 夜雨聆风
夜雨聆风





0.9B模型登顶文档解析榜首:PaddleOCR-VL-1.6的技术路径拆解

PaddleOCR-VL-1.6: Expanding the Frontier of Document
Parsing with Under-Optimized Region Refinement and
Progressive Post-Training
报告原文地址:https://arxiv.org/pdf/2606.03264
报告概述
百度飞桨团队发布 PaddleOCR-VL-1.6。该模型参数量维持在0.9B,未改变主干架构,通过“未优化区域挖掘”与“渐进式后训练”策略,在 OmniDocBench v1.6 上取得96.33% 的综合得分,超越参数量数十倍甚至百倍的通用大模型,成为当前文档解析任务的新 SOTA。
核心洞察
-
数据效率优于规模堆叠。在模型进入高性能区间后,盲目扩充通用数据收益递减。针对预测不稳定、分布稀疏和标注不可靠的特定区域进行定向增强,能以更低成本换取更高性能。
-
强化学习在小模型上的应用需要严苛的样本筛选。直接对紧凑模型使用 RL 极易导致退化。PaddleOCR-VL-1.6 设计了一套基于“改进潜力、不确定性、奖励方差”的三重过滤机制,确保 RL 阶段只优化那些真正可学且有增益的样本。
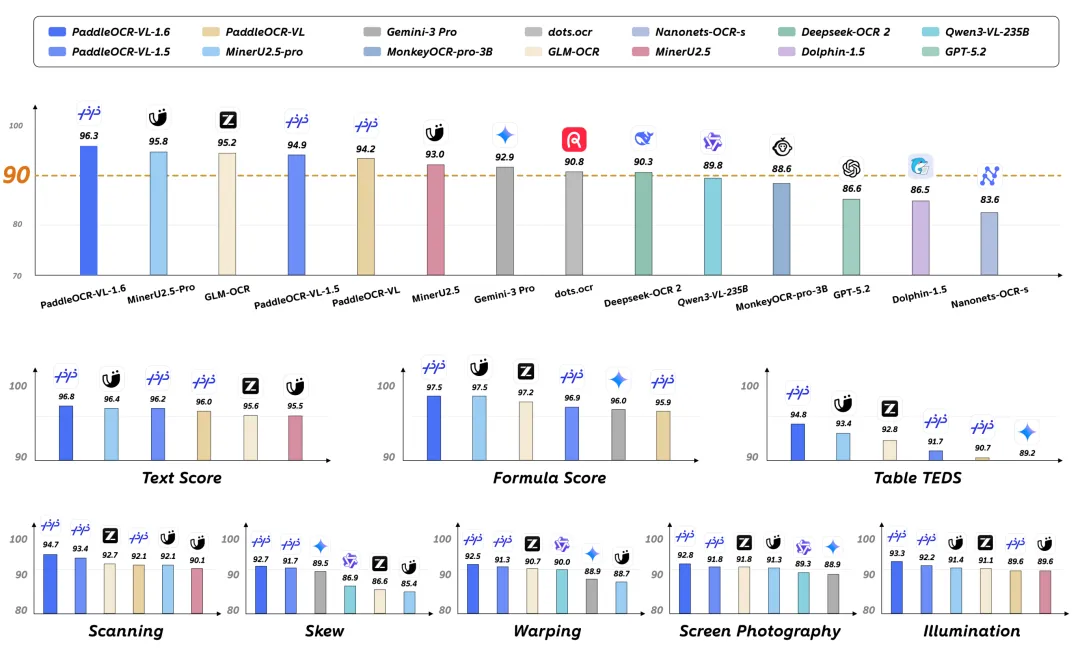
图1 | PaddleOCR-VL-1.6在OmniDocBench v1.6和Real5-OmniDocBench上的性能表现
一、从“题海战术”到“精准补差”:找到模型没学会的三个死角
想象你在备考。做一千道你已经会的基础题,不如搞懂一道你总是出错的难题。PaddleOCR-VL-1.5 已经很强,剩下的错误不再是“不会”,而是“没学透”。
PaddleOCR-VL-1.6 的做法不是扔给它更多书,而是让它把做过的卷子拿出来复盘,找出了三类“错题”:
-
边界脆弱区:换个字体、截个图,答案就变了。这说明模型在这个知识点上站不稳。
-
覆盖稀疏区:遇到冷僻字、老古籍,模型懵了。这是训练时的“盲区”。
-
监督不可靠区:标注本身就是错的,模型死记硬背了错误答案。
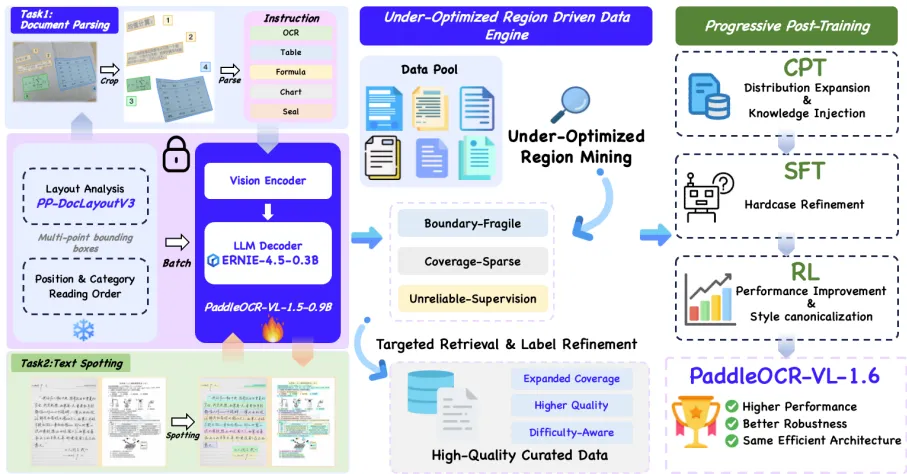
图2. PaddleOCR-VL-1.6 升级路径概览
这张图展示了升级的核心逻辑。左侧是传统的“堆数据、改结构”,右侧是 PaddleOCR-VL-1.6 的路径:诊断(Diagnosis) ->数据工程(Data Engineering) ->分阶段训练(Progressive Post-Training)。重点在于,它不再试图让模型“学会所有东西”,而是专注于修补上一版留下的“坑”。
为了量化“边界有多脆”,论文设计了一个极其严苛的测试。对每个样本,用 8 个不同阶段的模型权重和 16 种图像扰动(模糊、压缩、位移等)组合,生成 128 个预测结果,计算它们之间的差异。
差异越大,说明这个样本所在的区域越不稳定。这就像用 8 种不同难度的模拟卷去考一个学生,看他成绩波动有多大。
二、自动修错题:多专家仲裁与“渲染比对”
找到错题后,需要标准答案来纠正。但在文档解析领域,标注极其昂贵且容易错。PaddleOCR-VL-1.6 引入了一个自动化流水线。
对于难以判断的样本,它不直接相信某一方,而是启动“多专家会诊”。
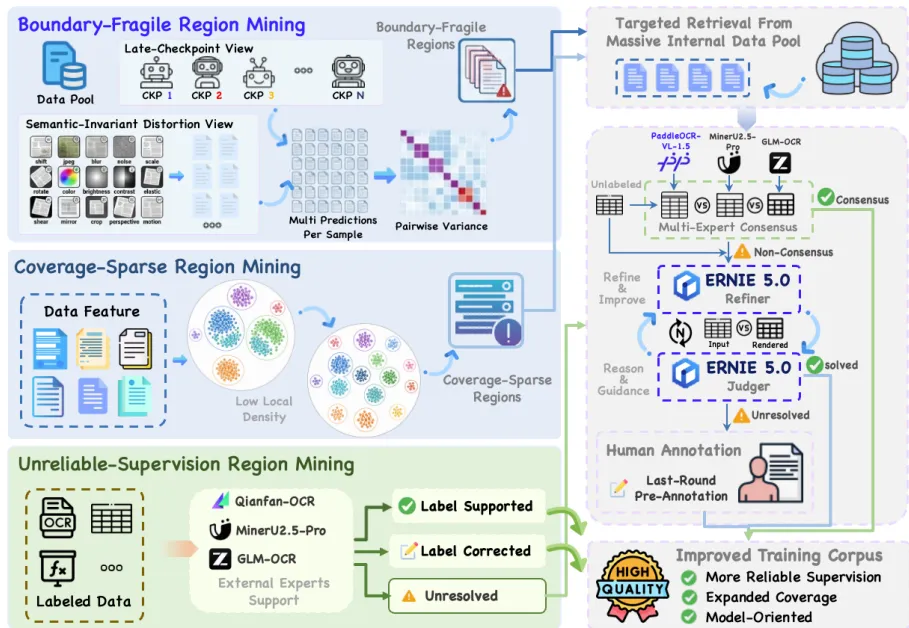
图3. 未优化区域驱动的数据引擎
这张图详细描绘了数据处理的闭环。关键在于右下角的Render-Guided Refinement(渲染引导精修)。对于表格和公式这类结构化数据,直接对比文本(LaTeX/HTML)很难发现细微的结构错位。系统会把模型生成的表格“画”出来,变成图片,再和原图做像素级比对。这比单纯看代码要直观得多,能精准定位“这一行的格子歪了”还是“那个字漏了”。
如果三个专家(Qianfan-OCR, GLM-OCR, MinerU2.5-Pro)意见不一致,就交给 ERNIE 5.0 这个“超级教师”来判断。为了防止偏见,系统只在第一次给参考,后续修正只看“学生”的答案和“标准图”的差距。
三、分阶段“补课”:CPT、SFT 与 RL 的接力赛
有了高质量的“错题集”,怎么喂给模型也是有讲究的。不能一股脑全塞进去,那样会造成消化不良。
表 8 清晰地展示了分阶段训练的效果。每一步都在前一步的基础上叠加增益。
表 8. 渐进式后训练各阶段的消融实验结果
|
训练阶段 |
综合得分 (Overall) |
文本编辑距离 (TextEdit) |
公式识别 (Formula CDM) |
表格结构 (Table TEDS-S) |
|---|---|---|---|---|
|
PaddleOCR-VL-1.5 (基线) |
94.93 |
0.038 |
96.89 |
94.37 |
|
+ 继续预训练 (CPT) |
95.62 (+0.69) |
0.035 |
97.32 |
95.82 |
|
+ 监督微调 (SFT) |
96.25 (+0.63) |
0.034 |
97.37 |
97.09 |
|
+ 强化学习 (RL) |
96.33 (+0.08) |
0.033 |
97.49 |
97.11 |
数据揭示了训练策略的有效性。CPT 阶段负责“扫盲”,通过注入大量新数据和修正后的标注,大幅提升了表格结构识别能力(TEDS-S 提升显著)。SFT 阶段负责“攻坚”,专门针对那些专家都吵翻了的难题进行特训,带来了最大的边际收益。RL 阶段则是“抛光”,虽然整体得分提升只有 0.08,但在公式识别等精细指标上进一步逼近了上限。这说明对于已达到高水准的小模型,RL 的作用更多是查漏补缺,而非颠覆性改变。
特别是在 RL 阶段,为了避免小模型“学疯了”,团队设计了严格的样本筛选公式。他们不仅看模型能不能做对,还看模型做对这件事的“信心”波动有多大。只有那些“偶尔能做对,但大多数时候做不对”的样本,才被选入 RL 训练池。这确保了模型是在学习解题技巧,而不是死记硬背。
四、0.9B 打爆 235B:数据不会说谎
最终的性能榜单证明了这套方法的有效性。在 OmniDocBench v1.6 上,PaddleOCR-VL-1.6 以不到千亿分之一的参数量,击败了动辄几十亿、上百亿甚至万亿级的对手。
表 2. OmniDocBench v1.6 综合评测榜单(节选)
|
模型 |
参数量 |
综合得分 (Overall) |
|---|---|---|
|
Qwen3-VL-235B |
235B |
89.78 |
|
Gemini 3 Pro |
– |
92.91 |
|
MinerU2.5-Pro |
1.2B |
95.75 |
|
PaddleOCR-VL-1.6 |
0.9B |
96.33 |
参数量的悬殊对比极具冲击力。通用大模型(如 Qwen3-VL-235B)虽然在通用对话上无敌,但在文档解析这种需要精确结构和细粒度识别的任务上,往往不如专精的小模型。PaddleOCR-VL-1.6 证明了,通过精细化的数据治理,0.9B 的紧凑模型完全可以在特定领域超越参数怪兽。 这对于需要在端侧设备或低成本服务器上部署 OCR 能力的企业来说,意味着更低的延迟和更少的计算开销。
结语:小模型的生存法则
大模型竞赛正在从“谁更大”转向“谁更准”。PaddleOCR-VL-1.6 提供了一个清晰的范本:当模型规模触碰到物理或成本的极限时,挖掘数据中的“认知盲区”比单纯堆砌算力更有效。对于开发者而言,与其等待下一代更强的基座,不如审视现有的数据和训练流程——那些被忽略的错误样本,可能藏着通往 SOTA 的钥匙。