 夜雨聆风
夜雨聆风





OpenClaw 视频翻译技能

AI Agent & LLM
早上好,昨天(6月3日)AI Agent 和 LLM 赛道相当热闹,从开源视觉模型到企业 AI 落地定价都有值得聊的。
重点动态
Ideogram 4.0 开源,9.3B 文生图模型
93 亿参数的单流扩散 Transformer,完全从头训练,文本渲染能力在开源模型里目前最强。
Ideogram 把 4.0 直接开源了,NF4 量化后单张 24GB 显卡就能跑。重点不在参数量,而是它用结构化 JSON prompt 做精确控制,覆盖文字渲染、bounding box 空间定位和色彩调色板,可控性很强。
实测文字渲染在开源模型中是碾压级表现。做海报、信息图这类需要精准嵌入文字的场景,这可能是目前最实用的开源选择。
📎 相关链接
Ideogram 4.0
https://github.com/ideogram-oss/ideogram4
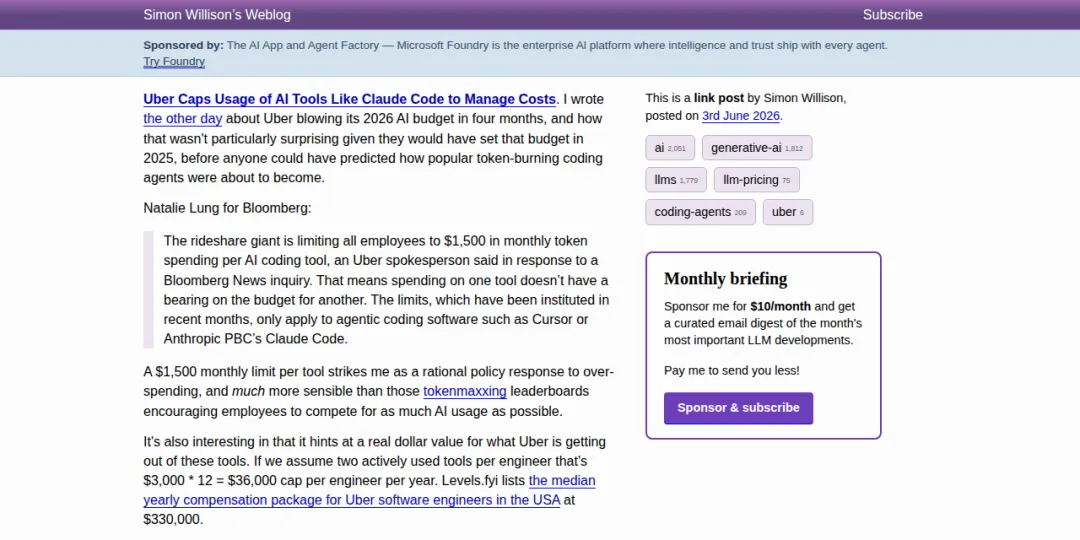
Uber 给 AI 工具设每月 $1,500 上限
Simon Willison 指出 Uber 限制 Claude Code 等工具月消费 $1,500,这个数字本身就是 AI 工具定价的心理锚点。
Bloomberg 报道 Uber 开始对 Claude Code、Cursor 等工具设定月度使用上限。Simon 的分析很到位:企业愿意为单个工程师每月花多少在 AI 上,正在形成一个行业共识价位。
这对 SaaS 定价策略影响很大。一线大厂接受这个价位,按 seat 订阅的 AI 编程工具就有了明确的定价天花板。反过来也说明,AI 编程工具的 ROI 已经被企业认真量化了。
📎 相关链接
Uber AI cap analysis
https://simonwillison.net/2026/Jun/3/uber-caps-usage/
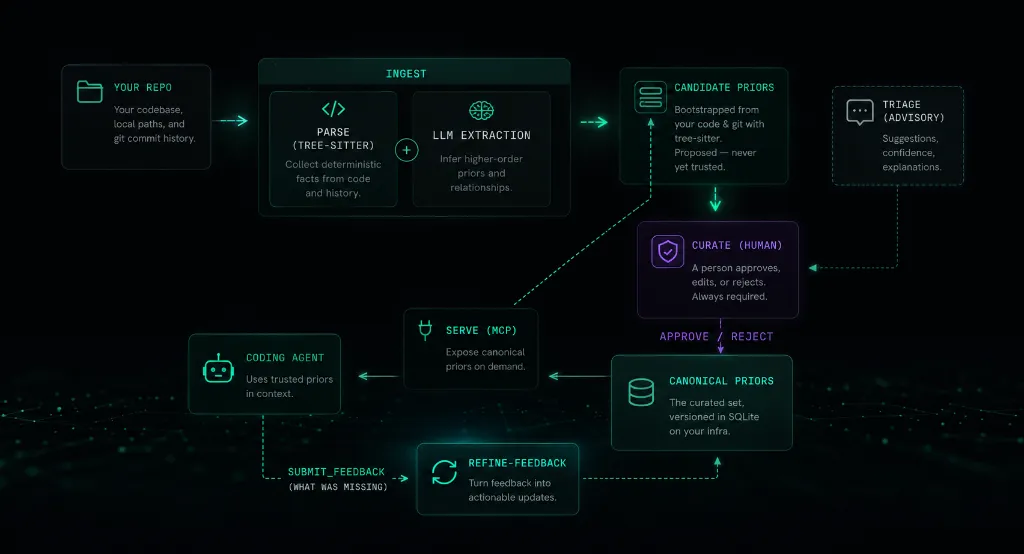
Metatron:把代码库的隐性知识喂给编码 Agent
一个自托管系统,把代码库里的实现决策、偏好模式和被否决的方案结构化后通过 MCP 服务给编码 Agent。
编码 Agent 的通病是不了解项目历史,每次从零推理。Metatron 把隐性知识提取成结构化先验,通过 MCP 协议注入 Claude Code 和 Cursor。目标很明确,让 Agent 写代码像熟悉代码库的高级工程师。
思路类似 RAG 但粒度更细,聚焦代码决策层面而非文档检索。目前支持 Python,项目还比较早期,理念方向值得持续关注。
📎 相关链接
Metatron
https://github.com/kerbelp/metatron
AWS Bedrock Agent Core Skill
一个 Claude Code 插件,按 AWS 官方最佳实践在 Bedrock 上构建生产级 Agent,覆盖 Strands Agents、Bedrock 和 Bedrock AgentCore 三条路径。
这不是模板生成器,而是真正引用了 AWS 官方文档作为权威来源,Agent 构建过程中会动态查阅。对需要在 AWS 上部署 Agent 的团队来说,相当于把最佳实践编码成了 Claude Code 的一个能力。

📎 相关链接
AWSBedrockAgentCoreSkill
https://github.com/ferdinandobons/AWSBedrockAgentCoreSkill
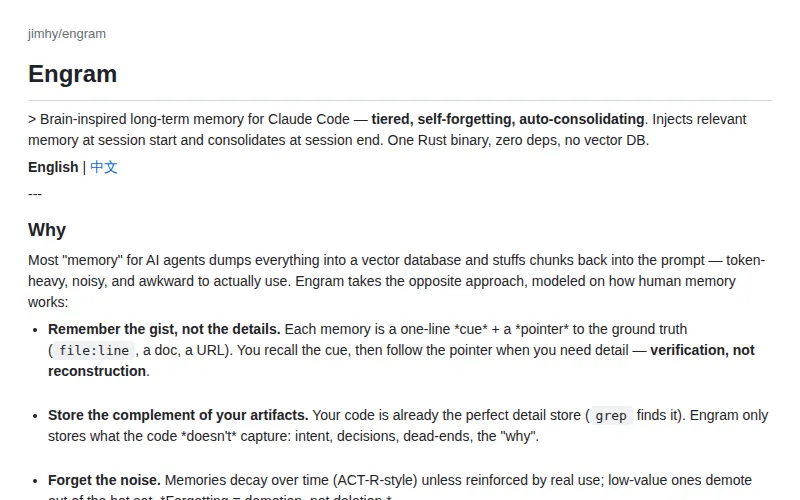
Engram:给 Claude Code 加类脑长期记忆
Rust 写的单二进制工具,实现分层、自动遗忘、自动巩固的长期记忆,session 开始注入相关记忆,结束时自动整合。
Claude Code 的上下文用完就忘,Engram 要解决这个问题。记忆分多层,模拟人脑遗忘曲线和记忆巩固机制,零依赖且不需要向量数据库,部署非常干净。
📎 相关链接
Engram
https://github.com/jimhy/engram
Claude Opus 审查移除工具冲上 Trending
声称在 prompt 层移除 Claude Opus 4.6+ 拒绝机制的中间件,昨天在 GitHub Trending 上热度很高。
这类项目在安全社区争议很大,技术上走的是 prompt 注入和中间件拦截的路子,实际效果存疑。更多反映的是社区对模型审查机制的持续博弈,关注安全动态即可。

📎 相关链接
Claude Censorship Remover
https://github.com/DisplaySanctify/Claude-Opus-4.6-Censorship-Remover
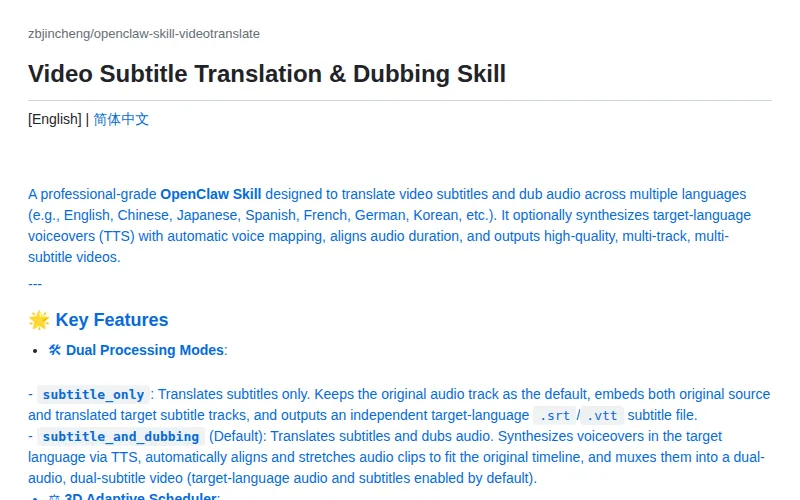
OpenClaw 视频翻译技能
英文字幕翻译到中文,生成 TTS 配音,合成多轨道无损视频,内置三维自适应调度器防止 API 限流。
全链路自动化,从字幕翻译到配音合成一气呵成。三维自适应调度器专门解决 LLM 和 TTS 的速率限制问题,对批量翻译场景比较实用。
📎 相关链接
openclaw-skill-videotranslate
https://github.com/zbjincheng/openclaw-skill-videotranslate
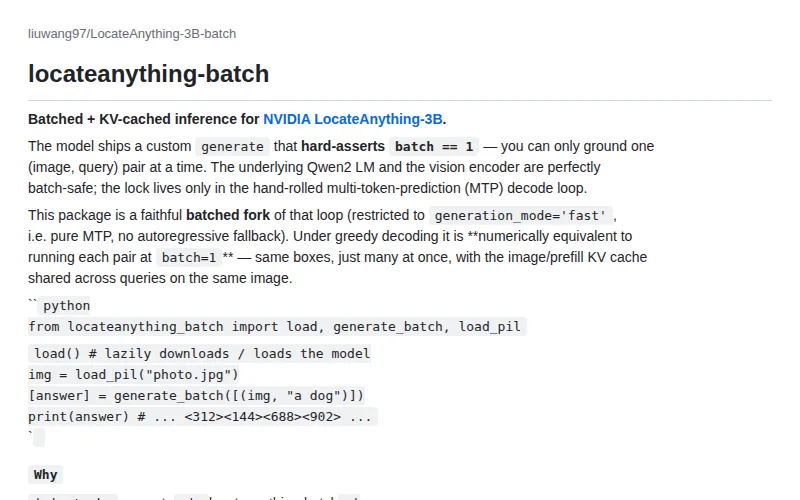
LocateAnything-3B 批量推理优化
给 NVIDIA LocateAnything-3B 加了 batch 推理和 KV cache 支持,原版只支持 batch=1。
通过 KV cache 和批处理提升吞吐量,对需要大规模图像定位的场景直接有效,改动不大但实用价值明确。
📎 相关链接
LocateAnything-3B-batch
https://github.com/liuwang97/LocateAnything-3B-batch
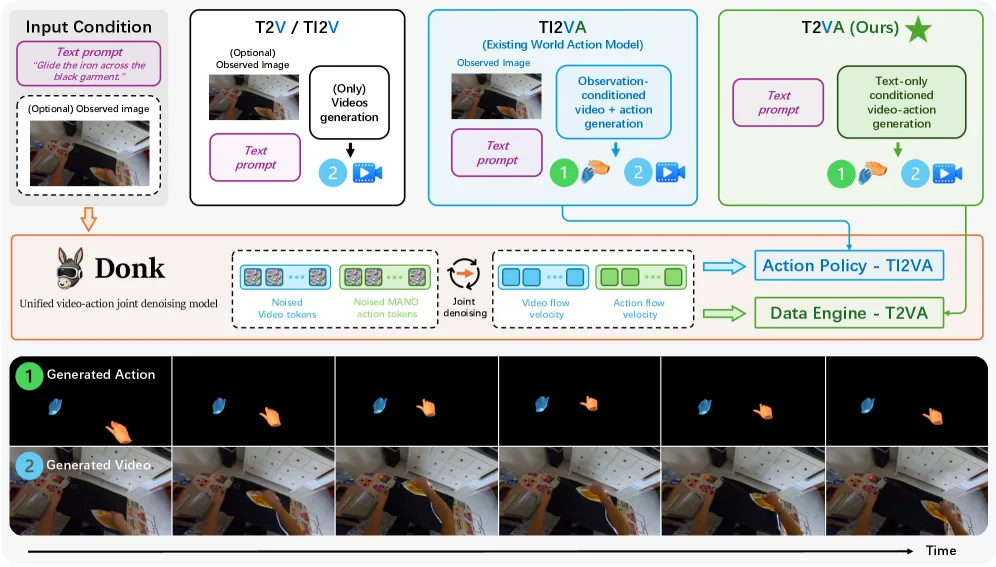
统一视频-动作联合去噪用于灵巧操作
arXiv 新论文,从分布视角重新审视视频基础模型与机器人动作的对齐,保留更宽的联合分布而非收窄为条件策略。
传统方法把对齐后的先验收窄为条件策略分布,这篇选择建模交互视频和可执行手部轨迹的联合空间,把视频生成和灵巧动作数据生成统一到一个去噪框架里,思路比较新颖。
📎 相关链接
论文
https://arxiv.org/abs/2606.03868
下午见。