 夜雨聆风
夜雨聆风





〖OpenClaw系列〗AI网关是什么、能做什么
开篇:AI时代的”路由器”
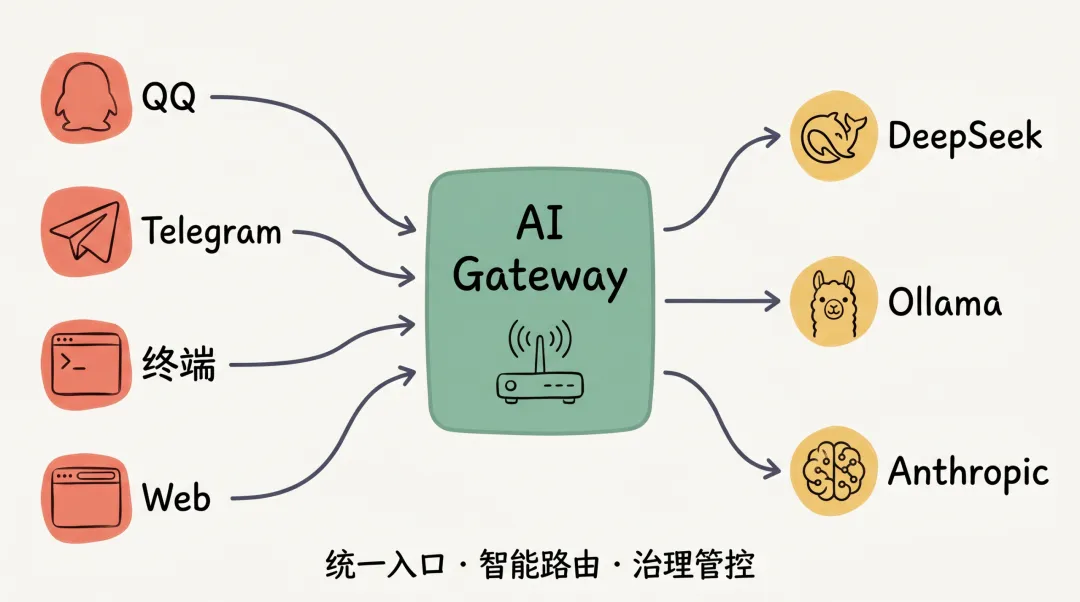
你有没有想过:当你给AI发了一条消息,它是怎么知道该用哪个模型、调用哪个技能、回复到哪个渠道的?
这中间有一个环节叫 AI网关。
OpenClaw Gateway 本身不运行模型推理引擎,而是通过标准化 API 接口对接外部模型服务(如 DeepSeek、Ollama、Anthropic 等),专注于消息路由、渠道管理和治理控制:消息从QQ/Telegram/终端进来,它判断该用哪个模型、调哪个技能,然后把结果送回对应的渠道。
这篇不讲代码,先把”AI网关”这个设计思路讲清楚,以及它解决了什么问题。
没有网关的时候
假设你想在QQ上用AI,在终端上也用AI,还希望AI能每天定时推送信息给你。
没有网关的时候,每个接入都是一个独立的项目:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
三个接入,三套代码,三套配置。模型换了要改三遍。对话记录各自存,互不通。
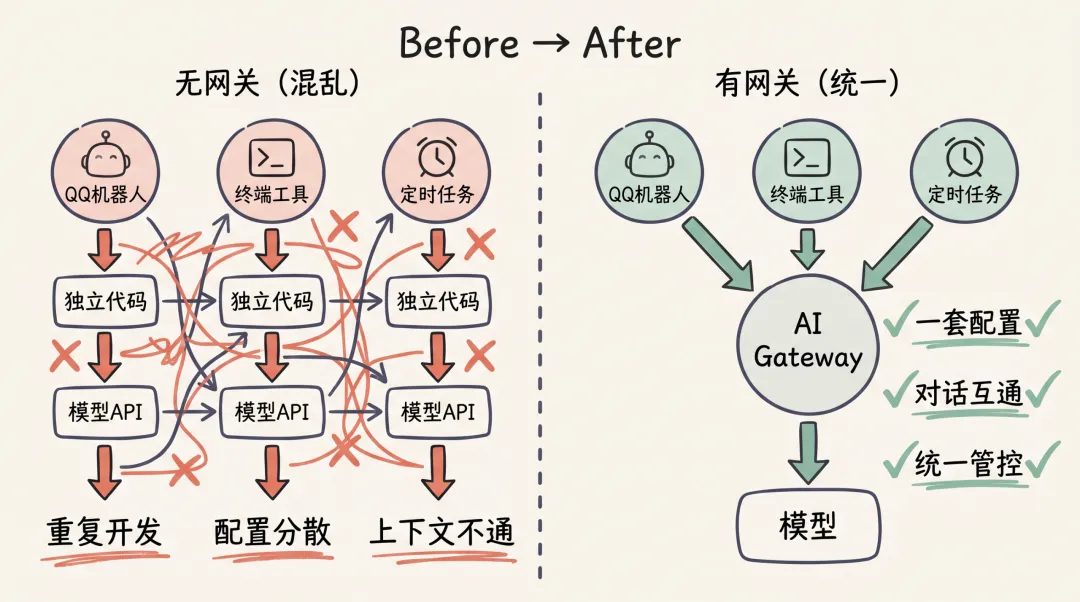
AI网关把这些问题统一了。
AI网关到底是什么
一句话:所有AI请求的统一入口和出口。
不管请求是从QQ来的、Telegram来的、还是终端来的,都走同一个入口。Gateway判断请求类型,分发给对应的Agent处理,然后把结果送回对应的渠道。
网关做三件事
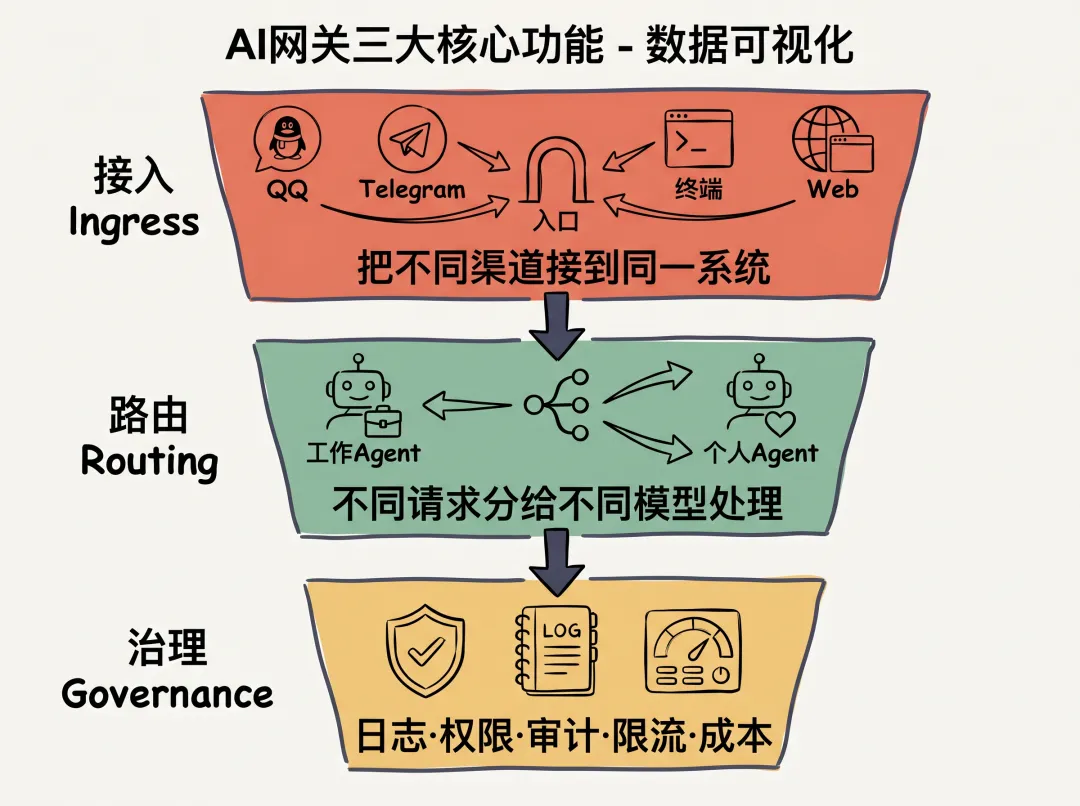
┌─────────────────────────────────────────┐│ AI 网关 │├─────────────────────────────────────────┤│ ││ ① 接入 (Ingress) ││ 把不同的渠道接到同一个系统 ││ QQ / Telegram / 终端 / Web ││ ││ ② 路由 (Routing) ││ 不同请求分给不同模型/Agent处理 ││ 工作Agent / 个人Agent / 专用Agent ││ ││ ③ 治理 (Governance) ││ 记录日志、管理对话上下文、控制权限 ││ 审计 / 限流 / 成本监控 ││ │└─────────────────────────────────────────┘一条消息的完整旅程
光说”接入、路由、治理”还是太抽象。下面用一条QQ消息的完整流转,把四个组件串起来:
用户在QQ群发送:"帮我总结一下今天的新闻" ┌──────┐ ① 消息到达 ┌──────────┐ │ QQ群 │ ──────────────────→ │ Channel │ │(渠道)│ │ (QQ Bot) │ └──────┘ └────┬─────┘ │ ② 标准化消息格式 (附带渠道ID、用户ID、时间戳) │ ▼ ┌─────────────┐ │ Gateway │ │ (路由枢纽) │ └──────┬──────┘ │ ③ 查路由规则: QQ群消息 → 工作Agent │ ▼ ┌─────────────┐ │ Agent │ │ (工作助手) │ │ │ │ 模型: DeepSeek│ │ Skill: 搜索 │ └──────┬──────┘ │ ④ 调用DeepSeek API + 调用搜索Skill获取新闻 + 生成摘要 │ ▼ ┌─────────────┐ │ Gateway │ │ (回程路由) │ └──────┬──────┘ │ ⑤ 记录日志、统计token用量 + 按原路返回 │ ▼ ┌──────────┐ │ Channel │ │ (QQ Bot) │ └────┬─────┘ │ ⑥ 回复到QQ群 │ ▼ ┌──────┐ │ QQ群 │ └──────┘用户看到:"今天的主要新闻有以下几条..."整个过程对用户是透明的——用户只是在QQ群里发了条消息、收到了回复。背后Channel负责收发、Gateway负责路由、Agent负责思考、Skill负责执行。
治理能力拆解
“治理”这个词太笼统了。具体来说,OpenClaw Gateway在治理层面做了这些事:
|
|
|
|
|---|---|---|
| 日志记录 |
|
|
| 权限控制 |
|
|
| 成本监控 |
|
|
| 限流 |
|
|
| 对话上下文 |
|
|
💡 对话上下文存储在本地工作区(workspace目录),不依赖外部数据库。这也是Gateway能做到”无状态”的关键——状态存在工作区,Gateway本身只做转发。
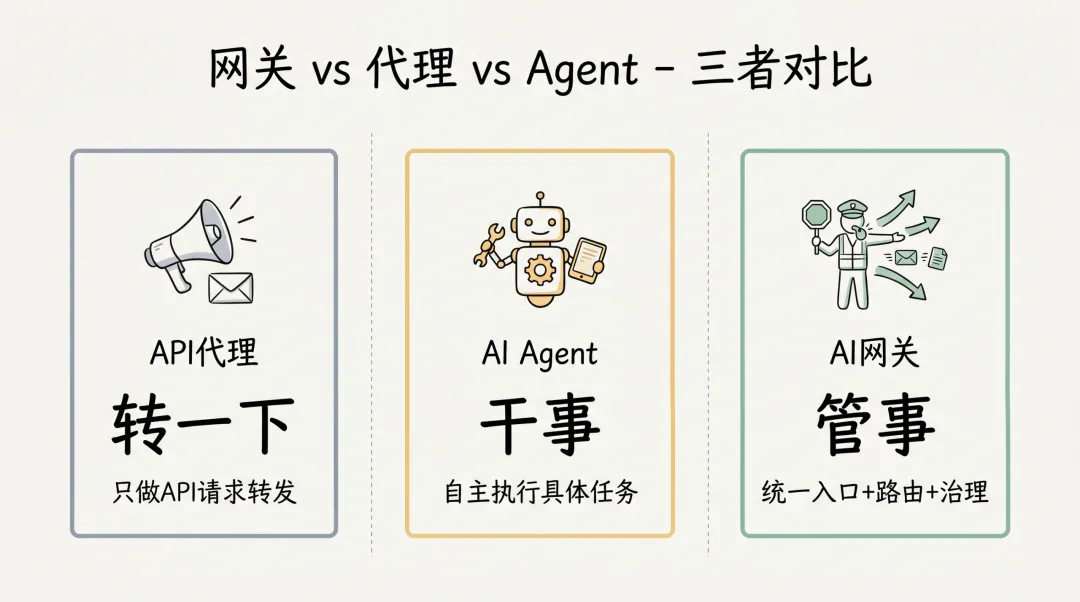
网关 vs 代理 vs Agent
容易搞混的三个概念,放在一起对比:
|
|
|
|
|
|---|---|---|---|
| 做什么 |
|
|
|
| 能不能换模型 |
|
|
|
| 能不能接多渠道 |
|
|
|
| 有没有治理能力 |
|
|
|
简单理解:
-
API代理只做”转一下”的事 -
AI Agent做”干事”的事 -
AI网关做”管事”的事——哪个渠道的哪个请求,由哪个Agent处理,怎么管控,怎么追溯
OpenClaw的四个核心组件
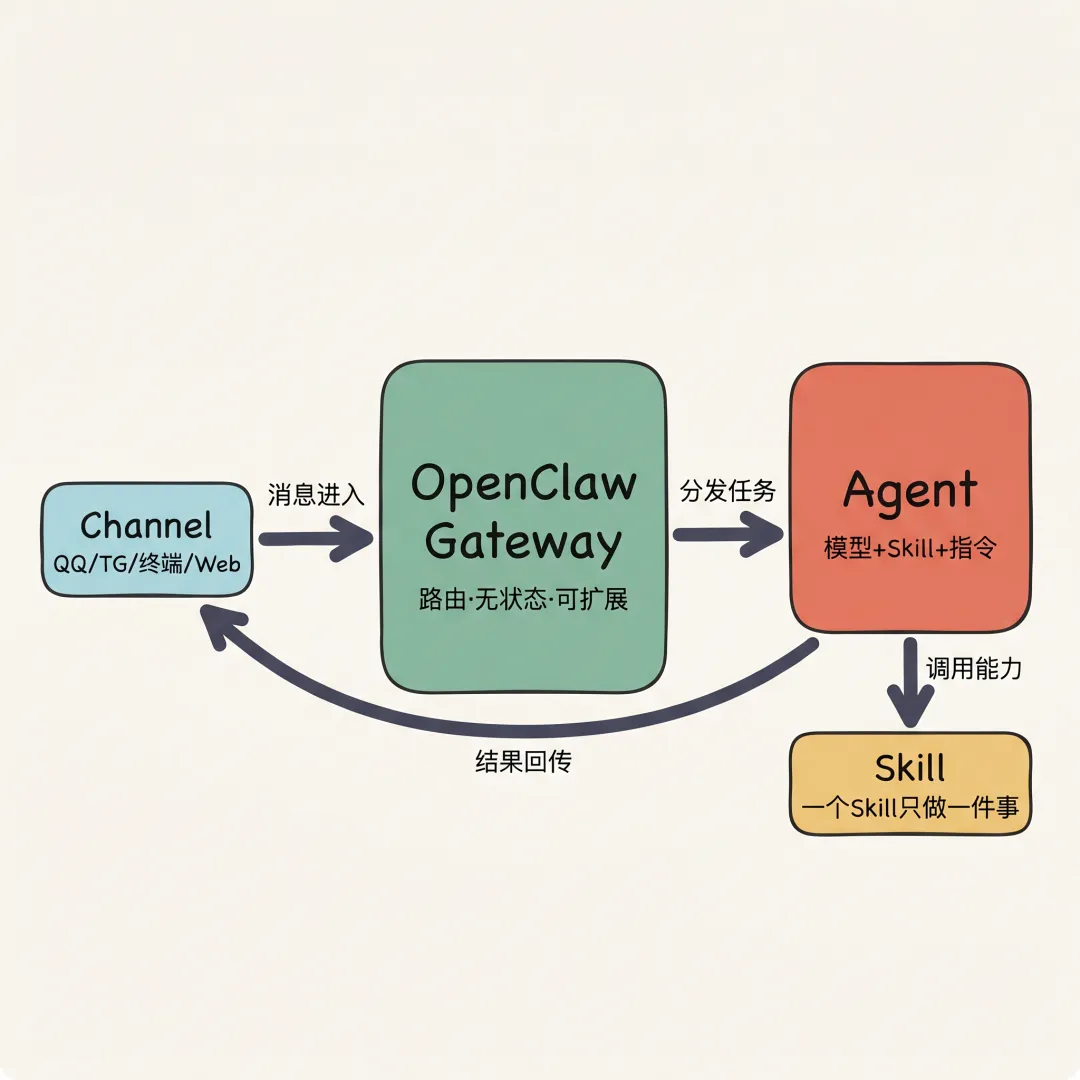
拆开看OpenClaw的内部,其实就四个东西。搞清楚这四个就读懂它了。
① Gateway(网关枢纽)
最核心的组件。所有消息进出的枢纽。它不做AI推理,不存数据,只负责路由。
工作流程:
QQ消息 → Gateway → 判断意图 → 分配给对应Agent ↓QQ回复 ← Gateway ← 整理结果 ← Agent拿到模型回复Gateway的设计原则是无状态、可横向扩展。一台不够,加一台。每台Gateway独立处理请求,不共享状态。
② Agent(任务单元)
处理具体任务的单元。一个Agent绑定:
-
一个模型 -
一组Skill -
一组系统指令
你可以建多个Agent,让它们各管各的:
-
工作Agent用Pro模型处理复杂任务 -
个人Agent用Flash模型处理日常对话
③ Skill(能力模块)
Agent能做的事情——文件操作、执行命令、联网搜索、存取记忆。
每个Skill是一个独立的能力模块。设计原则:一个Skill只做一件事。
⚠️ 不能有一个全能Skill既读文件又执行命令——那样AI的行为边界就模糊了。
④ Channel(接入渠道)
AI从哪个入口进来。QQ、Telegram、终端TUI、Web UI——每个Channel是一个接入方式。
渠道之间互相独立。配置了QQ和Telegram后,两个渠道可以同时用,AI在各自的Session里独立工作。
为什么选择这种设计
你可能问:为什么OpenClaw不把这些都做到一个程序里?
如果全部做到一个程序里,安装简单但扩展性差——想换模型、想加渠道,都要改代码。
OpenClaw选择了微内核+插件的方式:核心只做路由,扩展功能通过插件实现。
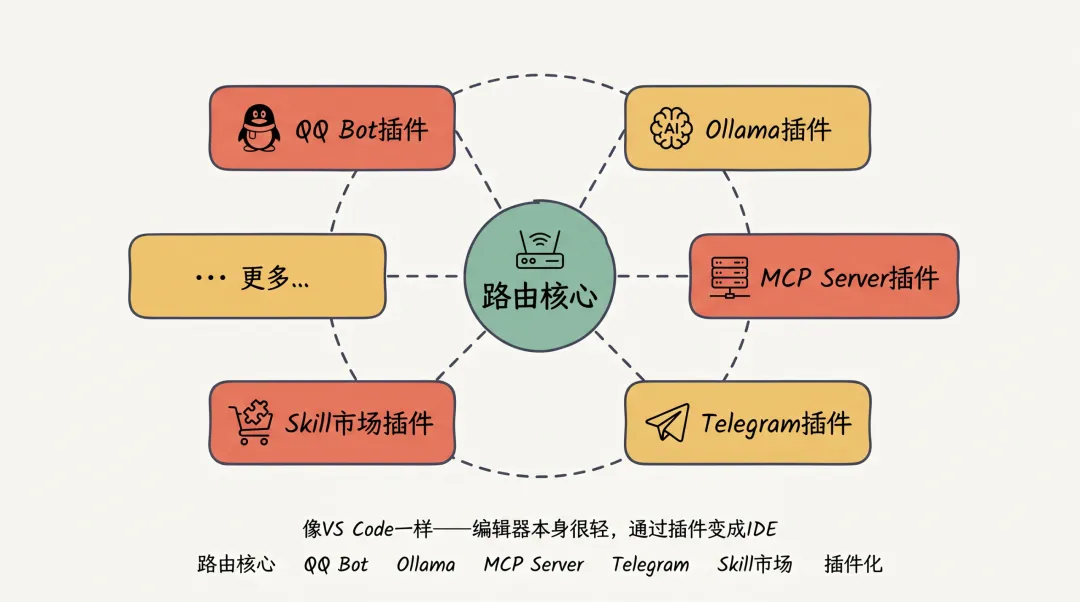
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
这个设计思路跟VS Code一样——编辑器本身很轻,通过插件变成IDE。
跟其他方案有什么不同
市面上有不少可以做AI请求管理的工具。你可能听过其中一些,放在一起对比:
|
|
OpenClaw | LiteLLM | OneAPI | 传统API网关+AI插件 |
|---|---|---|---|---|
| 定位 |
|
|
|
|
| 多渠道接入 |
|
|
|
|
| 多Agent管理 |
|
|
|
|
| 模型切换 |
|
|
|
|
| Skill/工具调用 |
|
|
|
|
| 对话上下文管理 |
|
|
|
|
| 部署方式 |
|
|
|
|
| 适合场景 |
|
|
|
|
一句话总结:
-
LiteLLM / OneAPI 做的是”模型代理”——帮你统一不同模型的API格式,省去适配工作 -
OpenClaw 做的是”AI网关”——不止代理模型,还管渠道接入、Agent调度、Skill编排、对话管理
如果你只是想在代码里调用多个模型的API,LiteLLM/OneAPI就够了。如果你想让AI从QQ/Telegram/终端等多个入口都能用,同时管理多个Agent和Skill,那OpenClaw才是你需要的。
OpenClaw的适用场景
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
OpenClaw最适合的场景:你自己维护一台服务器,想让AI从多个入口都能用,同时对成本和安全性有一定的控制需求。
30秒体验:装一个试试
说了这么多概念,不如动手跑一下。最快的方式是Docker:
# 一条命令启动 OpenClawdocker run -d --name openclaw \ -p 8080:8080 \ -e OPENAI_API_KEY=你的API密钥 \ openclaw/openclaw:latest启动后,终端里直接跟AI对话:
# 发一条消息测试curl -X POST http://localhost:8080/api/chat \ -H "Content-Type: application/json" \ -d '{"message": "你好,介绍一下你自己"}'看到AI回复了?恭喜,你的AI网关已经跑起来了。
📌 这只是最简单的体验方式。完整的安装指南(Docker、二进制、源码编译三种方式的对比和详细步骤)请看下一篇:第2篇:三种方式安装和启动OpenClaw。
常见误区
误区1:以为OpenClaw是AI模型
很多人看到”装OpenClaw”以为装了一个大模型。其实OpenClaw不跑推理,它只是帮你调DeepSeek/Ollama/其他模型的API。模型要另外配。
误区2:以为一个Agent就够了
初期确实够了。但随着使用场景增多,工作和个人混在一个Agent里,AI上下文会混乱。多Agent配置才是长时间使用的正确方式。
误区3:Gateway不能有单点故障
默认配置下Gateway只有一台实例,确实存在单点风险。但这不是设计缺陷——Gateway是无状态的,天然支持多实例部署。
推荐的高可用方案:
┌─────────────┐ │ Nginx/HAProxy │ │ (负载均衡) │ └──────┬──────┘ │ ┌────────────┼────────────┐ ▼ ▼ ▼ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ Gateway │ │ Gateway │ │ Gateway │ │ 实例 1 │ │ 实例 2 │ │ 实例 3 │ └────┬─────┘ └────┬─────┘ └────┬─────┘ │ │ │ └────────────┼────────────┘ ▼ ┌─────────────┐ │ 共享工作区 │ │ (对话上下文) │ └─────────────┘-
Gateway本身无状态,任何一台挂了,流量自动切到其他实例 -
对话上下文存在共享工作区(本地磁盘或NFS),不存在Gateway进程内 -
个人使用单实例就够了;小团队建议至少两台实例 + Nginx做负载均衡
📌 具体的多实例部署配置,会在后续架构篇中详细展开。
总结
本文介绍了AI网关的核心概念:
|
|
|
|---|---|
| AI网关 |
|
| Gateway |
|
| Agent |
|
| Skill |
|
| Channel |
|
关键认知:
-
OpenClaw是AI网关,不是AI模型 -
微内核+插件设计保证扩展性 -
多Agent配置是长期使用的正确方式
下一篇预告
第2篇:三种方式安装和启动OpenClaw
设计讲完了,下一篇讲实操——Docker、二进制、源码编译三种方式怎么选。
本文是系列第1篇。你已理解AI网关的核心定位。
📌 觉得有用?点个「在看」 👇 👨💻 关注「敏叔的技术札记」,每周更新 OpenClaw 实战干货 ⭐ **收藏这篇文章,作为 AI 网关入门参考