 夜雨聆风
夜雨聆风





OpenClaw 是一个围绕 Agent 构建的运行时网关系统(Agent Runtime + Gateway).它不是一个简单的聊天机器人或工具调用框架
一、核心架构:五层结构
OpenClaw 的架构可以抽象为五层,职责划分非常清晰:
用户接口层 (USERFACE LAYER):提供 CLI、Web UI、移动 App、WebSocket API 等入口,将用户操作统一转换为内部请求。
Gateway 核心层 (GATEWAY CORE LAYER):核心运行时,负责连接管理、请求接入、配置热加载、健康监控等基础治理工作,是系统常驻运行的核心。
消息处理层 (MESSAGE PROCESSING LAYER):业务逻辑流转的核心,包括路由系统、会话管理、Agent 执行器、媒体处理、出站投递等,一条消息从进入系统到最终响应的关键动作都发生在这里。
扩展与插件层 (EXTENSION & PLUGIN LAYER):所有可插拔的扩展,包括(钉钉/飞书/Telegram等)通道插件、技能(Skill)与工具(Tool)系统、以及子 Agent 机制。
基础设施层 (INFRASTRUCTURE LAYER):为整个系统提供通用能力,包括配置与密钥管理、结构化日志、定时任务、事件总线、记忆检索、沙箱安全等。
二、一条消息的完整执行路径
以“帮我整理今天的重要邮件,提炼待办,并生成一份给老板的简报”为例,消息在系统中的旅程如下:
第1步:消息进门与协议适配
消息源:消息从钉钉、飞书等外部平台进入。
协议适配:每个外部渠道都有专属的通道插件,它将异构的原始消息清洗并统一成标准内部对象 MsgContext,屏蔽了底层平台的差异。
最终化处理:dispatchInboundMessage 函数对 MsgContext 进行最终收束,补全字段、标准化格式。
第2步:前置治理(去重、拦截)
去重 (Deduplication):系统为每条消息生成一个 idempotencyKey(如 whatsapp1||main:+1234567890|msg_123),缓存中若存在该键则直接返回,防止因 Webhook 重试等导致的重复处理(默认TTL 20分钟)。
拦截 (Interception):对于 /stop 等控制命令,系统会快速拦截,直接中断对应的 Agent 任务,而不是继续执行。
快速响应:对于 Web 请求,会先通过 WebSocket 返回一个 started 状态,让用户知道任务已开始执行。
第3步:路由分发与排队
路由系统:系统根据绑定规则(通道、账户ID、用户等维度)决定消息该交给哪个 Agent(如 assistant、vip-assistant)。
会话键:确定 Agent 后,系统构建唯一 sessionKey(如 assistant:discord:channel:987654321),用于会话隔离和并发控制。
车道机制:系统采用两级并发控制:
会话级车道:相同 sessionKey 的消息必须串行执行,确保上下文连贯,防止乱序。
全局级车道:限制整个系统的最大并发数,防止运行时过载。
第4步:上下文组装
消息进入执行队列后,系统为 Agent 组装一个完整的上下文环境,顺序如下:
系统提示词:从 AGENTS.md、SOUL.md、TOOLS.md 等文件加载,定义 Agent 的角色、行为规则和安全边界。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
技能提示注入:加载当前 Agent 可用的技能(Skills),包括工具调用说明、调用边界等,让 Agent 知道自己能做什么。
记忆召回:系统会提示 Agent,在回答与历史决策、偏好、待办等问题时,先通过记忆搜索工具查询 MEMORY.md 和 memory/*.md 文件,再回答。,因为这些文件每次运行都会消耗 tokens,系统会限制:单文件最大字符数,总注入字符数上限,是否显示截断警告,系统提示词本身也要受到上下文预算约束。
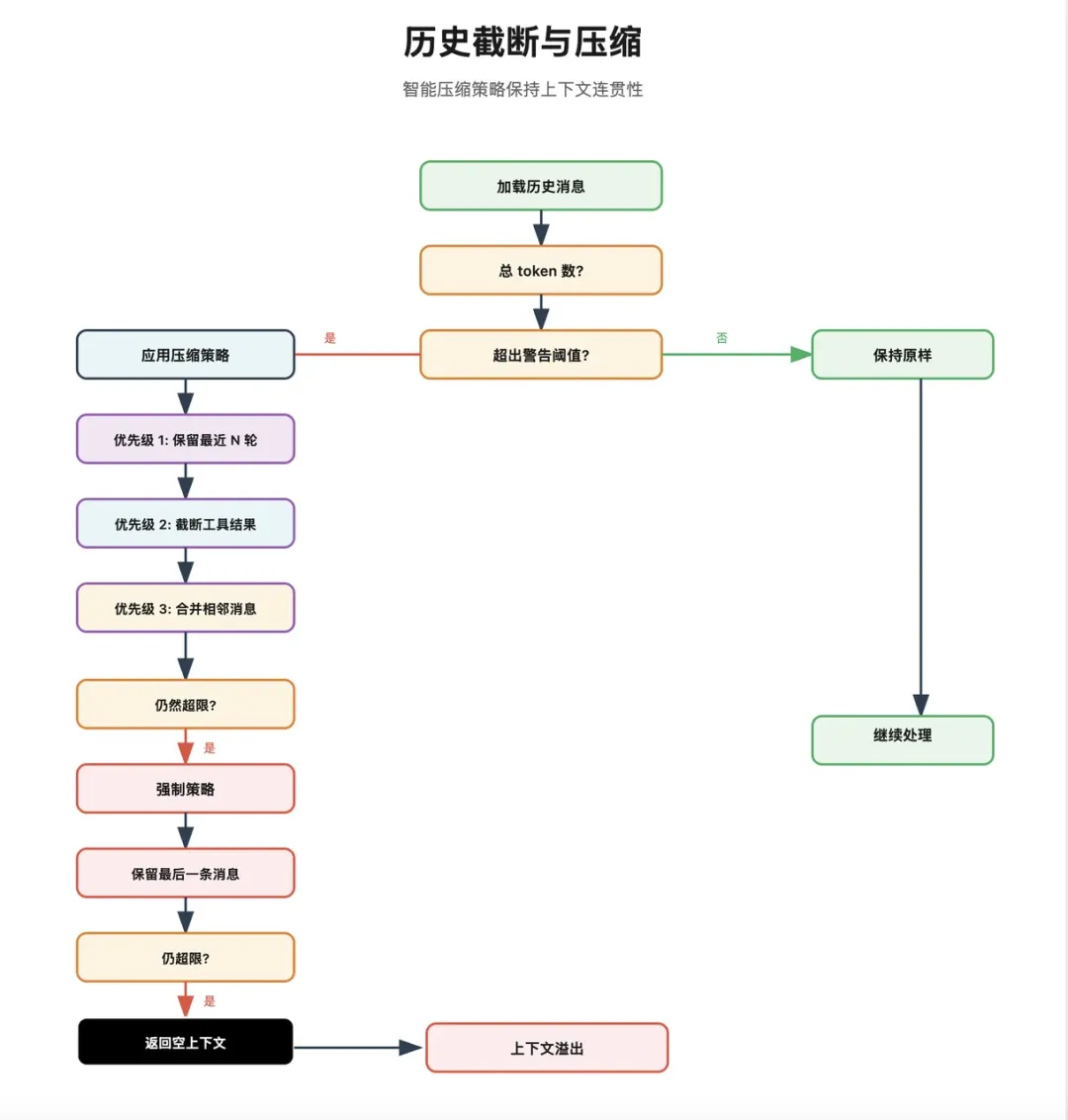
对话历史:从 JSONL 转录文件中加载最近的对话轮次,并进行智能压缩(如截断工具结果、生成摘要)以控制 token 预算。
当前消息:最后将用户当前输入、消息元数据等注入。
第5步:Agent 执行与响应
流式响应:使用 SSE 或 WebSocket 实现流式输出,降低用户感知延迟。
工具调用:当 LLM 判断需要调用工具(如读文件、调API)时,系统暂停文本流,执行工具,再将结果反馈给 LLM 继续推理。
多级错误处理与模型回退:系统不假设模型永远稳定,会处理限流、认证错误、超时、上下文溢出等问题,并有对应的降级策略。
响应投递:回复分发器根据消息来源通道,调用对应通道的出站适配器(如钉钉、WhatsApp)发送结果,甚至支持跨通道回复。
第6步:任务完成与收尾
会话持久化:更新 sessions.json 元数据,并将本次交互(用户消息、AI回复、工具调用等)追加到 JSONL 转录文件。
资源释放:释放会话车道锁、全局并发配额,标记幂等键为已处理。
记忆维护:通过文件监视器、定期同步、增量同步等机制保持 Markdown 文件与向量/全文索引的同步,支持高效的记忆检索。
三、核心组件拆解
1. 多 Agent 协作
核心能力:主 Agent 可根据任务复杂度,通过 sessions_spawn 工具动态创建子 Agent (subAgent)。
典型流程:
主 Agent 接收用户任务,拆解为子任务。
创建子 Agent,并通过提示词明确其职责边界(“你不是主Agent,你就是来做这一个子任务的”)。
子 Agent 独立执行,完成后将结果回传给主 Agent。
主 Agent 汇总所有结果,最终回复用户。
配置继承:采用三级配置继承机制(Agent级 > 全局默认 > 代码默认),确保多 Agent 系统灵活且可控。
2. 记忆系统
长期记忆:存储在 MEMORY.md 等文件中,Agent 启动时通过 Bootstrap 系统直接注入,用于存储项目规则、API 文档等常青知识。
每日记忆:存储在 memory/YYYY-MM-DD.md 文件中,通过记忆搜索工具按需检索,带有时间衰减权重。
Memory Flush 机制:在上下文即将被压缩前,系统会主动提示 Agent 将本轮对话中值得保留的信息写入每日记忆,相当于打了一层“记忆护城河”。
记忆压缩:
-
列表项历史轮次限制是系统会根据通道配置限制保留的历史轮数,从最新消息开始往前扫描。 -
列表项工具结果截断是如果系统把长文本,大json数据,多页或大段网页内容一股脑的全塞给上下文,系统会自动截断工具输出,并判断是否要保留尾部关键信息。如果尾部有错误信息或 JSON 结构,就会采取“头尾保留”策略,否则只保留开头。 -
列表项自动压缩是当上下文窗口接近模型限制时,系统会把早期历史分块,然后为每块生成摘要,用摘要替换早期历史,所以这不是机械裁剪,而是一种语义压缩。摘要生成时要求保留,活跃任务,操作进度,用户最后请求,已做决策,后续依赖信息。 -
列表项容错与降级是如果压缩后仍然超限系统还会继续尝试:切换到上下文更大的模型,降低 Agent 的 thinking 级别,最终回退为提示用户重置会话
3. 技能系统 (Skills)
Skills 不是简单的函数列表,而是一套方法包,先让 Agent 知道怎么用工具,在它决定调用时再连接真实工具实现。
加载流程:发现(从多个来源扫描)→ 过滤(依据平台、权限等条件)→ 安全检查(Profile、Sandbox、SubAgent 三层管道)→ 生成提示词(注入系统提示词)。
4. 会话车道机制
目的:防止同一会话的并发消息导致上下文错乱。
实现:为每个 sessionKey 维持一个串行队列,保证一个会话在任意时刻只有一条消息占用执行上下文。