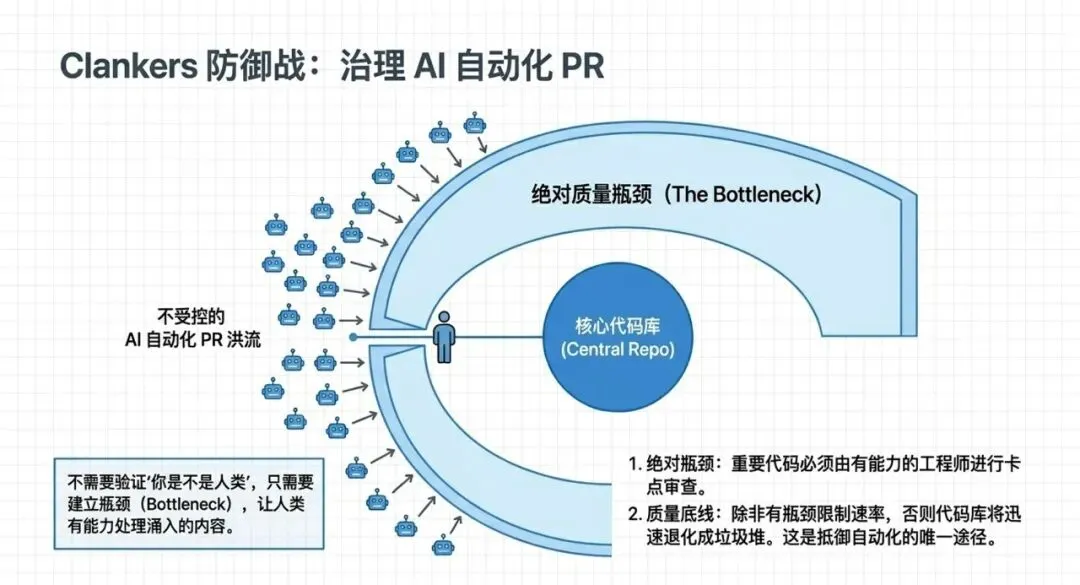
6.1 问题描述
6.2 治理策略
# GitHub workflow: auto-close non-human PRs- 如果发送者的 account name 不在白名单文件中,PR 自动关闭- 自动在 PR 下留言:"请以人类语言开一个 issue,不超过一屏,我会亲自处理"- AI 看不到这个评论,所以不会再次循环发送
6.3 瓶颈是维护代码质量的唯一途径
“除非有瓶颈,否则我无法处理涌入的内容。为了让 Pi 不退化成一堆垃圾,我相信它仍然需要我和有相应能力的人至少要审查重要代码——而这必须通过瓶颈卡点来进行保护。”
七、落地实践:从教训中提炼的 9 条最佳实践
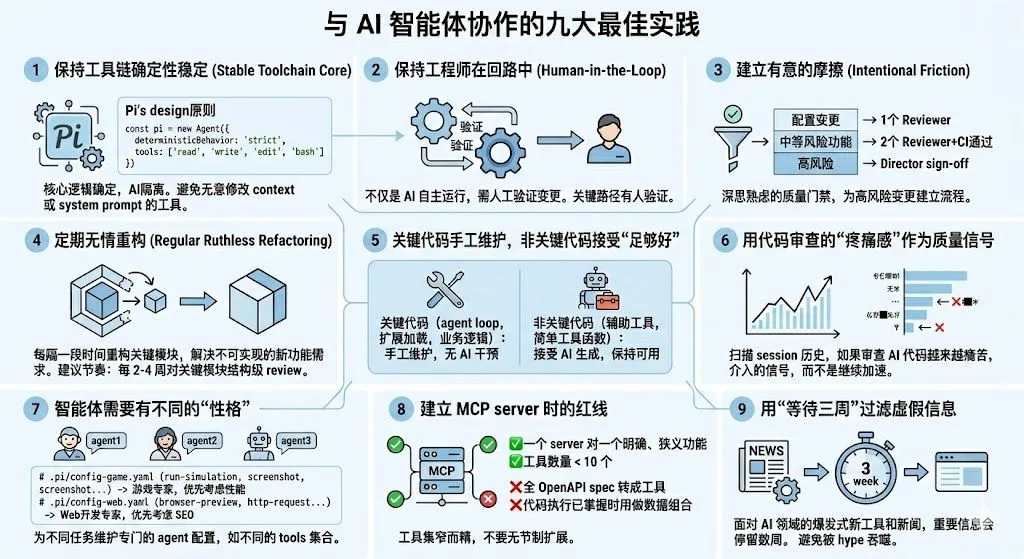
实践 1:保持工具链的确定性部分稳定
// Pi 的设计原则:核心逻辑是确定性的,AI 部分被隔离const pi = new Agent({provider: 'anthropic',tools: ['read', 'write', 'edit', 'bash'], // 极简工具集deterministicBehavior: 'strict', // 确定性行为严格受控extensionPoints: ['tool:*', 'compaction:*', 'tui:*'] // 灵活扩展点})
实践 2:保持工程师在回路中(Human-in-the-Loop)
当工程师保持人在环中,且系统能真正验证变更了什么时,AI 的效果最好。
实践 3:建立有意的摩擦
变更影响范围评估 → 必要审批数量────────────────────────────────配置变更(非代码) → 1 个 reviewer中等风险功能 → 2 个 reviewer + CI 通过高风险(数据库/基础设施)→ Director sign-off
实践 4:定期无情重构
“每隔一段时间,我就会因为想添加一个当前架构下不可能实现的新功能而进行重构。这是我保持代码质量和降低复杂度的唯一方法。”
实践 5:关键代码手工维护,非关键代码接受”足够好”
-
关键代码(agent loop、扩展加载机制、核心业务逻辑):手工维护,无 AI 干预 -
非关键代码(辅助工具、简单工具函数):接受 AI 生成,保持可用但不过度投入维护精力
实践 6:用代码审查的”疼痛感”作为质量信号
“当我扫描一个项目从开始到现在的 session 历史,Fxxx词的频率在增加——因为 AI 开始搞砸更多了。”
实践 7:智能体需要有不同的”性格”(Purpose-Specific Harness)
“我工作在不同项目上时想要不同的 harness。如果你回到游戏开发,你可能想要一个完全不同的 harness。”
# .pi/config-game.yamltools:- read / write / edit / bash / run-simulation / screenshotsystem_preamble: "你是游戏开发专家,优先考虑性能和内存效率"# .pi/config-web.yamltools:- read / write / edit / bash / browser-preview / http-requestsystem_preamble: "你是 web 开发专家,优先考虑可访问性和 SEO"
实践 8:建立 MCP server 时的红线
实践 9:用”等待三周”过滤虚假信息
“如果一个东西真的很重要,它会在讨论中停留数周。如果三周后它仍然在讨论中,它大概是真的有价值。”
八、自修改软件的未来展望
8.1 软件修改自身的时代正在到来
“我的直觉是:我们正在走向软件代表用户的意愿和需求自我修改的时代。智能体在有足够自由度和权限的情况下,可以修改自身。”
8.2 跨平台自主 Agent 的兴起
8.3 质量回滚的必要性
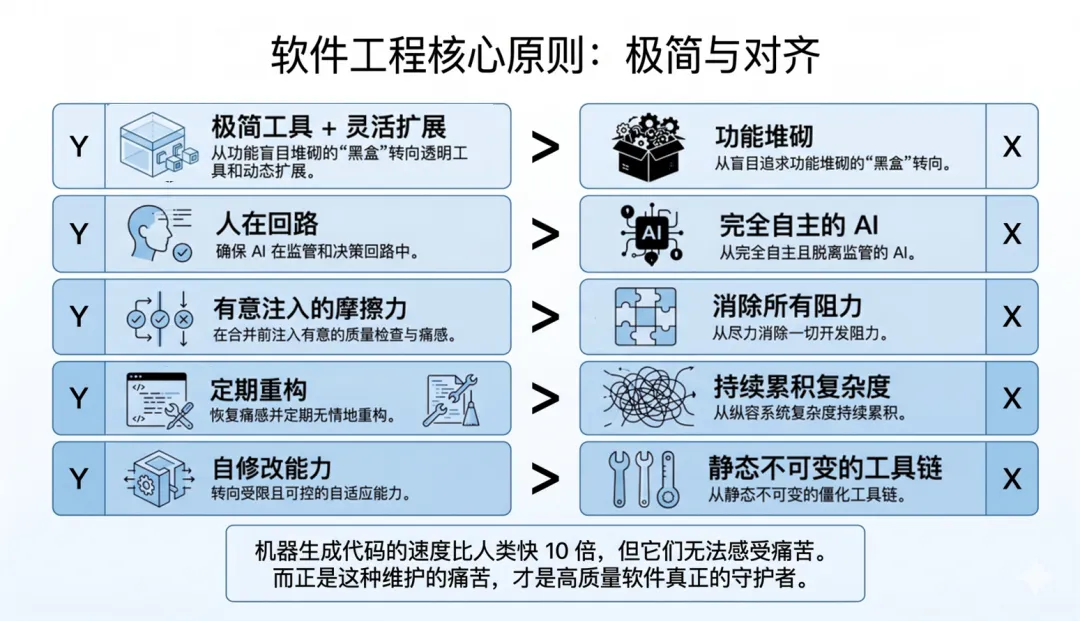
总结
“机器生成代码的速度可以比人类快 10 倍,但它们无法感受痛苦。而正是这种痛苦——当代码库变得难以维护时推动我们重构的力量——才是高质量软件的真正守护者。”
感谢阅读!我是冬哥,专注于探索AI软件研发的新范式。