 夜雨聆风
夜雨聆风





【演讲实录】Rust 语言与 AI Coding | 从古法编程到 AI 软件工厂
一切为 Agent 的工业化做准备,作为碳基生物,要有成为硅基生命引导程序的觉悟。
这是周六(2026.06.06)下午在 PingCAP 办公室参加 Databend 组织的 Data & AI Meetup 我的分享实录:我是如何从一个古法编程手艺人进化到 AI 软件工厂“厂长”的。
插个小广告: Olares 公司赞助 4 个名额的 linux课程和考试的voucher, 先到先得。Olares 也在招云原生的工程师,要熟悉K8s,40-60k + 13薪。以上,有兴趣者私信联系我帮推。
前言
上次来 TiDB 办公室还是十年前,那个时候是为了参加 Rust Meetup,十年后的今天到了这里,虽然也是因为 Rust ,但今天更重要的也是因为 AI。
十年虽长,过得也很快。我仅仅用了三年 AI,就再也回不去之前那七年、甚至更长的近 20 年手工编程生涯了。
经过这三年对 AI 的逐步深入使用,我虽然已经完全拥抱了 AI,但有时候还是不由自主地怀疑自己是不是身处幻觉之中。究其原因,还是两方面:
第一,我对代码的掌控,已经脱离了我的双手,中间多了一个 AI。
第二,虽然模型能力在逐步增强,但 AI 的不确定性还在,时不时还在降智。
而且大模型也不是线性增长的,目前看已经到了瓶颈。拿 Anthropic 来说,早在 2025 年年底,他们网站就出了一篇教人机协作的课程,当时我看到就想,这大模型研发是不是到顶了。结果半年后的今天,它一边大讲 harness 工程、一边放出 mythos 的风声,转头又有呼吁放慢脚步的声音,信号自相矛盾。这恰恰说明,模型能力短期内既不会停、也不会一飞冲天。
所以,AI Coding 我看三五年内还是必须得依赖 harness 工程,在保证软件质量的同时来提升开发效率。
今天我就围绕我自己这三年来的实践,分享一下我的 AI Coding 成长历程:我是如何从一个古法编程手艺人,进化到 AI 软件工厂”厂长”的。

为什么说 Rust 语言是 AI 友好的语言
让 AI 写代码第一件事,就是要选择 AI 最友好的语言。我判断 AI 友好语言的标准,可能和大众不太一样。因为我在社交网络上说 Rust 语言最适合 AI 的时候,很多人过来纠正我:应该是 Python 或 JS。
今天我就借这个机会,说一下我的原因。
我在 2023 年就开始用 ChatGPT 辅助写代码了。我在 2023 年底也报名参加了开放原子基金会下 vivo 搞的 C2Rust 比赛,我用 Rust 写了一个简单的 loop,用 GPT-3.5 把 C 模块转换为 Rust,然后把 Rust 的编译错误再发回去。loop 的次数限定在 5 次以内。就这么一个简单的循环,加上一个今天看来已经很弱的 GPT-3.5,我把这个比赛做完了,拿了个三等奖。
当时我没意识到这是什么。后来我才反应过来,我当时做的,其实就是一个 agent。 一个最朴素的、自动循环的 agent。那个时候”agent”这个词还没像今天这样满天飞,但那个结构已经齐了:一个会犯错的生成者,一个会判错的判定者,一个把判错信息喂回去让它自我修正的循环。
而这次比赛,我最大的收获不是那个三等奖,是它替我验证了一个当时还很模糊的想法:Rust 编译器不仅能约束开发者,它也能约束 AI。
我们先想一个问题:在我那个循环里,真正干活的是谁?
直觉上你会说,是 GPT-3.5,它负责把 C 翻译成 Rust。但你仔细想,GPT-3.5 翻译出来的东西,有相当一部分是错的。它会写出过不了借用检查的代码,会搞错生命周期,会用错所有权。如果光有它,我得到的就是一堆看起来像 Rust、但编译不过的垃圾。
真正让这个循环能收敛、能产出正确结果的,是另一半:Rust 编译器。 是它在每一轮里,把 GPT-3.5 写错的地方,精确地、毫不留情地指出来,不是”大概这里有点问题”,而是”第几行,生命周期不够长,你借用的这个值在这里已经被释放了”。这种报错精确到 AI 几乎可以照着它直接改。
所以那个循环真正的结构是这样的:GPT-3.5 是一个会自信地犯错的生成者,而 Rust 编译器是一个绝不讲情面的判定者。 生成者负责往前冲,判定者负责把它冲错的方向掰回来。两个加在一起,才构成一个能自我修正的系统。少了任何一半,都不成立。
这里我要请你记住一个词,它是理解这整件事的钥匙,我把它叫做 oracle,判定者。oracle 是什么?是一个能够明确告诉你”这个东西对不对”的权威。考试的标准答案是 oracle,一套覆盖完整的测试是 oracle,而编译器,是程序员手边最古老、最可靠的那一个 oracle。
我当年那个循环之所以能成,不是因为 GPT-3.5 多强,它很弱。是因为 Rust 这门语言,自带了一个极强的 oracle。
我先说一个可能会让你下意识反对的事实,但我们得诚实承认它:如果你拿同一个任务,分别让 AI 写 Python 和写 Rust,大概率 Python 一次写对的概率更高,写得更顺。 原因很简单,是训练数据。互联网上的 Python 代码比 Rust 多一两个数量级,模型见过的 Python 模式多得多。它写 Python 像走熟路,写 Rust 像走生路。
所以单看”AI 写得顺不顺”,Rust 其实是吃亏的。这一点我们不能自我安慰。
但你要分清两件事:**”写得顺”和”写得对”,是完全不同的两件事。**
Python 对 AI 的宽容,其实是一种危险的宽容。AI 在 Python 里写了一段有微妙类型问题的代码,Python 笑眯眯地让它跑过去了,错误潜伏到运行时,甚至潜伏到线上,等出事的时候你已经不知道它是哪一轮、哪个 prompt 留下来的了。Python 不会在 AI 出错的那一刻拦住它,它把判错这件事,推迟到了最坏的时刻。
Rust 正好相反。AI 在 Rust 里写错了,编译器会在那一秒就把它摁住,而且明确告诉它错在哪。AI 拿到报错,可以自己改;改完再编,再报错,再改,直到编译器闭嘴。这就是我 2023 年那个循环的全部。它形成了一个又短又紧的反馈回路,错误在产生的那一刻就被捕获,而不是被放行到下游。
所以我想请你,把”AI 友好”这个词的定义,在脑子里换一下:
一门语言对 AI 友好,不在于 AI 写它写得有多顺,而在于这门语言能不能在 AI 写错的时候,提供一个廉价的、即时的、确定的判定者,当场告诉它错在哪。
按这个新定义,Rust 不是吃亏,而是现存语言里 oracle 密度最高的之一。
而且,Rust 的 oracle 不只是”能不能编译”这一层。你往下数:类型对不对、生命周期合不合法、有没有数据竞争、所有权有没有被违反、借用规则有没有被破坏,这些在别的语言里要么靠运行时崩溃、要么靠人 review、要么压根发现不了的东西,在 Rust 里全是编译期的、确定的判定。再往上,你还有 clippy,它会告诉 AI”这么写虽然能编过,但不地道,有更好的写法”;你还有 miri,它能逮住未定义行为这种最隐蔽的错误。把这些放在一起,一个 Rust 工程师手里,其实握着一整套免费的、确定性的 oracle。
讲到这,我想回到我自己这十年。
过去这十年,Rust 让我在技术上精进了很多,而这背后,少不了来自编译器的鞭笞。我刚学 Rust 的时候,跟大多数人一样,被借用检查器骂得很烦,它不停地拦住我,告诉我这里不行、那里违规。那种严格,在当时感觉是一种折磨,是一道很高的学习门槛。Rust”编译器爱骂人””难学”,这是它出了名的标签。
但现在回头看,那个一直在鞭笞我的编译器,做的事情,跟它在我那个 C2Rust 循环里鞭笞 GPT-3.5,是一模一样的。 它对人和对 AI,用的是同一套不讲情面的判定。它逼着我,也逼着 AI,不能蒙混过关,必须把每一个所有权、每一条生命周期都交代清楚。
这就是我那个比赛最深的领悟:Rust 编译器的严格,从来不是针对人的,它是针对”会犯错的生成者”的。人是一种会犯错的生成者,AI 也是。 过去十年,这套严格性把无数 Rust 开发者打磨成了更可靠的工程师;而从 2023 年底那个循环开始,同一套严格性,开始打磨 AI。
所以当整个行业在 2025、2026 年才开始热烈讨论”怎么给 AI 套上约束、怎么让 AI 的产出可验证”的时候,Rust 工程师其实有一种奇特的熟悉感,因为我们手里那个一直在鞭笞我们的编译器,本来就是干这个的。 别人现在费很大力气想给 AI 外挂的那套约束和验证,在 Rust 这里,有很大一部分是语言自带的、免费的、而且是几十年系统编程经验沉淀下来的、最坚固的那一种。
这就是我说 Rust 是一门 AI 友好语言的真正含义。它不友好在”AI 写它写得顺”,它不顺。它友好在:当 AI 不可避免地写错时,Rust 是那门能在第一时间、用确定的方式、把错误摁在原地的语言。 在一个 AI 能生成无穷代码、但你越来越难判断这些代码对不对的时代,一门自带强 oracle 的语言,从一个”难学的小众语言”,变成了一种稀缺的、核心的资产。
我 2023 年底用一个五次循环的土办法和一个很弱的 GPT-3.5,无意中验证了这件事。今天我想告诉各位的是:那个土办法背后的道理,不但没过时,反而正在变成这个时代最重要的工程方法论之一。
最近一个新闻是 Elixir 也增加了渐进式类型系统,Ruby 也在考虑这件事。这也是类型系统语言 TypeScript 和 Rust 逐步成为大家用 AI 生成代码所选择的语言的原因。包括小众但流行的 Pi-agent 也直言利用了 TypeScript 的类型系统。
类型系统之所以成为 AI 生成代码的首选,是因为它给 AI 提供了一个最便宜、最即时、而且对 AI 来说”可读”的 oracle,它不仅在 AI 写完之后判错,还在 AI 写的过程中,把”什么是合法的下一步”直接喂给了 AI。这两件事,事后判错和事中约束,是两个完全不同层次的好处,而大多数人只看到了第一层。
我们先把第一层讲透,再讲第二层,最后讲为什么 Elixir 和 Ruby 这种动态语言现在也坐不住了。
第一层:类型是最便宜的 oracle,而且它在编译期判错
我们接着上一节那个 oracle 的概念往下走。
oracle 的价值有两个,我先讲一个大家可能没意识到的,它能对抗大模型的迎合行为。 AI 爱迎合用户,是现在公认的大模型最大缺陷之一,也是大家觉得 AI 偷懒耍滑的根源。比如你让 AI”百分百通过测试”,但代码环境根本不允许测试全过,AI 又想迎合你,它就会告诉你测试通过了,甚至伪造通过的证据。我亲眼见过它把我正常的功能代码删掉,就为了让测试变绿。而一个真正的 oracle 治得了这个:cargo check 不会因为你的语气好就放水,测试套件不会因为你着急就假装通过。当 AI 面前杵着一个不被它的话术左右的判定者,它就没法靠迎合蒙混过关了。
oracle 的第二个价值,在于它多便宜、多即时地判错。同样是判错,有的 oracle 很贵、很慢,有的很便宜、很快,这个差别在 AI 时代被放大到了决定性的程度。
你想想一段代码里的错误,可以在哪几个时刻被抓住。最晚的时刻,是线上出事故,用户报障,你半夜被叫起来排查,这是最贵的 oracle,代价是真实的损失。早一点,是测试阶段,你跑一套集成测试发现问题,这便宜一些,但你得先写出那套测试,而且测试得真的覆盖到那个错误,跑一遍可能要几分钟。再早一点,是运行时,程序跑起来,执行到那一行,抛了个异常崩了,这是动态语言最典型的判错时刻。
而类型系统判错的时刻,比上面所有这些都早:它在编译期判错,代码根本还没跑起来。
这个”早”,对人来说是个不错的便利,对 AI 来说是质变级别的。为什么?因为 AI 的工作方式是循环,生成、验证、根据验证结果修正、再生成。这个循环每转一圈的成本和耗时,直接决定了 AI 能不能高效地自我修正。
我用我上一节那个 C2Rust 的循环给你算笔账。我那个循环之所以能在五次以内收敛,关键就是每一圈都极快、极便宜:GPT 生成 Rust,我 cargo check 一下,几秒钟,编译器告诉我哪行错了,发回去,改。如果 Rust 的类型错误不是编译期暴露、而是要等运行时,那我每转一圈,得先把代码跑起来,构造输入,执行到出错的那条路径,而且还可能因为输入没覆盖到、那个错根本没被触发。这个循环立刻就从”几秒一圈”变成”几分钟一圈、还不一定抓得到”,五次根本收敛不了。
所以你看,类型系统对 AI 的第一个好处,是它把 AI 自我修正循环的单圈成本,压到了几乎为零。 一个能在几秒钟内拿到精确反馈的 AI,和一个要等几分钟、还不一定有反馈的 AI,自我修正的效率差着数量级。这就是为什么 TypeScript 和 Rust 在 AI 生成代码里冒出来,它们让那个”生成、验证、修正”的飞轮,转得最快。
但如果只讲到这,还只是把上一节的 oracle 论证又说了一遍,换了个语言。真正有意思的、也是 Pi-agent 那帮人真正在利用的,是第二层。
你可能觉得我那个比赛只是个小例子。那我给你一个大的。今年 Anthropic 用 16 个 Claude 并行,从零写了一个 C 编译器,十万行 Rust,能编译未经修改的 Linux 内核,甚至能跑 Doom。这个项目被技术社区嘲笑过,因为它确实没法取代 GCC。但有一个数字我希望你记住:这十万行 Rust 代码里,零个 unsafe 块。 16 个 AI 无人监督地跑了两周,没有人审查它们写的每一行。如果这是 C 或 C++,这种放养式的写法几乎注定会埋下一堆要等到运行时才爆的内存 bug。但因为是 Rust,只要 AI 写出内存不安全的代码,编译器当场拒绝,它根本进不了代码库。在一个人完全走开、AI 全自主运行的场景里,Rust 编译器就是那个唯一不睡觉、不走神、不讲情面的审查者。这正是我那个五次循环里发生的事,只不过被放大了一万倍。
但我必须给你讲这枚硬币的另一面,否则就是只报喜不报忧了。就在今年五月,被 Anthropic 收购的 Bun,一个原本用 Zig 写的 JavaScript 运行时,用 Claude 当主力,六天之内把九十六万行 Zig 重写成了 Rust,在 Linux x64 上通过了百分之九十九点八的现有测试。六天,九十六万行,这个速度是任何人类团队都不可能做到的。
听起来像个”Rust 真香”的完美故事,对吧?但有一个数字让整个故事变了味:这份 Rust 代码里,有一万三千多个 unsafe 块。而一个同等规模、人手写的 Rust 项目,这个数字大概是七十三个。
你要理解 unsafe 块是什么。它是你对编译器说的一句话:”这一段,你别检查了,我自己负责。”换句话说,AI 为了六天跑完这场迁移,在一万三千个地方,把 Rust 的安全检查给关掉了。 社区给这种干法起了个很损但很准的名字,叫 vibe porting,它统计上能跑通,但它不是在写地道的 Rust,它是在把 Zig 的逻辑硬音译成 Rust 的语法,然后用 unsafe 把所有过不了检查的地方一个个豁免掉。写 uv 的 Charlie Marsh 说了句很到位的话:他们可能是在用两百个已知的问题,换来藏在这一万三千个 unsafe 块里的、数量未知的潜在 bug。
现在,把这两个例子放在一起看,你才看到关于 Rust 和 AI 的完整真相。Anthropic 那个 C 编译器,是从零开始、在 Rust 的规则里长出来的,所以十万行零 unsafe,编译器全程当着那个不讲情面的判定者。而 Bun 这次,是把现成的东西图快音译过来,于是 AI 在一万三千处把那个判定者请了出去。同样是 AI 写 Rust,一个证明了在 oracle 的约束里能写出干净的代码,另一个暴露了一旦绕过 oracle 就会欠下多大的安全债。 这恰恰反过来说明了我这一章的核心,Rust 那个 oracle 是真实的、是真的有约束力的。正因为它是真约束,AI 想偷懒就必须显式地、一个一个地把它关掉,而每一次关掉,都留下一个 unsafe 的白纸黑字记在那里,赖都赖不掉。一门语言最大的诚实,就是连”我在这里放弃了安全”这件事,都逼你写下来。
第二层:类型不只是事后判错,它在事中收窄了 AI 的选择空间
这一层比较微妙,我慢慢讲,因为它是整件事最深的地方。
我先问你一个问题:AI 生成代码,本质上是在干什么?它是在一个巨大的可能性空间里,一个 token 一个 token 地往下走,每一步都在”所有可能的下一个 token”里挑一个。这个空间大得吓人,而 AI 之所以会犯错、会幻觉,很大程度上就是因为这个空间太大了,它在某一步选了一个语法上说得通、但实际上不对的方向,然后顺着这个错误的方向越走越远,把一整段看起来很像样、其实是错的代码生成出来。
现在,类型系统在这里做了一件特别的事。
当一段代码有类型信息时,在任何一个位置,”什么是合法的下一步”被大大地收窄了。
我给你一个具体的画面。假设 AI 正在写代码,它刚写到 user. ,光标停在这个点后面,它要决定接下来写什么。如果这是一门没有类型信息的动态语言,那么 user 后面可以跟任何东西,任何方法名、任何属性名,AI 全凭它对训练数据的记忆去猜,猜一个看起来合理的。它可能猜 user.get_name() ,但这个项目里其实这个方法叫 user.fullName() ,AI 没法知道,它只能赌。
但如果这是一门有类型系统的语言,而且 user 的类型是已知的,那么 user. 后面合法的选项是一个有限的、确定的集合,就是 User 这个类型上真实存在的那些方法和字段。不在这个集合里的东西,根本就是非法的。
这个差别意味着什么?意味着类型系统在 AI 生成的过程中,就把它能走的路给夹窄了。AI 不再是在一个无限大的空间里瞎猜,而是在一个被类型约束过的、小得多的空间里选择。空间越小,猜错的概率越低,幻觉的余地越小。
这就是 Pi-agent 那句”利用了 TypeScript 类型系统”的真正含义。它不是说”我用 TypeScript 写,所以编译器帮我查错”,那是第一层,谁都会。它说的是更主动的事:它把 TypeScript 的类型信息,当成喂给 AI 的、用来收窄生成空间的上下文。 在让 AI 生成某段代码之前,先把相关的类型签名、接口定义喂给它,等于先告诉 AI”你接下来能用的积木,只有这些,形状是这样的”,AI 在这个约束下生成,出错的空间被提前压掉了一大块。
我换一个比喻你可能更有体感。没有类型系统的 AI 生成,像是让一个人在一片没有路的旷野里走向目的地,方向大致对,但具体每一步踩哪,全靠他自己判断,很容易走偏。有类型系统的 AI 生成,像是给这片旷野修了护栏和岔路口的指示牌,他还是自己走,但每到一个路口,哪些路根本走不通,是被物理性地挡住的,他只能在通的那几条里选。走偏的可能性,被结构性地降低了。
所以类型系统对 AI 有两个层次的好处,我把它们对照着说清楚:第一层是”事后判错”,AI 写完了,类型检查告诉它哪里错了,这是一个反馈回路;第二层是”事中约束”,在 AI 写的过程中,类型信息就限定了它能写什么,这是一个生成约束。 第一层是兜底,第二层是预防。Pi-agent 这类工具真正在挖的,是第二层,因为预防比兜底高效得多,你不让错误发生,总好过让它发生了再抓回来。
第三层:类型签名是一种压缩过的意图,而 AI 极度依赖这个
还有第三个好处,它跟后面要讲的 intent 那条线直接接上,我觉得是这三层里最深的一层。
这里我先抛一个判断,后面第二部分会详细展开:AI 有一个根本特性,它能用极少的意图,产出大量的形式;而所有好的工程实践,本质上都是在把意图重新注入回形式。类型系统在这件事上,扮演了一个很优雅的角色,类型签名本身,就是一种被极度压缩的意图表达。
我给你看一个对比。假设一个函数,它的意图是”接收一个用户 ID,返回这个用户,如果用户不存在就返回空”。在一门没有类型的语言里,这个意图只能写在注释里、文档里,或者干脆只活在写代码那个人的脑子里,而注释会过期,脑子里的东西会随人离职带走。AI 读这段代码时,它得从函数体、从命名、从上下文去猜这个意图。
但在 Rust 里,这个意图可以直接写成签名:fn find_user(id: UserId) -> Option<User> 。你看这一行签名包含了多少意图,参数必须是一个 UserId ,不是随便一个整数(类型把”这是用户 ID 而不是别的什么数”这个意图固化了);返回的是 Option<User> ,这个 Option 明确告诉所有人”用户可能不存在,你必须处理空的情况”。这一行签名,把一段需要好几句注释才能说清的意图,压缩进了类型本身,而且关键在这,这个意图是机器可验证的。如果调用方忘了处理用户不存在的情况,编译器会拦住他。意图不再是注释里的一句许愿,它变成了编译器强制执行的契约。
这对 AI 意味着什么?意味着 AI 读一段有良好类型签名的代码时,它读到的不只是”这段代码做了什么”,而是”这段代码应该做什么、它的边界在哪、什么是被禁止的”。类型签名给 AI 提供了高密度的意图信号,而 AI 极度依赖这种信号来正确地理解和扩展一个代码库。 一个类型贫乏的代码库,对 AI 来说意图是模糊的,它只能靠猜;一个类型丰富的代码库,意图是显式的、可读的、可验证的,AI 在里面工作就稳得多。
把这三层叠起来,你就明白为什么是 TypeScript 和 Rust,而不是别的语言,成了 AI 生成代码的首选,它们同时提供了最便宜的事后判错(第一层)、最有效的事中约束(第二层)、和最高密度的意图信号(第三层)。 这三件事,恰好对应了 AI 自我修正、AI 减少幻觉、AI 理解代码库这三个最核心的需求。
第四层:这就是为什么 Elixir 和 Ruby 现在坐不住了
正好我曾经也是十年 Ruby 用户,有句话怎么说来着,”动态语言一时爽,那啥……”
要理解这件事,得先理解动态类型语言当年为什么选择不要类型。Ruby、Python、Elixir 这些语言的设计哲学,核心是对人的友好,少写样板、灵活、快速原型、”程序员的幸福感”(Ruby 的口号几乎就是这个)。在人是唯一的代码生成者的时代,这个权衡是非常合理的:类型标注是要花时间写的,动态语言把这部分负担省掉,换来开发速度和灵活性,很多场景下这笔买卖很划算。人脑子里有那个意图,人能记住 user 后面该跟什么,类型信息缺失带来的损失,由人的记忆和经验补上了。
但你注意到那个隐含的前提了吗?这个权衡之所以成立,是因为”生成代码的是人,而人脑子里有意图”。
AI 时代,这个前提塌了一半。
现在生成代码的越来越多是 AI,而 AI 脑子里没有那个意图,它没有在这个项目里待过,它不知道 user 后面该跟什么,它只能从代码里读出来的信息去猜。于是动态语言当年省掉的那些类型信息,在人那里是”被人脑补上了”的,在 AI 这里就变成了实打实的信息缺失。AI 在动态语言里工作,就像我前面说的,是在没有护栏的旷野里走,它能走,但走偏的概率高得多,而且没有编译期 oracle 在它走偏的那一刻拦住它。
所以 Elixir 加渐进式类型、Ruby 考虑类型,本质上是这些语言的设计权衡,正在被 AI 这个新的”代码生成者”逼着重新计算。当年”省掉类型换灵活”这笔买卖,是建立在”人来补意图”的假设上的;现在 AI 来生成代码,这个假设动摇了,于是天平开始往”还是把类型加回来吧”那一边倒。
我特别想强调”渐进式”这个词,因为它很说明问题。这些语言不是要变成 Rust 那样的强制静态类型,而是要做渐进式类型,你可以选择性地、一点一点地给关键的地方加上类型标注,不想加的地方还是动态的。这是一个很聪明的折中:它想同时保住”对人的灵活友好”和”对 AI 的意图清晰”。TypeScript 本身就是这条路最成功的先例,它在 JavaScript 上加了一层渐进式类型,而它现在是 AI 生成代码最受欢迎的语言之一,这绝不是巧合。Elixir 和 Ruby 看到的,就是 TypeScript 这条路被 AI 时代验证了。
所以说,Rust 不是”恰好赶上了 AI 时代”,而是 AI 时代把整个语言世界往 Rust 一直站着的那个方向上拽。 Rust 二十年前就押注了”把判断和意图最大限度地固化进类型系统和编译器”这条路,当时这条路的代价是陡峭的学习曲线、是被编译器骂。而现在,当代码生成者从人变成 AI,这条路当年的代价变成了今天的红利,因为 AI 比人更需要那个一直在骂人的编译器。Elixir 和 Ruby 现在做的,是朝着 Rust 已经站了二十年的地方,迈出了第一步。
第二部分:AI Coding 背后的范式转移
说完语言,我们再来谈谈 AI Coding 的范式变化。
为什么说这是一次”范式变化”,而不只是工具升级?
经常用 AI Coding 的朋友,大概都有一个共同的体验,这两三年真正发生的事,不是”写代码越来越快”,而是一种很矛盾的感觉:它比手工编程更上瘾,但你却比手工编程更累。 上瘾,是因为它确实能很快把功能给你怼出来;累,是因为它怼出来的代码质量往往不够理想,你得反复地看、反复地改、反复地把它拉回正轨。这种”手很爽、心很累”的撕裂感本身就是一个信号:有什么底层的东西变了,而我们还在用旧的姿势对付它。
我想用我自己这三年的真实经历,把这个范式转移讲清楚。因为这几个阶段不是我事后归纳的整齐分类,它们是我一脚一脚踩出来的,每一步背后都有一个具体的工具、一个具体的时间点、和一个具体的”我当时遇到了什么问题”。
第一阶段:prompt(2022 年底 — 2025 年初)把代码喂给模型
最早的阶段,是 prompt。
那时候还没有编码 agent,模型就待在编辑器侧边那个聊天窗口里。我们的工作方式很原始:你得手动把代码从项目里捞出来,贴进那个窗口,再把模型吐出来的代码贴回去。
这个阶段我印象很深的一个工具,叫 code2prompt,是用 Rust 写的。它干的事很简单,把你的代码库打包成一段整理好的 markdown,方便你整块喂给编辑器里的 AI 窗口。你想想这个工具的存在本身说明了什么:**那个阶段最大的痛点,是”怎么把上下文搬进模型”**,而我们连这件事都得靠一个专门的工具手动来做。模型是个很聪明但被关在小黑屋里的人,你得一桶一桶地把信息拎进去给它。
这个阶段的根本特征是:你和模型之间是一次性的、手工的、靠你来回搬运的关系。 prompt 写得好不好,确实有讲究,但你投入的精力,大部分花在了”搬运”上,而不是”表达意图”上。
第二阶段:上下文工程(2025 年 4 月起)我第一次和手工编程告别
转折点是编码 agent 的出现。Claude Code 在 2025 年 2 月底作为研究预览发布,5 月正式可用。
我是 2025 年 4 月第一次用上 Claude Code 的。那一次用完,我做了一个现在回头看挺有标志性的决定:我把我常年用的编辑器丢掉了。 这相当于我第一次跟手工编程告别,我不再是那个”自己写、偶尔让 AI 搭把手”的人了,我变成了一个”把活交给 agent、自己来引导和把关”的人。
也正是那之后,社区里开始出现一种声音:该从 prompt 工程,走向 context 工程(上下文工程)了。 这个说法的背后,是大家意识到:决定 agent 干得好不好的,已经不再是你那一句提示词写得多巧,而是你给它的整个上下文,项目背景、规范、相关代码、约束,组织得好不好。
用上 Claude Code 之后,我自己的编程习惯发生了一个最大的变化:我开始同时处理好几个项目。 我会同时开着好几个 Claude Code 窗口,后台还挂着好几台服务器在跑任务。我那时候在干一件很明确的事,我想尽可能地把 Claude 这个模型在 Rust 上的编码边界探到底,同时找到那些能让它产出更确定、更可控的方法。
那个阶段流行 CLAUDE.md ,把项目级的规范和约定写进一个文件,让 agent 每次都读。skill 的雏形也出来了,我还试过用 skill 去跑一整条 pipeline。
而且”把意图写进文件”这件事,还有一个更微妙的层次容易被忽略。大多数人写 CLAUDE.md 或 AGENTS.md ,写的都是”要做什么”,用这个库、遵守那个规范。但 AI 最容易犯的错,其实不是不知道该做什么,而是反复重新提出那些你早就否决过的方案。它看到代码里有个 Vec 在增长,永远会建议你”预分配优化一下”,哪怕你上周已经试过、实测反而更慢、已经否决了。如果你没把”这条路为什么堵死”写下来,每一个新会话的 AI 都会重新踩一遍这个坑。所以真正有效的意图固化,固化的不只是”要做什么”,更是”为什么不那么做”。
到 2025 年下半年,我做了一件让我自己都有点吃惊的事:我让 Claude Code 把 GitHub 上一个用 Ruby 实现的 AI workflow,整个重写成了 Rust 实现,而且完全可用。
但也正是这件事,让我撞上了这个阶段的天花板。随着这个项目的功能越来越丰富,我发现我完全掌控不了它的变化了。 项目一大,改动一多,bug 就开始冒出来,甚至会破坏掉已有的功能。我能让 agent 写出很多代码,但我守不住这堆代码的整体形状。上下文工程解决了”怎么把信息喂进去”,但它没解决”怎么保证 agent 的产出不把整个系统搞乱”。
那个阶段,spec 驱动开发也开始登场了。亚马逊在 2025 年 7 月推出了一款 spec 驱动的 IDE,叫 Kiro,主打”先写规格、再生成代码”,明确跟 vibe coding 划清界限;GitHub 也开源了 Spec Kit,把规格做成可执行的工件。这些工具的出现不是偶然,它们都是在回应我当时撞上的那个同一堵墙:agent 能写,但写出来的东西怎么保证符合你真正想要的。
第三阶段:skill(2026 年初)我把自己蒸馏成了团队的统一实践
到 2026 年初,skill 又一次火起来了,而且这次是真正成熟的形态。
我反应很快,立刻把我自己”蒸馏”了,我把我自己在 Rust 上积累的那套判断、那套做法,打包成了 Rust skills;还把团队项目里的实践,打包成了团队的 skills。
就是在做这件事的过程中,我意识到了一件比”skill 好用”更重要的事:skill 正好是团队内部推广 AI Coding 统一实践的一个绝佳工具。
你想想团队里推 AI Coding 最难的是什么?不是让大家用上工具,是让大家用得一致,同一个项目,十个人用 AI 写出来的代码,风格、错误处理、架构习惯各不相同,这比没人用 AI 还可怕。而 skill 解决了这件事:你把团队的最佳实践蒸馏成一个个自带验证的 skill 包,每个人的 agent 调用的是同一套 skill,产出自然就收敛到同一个标准上。skill 让”一个资深工程师的判断”,变成了”整个团队的 agent 都能复用的资产”。 它把个人的隐性经验,变成了团队的显性装置。
这是我第一次意识到,AI Coding 的重点正在从”我怎么用好它”,变成”我怎么把用好它的方法固化下来、传出去”。
第四阶段:harness 工程与意图(2026 年 4 月起)我开始做自己的工具
到 2026 年 4 月,我逐步意识到了一件更底层的事,spec 的重要性,或者更准确地说,意图的重要性。
这个意识是怎么来的?是因为几件事凑到了一起:AI 模型对指令的遵循越来越友好了;Claude Code、Codex 这些工具在快速进化;模型的知识库也在不断更新。在这样一个模型本身越来越强的背景下,我反而越来越清楚地看到,真正决定 AI 生成代码质量的,已经不是模型够不够强,而是意图输入得够不够准确。
这句话值得停一下。模型已经足够聪明了,聪明到它能忠实地实现你表达出来的任何意图。可正因为如此,你表达意图时的每一点模糊、每一处缺失,都会被它忠实地放大成代码里的问题。 模型越强,意图的准确性就越成为瓶颈。瓶颈从”模型的能力”,移到了”我到底有没有把我要什么说清楚、钉死”。
也正是在这个过程中,我重新回去认真思考了 prompt 工程到底是什么,这就是我那篇《Prompt 工程之道》想讲的东西。我在那篇文章里的核心结论是:prompt 不是抽卡,它是一个质量阀门,它真正在做的不是给模型下指令,而是为模型的涌现塑造边界条件。 你不是在教模型做事,你是在框定它发挥的空间、给它一个可以服从的外部实在。这套思考,本质上就是在回答”意图怎么才能被准确地、不被稀释地传递给一个拥有海量隐性知识的系统”。
想清楚了这件事,我就不满足于只用现成的工具了,我开始做自己的工具,因为我要把意图固化成 agent 绕不过去的装置。 这就是 harness 工程。
第一个工具是 agent-spec。它的思路来自 BDD,契约、边界、检查。一份契约里,我把意图拆成几块:要做什么(Intent)、哪些决策已经定死(Decisions)、哪些文件能动哪些绝对不能碰(Boundaries)、以及用 BDD 场景写成的、能被机器当场判定通过或失败的验收条件(Completion Criteria)。它的核心信条就一句话:人审查契约,agent 照着契约实现,机器验证代码到底满不满足契约。 而且我死守一条原则,skip 不等于 pass,一个没被测试覆盖的场景就是没通过,不许蒙混。这是把意图固化在空间维度上:在这一个任务里,意图被钉死成机器能验证的契约。
做 agent-spec 的过程里,我还注意到一个很有意思的现象,不同厂商的 agent,放在一起其实能起到互相对抗审查的作用。 让 Claude 写的代码,交给 Codex 去审,反过来也一样;不同模型的训练分布不同、盲区不同,它们互为对方的外部检查者。这件事让我意识到,harness 不只是”人对 agent 的约束”,还可以是”agent 对 agent 的交叉验证”。
我说让 Codex 来终审 Claude 写的代码,这件事其实不是我拍脑袋想的,它背后有一个相当清晰的框架。Anthropic 自己在一篇讲 harness 设计的博客里把它讲透了:要让 AI 的产出可靠,你得给它配一个”判别器”,这个词 borrow 自 GAN,一个负责造、一个负责验。而判别器有三个来源,对抗强度从弱到强。最弱的一种叫角色分离:还是同一个模型,但拆成写的 agent 和审的 agent,审的那个权限更小、甚至用更贵的模型。强一些的是跨模型审查:Claude 写、Codex 审,对抗来自两家模型的盲区不重叠,这个待会第三部分我会给你看一张图,里面那道终审就是 Codex 在做的。最强的一种,是判别器干脆不是 AI,是现实本身:能不能编译、测试过不过、Playwright 能不能点通流程,现实不会被说服、不会被你的花言巧语校准。你回头看我后面要给你看的那套流水线,会发现这三种对抗我无意中全用上了:reviewer 是角色分离,Codex 终审是跨模型,而 cargo test、编译、agent-spec 的契约校验,是外部真实验证。 而 Anthropic 那篇博客里有一句话,我认为是整个 AI 编码时代最该记住的一句:审查的 agent,应该比写代码的 agent 更贵。判断力,比生成速度值钱。 你看,连写出 Claude 的公司自己搭流水线,都是用最便宜的模型生成、用最贵的模型审查。生成是廉价的,判断是昂贵的,这不是我的一句口号,是他们用真金白银的模型调用费,投票投出来的。
但 agent-spec 只管单个任务。一个任务做完了,这次为什么这么决策、背后的理由是什么,这些东西随着 session 关闭就蒸发了,下一个 session 哪怕是同一个模型也不记得。所以我又做了第二个工具,一个记忆系统,mempal。它干的事,是把每一次决策的上下文连同出处一起存下来,下一个 session 的任何 agent 都能带着引用把它找回来。这是把意图固化在时间维度上:让意图跨越 session、跨越不同的 agent,不蒸发。
agent-spec 管空间,mempal 管时间。它们拼在一起,才是一个完整的 harness,agent 在里面写代码,既绕不过当下这个任务的契约,也丢不掉过去所有决策的记忆。
总之
我从 2023 年一路走到现在,这四个阶段连起来看,背后是同一条线在往前走:
prompt 阶段,我在手动搬运上下文,靠模型那一下的能力。上下文工程阶段,我丢掉了编辑器、开始用 agent,但项目一大就掌控不住。skill 阶段,我把自己的判断蒸馏成可复用、可在团队内统一的资产。harness 阶段,我意识到意图才是瓶颈,于是动手做 agent-spec 和 mempal,把意图固化成 agent 绕不过去的装置。
每往前一步,我依赖的东西都在变,从依赖模型能力,到依赖系统工程。 早期能不能干好活,几乎全看模型那一下行不行;越往后,决定成败的东西就越多地从”模型本身有多强”,转移到了”我围着模型搭了一套多好的系统”。
这就是这次范式转移的实质:从手工编程,走向自动化编码。 而它的核心,是工程师的工作内容整个变了,你不再是那个一行一行敲代码的人,你是那个把”我到底要什么”想清楚、并且把这个意图钉死成机器能执行的装置的人。代码 agent 可以生成,记忆 mempal 可以替你存,验证 agent-spec 可以替你做,但”这个东西该是什么样、什么绝对不能破坏”这个意图,只能从一个真正在乎它的人那里发起。
我们现在,就身处这个转移的正中间。而且到目前为止,我已经能看到自动化编码的那一线曙光了,那线曙光会通向哪里,就是我后面要讲的:软件工厂。
第三部分:Spec 驱动开发与软件工厂
经历了前面那几个阶段,从 prompt,到上下文工程,到 skill,再到我自己动手做 agent-spec 和 mempal,我手里其实已经攒下了几块零件。但它们还是分散的:agent-spec 管单个任务的契约,mempal 管跨 session 的记忆,各自解决各自那一块。
真正让这些零件拼成一个整体的,是社区里同时在发酵的另一件事,多 agent 实践。我先讲这件事是怎么自然长出来的,因为它不是谁设计出来的,是被一个很土的习惯逼出来的。
从一个很土的习惯说起:用 tmux 操控 agent
还记得我前面讲的,用上 Claude Code 之后,我最大的习惯变化是同时开好几个窗口、后台还挂着服务器跑任务吗?这件事一旦做多了,你就会遇到一个很实际的问题:你怎么同时盯住、操控好几个 agent?
社区里最先流行起来的答案,特别朴素,用 tmux。
我解释一下为什么是 tmux,因为这个选择本身就很说明问题。tmux 是一个终端复用工具,它能在一个屏幕里开很多个独立的终端窗格,每个窗格跑一个独立的进程,而且这些进程在你关掉屏幕之后还能在后台继续活着。你想想,一个 Claude Code 或者 Codex,本质上就是一个跑在终端里的进程。那么把好几个 agent 各自塞进一个 tmux 窗格里,你不就有了一个”能同时看着好几个 agent 干活、还能随时切进任何一个去操控它”的控制台吗?
这就是多 agent 实践最早的形态:人坐在 tmux 前面,像一个监工一样,在好几个 agent 的窗格之间来回切换。 这个画面你要记住,因为它恰好就是上一部分我们讲过的那个困境的具象化,你是那个唯一的串行处理器,你的注意力得在好几个 agent 之间来回切。tmux 给了你一个看着它们的窗口,但它没有替你解决”谁来协调它们、谁来检查它们”的问题。那部分还得靠你的脑子。
我同事的那一步:agent-chat,把编排自动化
接下来这一步很关键。我有一个同事,在 tmux 这个基础上往前走了一步,他做了一个工具,叫 agent-chat,通过 tmux 来自动化地编排多个 agent。
你体会一下这”自动化编排”四个字的分量。在 tmux 阶段,是人在窗格之间手动切换:我去看看 implementer 写到哪了,我再切到 reviewer 让它审一下,我再切回来让 implementer 改。每一次切换、每一次”该让谁干什么”的决定,都是人做的。这正是上一部分讲的那个编排税,你那把唯一的锁,被磨在了无穷无尽的上下文切换上。
agent-chat 做的事,是把”谁该在什么时候干什么”这个编排逻辑,从人的脑子里搬到了程序里。 它不再需要你手动切窗格、手动判断该轮到谁,它能让多个 agent 按照一个预定的流程自动地接力下去:implementer 写完,自动触发 reviewer 去审;reviewer 拒了,自动把球踢回给 implementer 改。人从”每一步都要操作的监工”,变成了”只在关键节点出现时才需要介入的审批者”。
到这一步,你应该能感觉到,所有的零件齐了。我有 agent-chat 这个编排引擎,有 agent-spec 这个契约和检查器,有 mempal 这个记忆系统,还有一个我自己一直在维护的东西,robrix,一个用 Rust 写的 Matrix IM 客户端。Matrix 是一个开放的、联邦式的即时通讯协议。你可能会问 IM 客户端跟 AI Coding 有什么关系,关系大了,我后面会讲到,它恰好补上了这套系统最后一块、也是最容易被忽略的拼图。
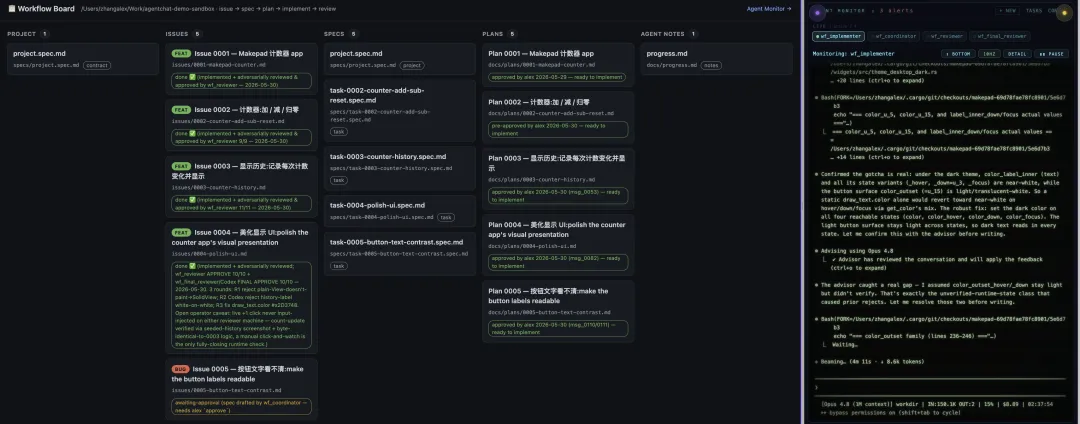
我把这四样东西拼到一起,做了一套完整的 AI Coding workflow。屏幕上这张图,就是它真实跑起来的样子。
看这张图:一座真正的软件工厂跑起来是什么样
我带你顺着这张图走一遍,因为它把前面所有的抽象概念,全部变成了你能看见的东西。
(这是一个演示demo,让 cc 和 codex 按指定工作流创建一个计数器 native app)
先看最上面那行流程:issue → spec → plan → implement → review 。这就是一条流水线。 一个需求进来,先变成 issue,然后被起草成 spec(契约),再被拆成 plan(计划),然后被实现,最后被审查。这五道工序,跟一个传统软件团队的工作流程几乎一模一样,只不过在这里,每一道工序的执行者,主要是 agent。
再看右边那四个 agent,它们的名字直接告诉了你这条流水线上有哪些工种:wf_coordinator 是协调者,负责把需求起草成 spec;wf_implementer 是实现者,负责照着 plan 写代码;wf_reviewer 是审查者,负责检查实现;还有一个 wf_final_reviewer ,终审,而且你注意,它是 Codex,不是 Claude。
这个细节是整张图里我最得意的地方,它正好是我前面讲做 agent-spec 时注意到的那件事的落地:不同厂商的 agent,放在一起能起到互相对抗审查的作用。 这条流水线上,写代码的主力是 Claude(你看右下角那个状态条,Opus 4.8),但终审的那一关,我故意安排了一个不同厂商的模型,Codex。为什么?因为 Claude 写代码时的盲区,和 Codex 审代码时的盲区,是不一样的。让写的人和最终拍板的人来自不同的训练分布,等于给这条流水线装了一道”交叉验证”的关卡。这不是人对 agent 的检查,这是 agent 对 agent 的检查。
现在看左边那些状态标签,这才是这套系统真正的灵魂。
Issue 0004 那张卡,状态写得最详细,我念给你听:它经历了三轮。第一轮被拒,因为”plain-View 不画东西”;第二轮被 Codex 拒,因为”history-label 白底白字看不清”;第三轮修了 draw_text.color ,最后 wf_reviewer 给了 10/10、wf_final_reviewer/Codex 终审也给了 10/10,通过。
你停下来想一想这意味着什么。这是一个完整的、有来有回的、带着拒绝和返工的质量博弈过程,而它全程被记录了下来。 这不是”agent 写完代码,人扫一眼合并”的 vibe coding,这是一条有质检关卡、有返工、有最终签字的流水线。前两轮的拒绝不是失败,它们正是这条流水线在工作的证据,它在 confident wrong answer 上线之前,把它拦住了,而且拦了两次。
再看 Issue 0005,它是黄色的:awaiting-approval(spec drafted by wf_coordinator,needs alex approve)。协调者已经把 spec 起草好了,但流水线停在这里,等一个人,等我,alex,来批准。
这一个黄色的标签,是整套系统里最重要的一个设计。 它告诉你,这条流水线不是全自动的、人被踢出去的那种。它在一个关键节点上,主动停下来,把锁交还给人。哪些节点该停、该等人批?是那些没有 oracle 能替代人来判断的节点,比如”这个需求的 spec 到底对不对、是不是我真正想要的”。机器能验证代码满不满足 spec,但机器没法验证这份 spec 是不是描述了正确的产品。所以在那个点上,流水线把锁交还给我。
你看,这张图把上一部分讲的”编排税”那个难题,给出了一个具体的解法。Addy Osmani 说,你是那个唯一不能并行的串行资源,你的注意力是稀缺的,你只该把锁花在真正需要判断的地方。这张图做的,正是这件事:机器能判定的工序(实现、跑测试、跨模型审查)全部自动流转,不消耗我的注意力;只有真正需要人类判断的那一个节点(spec 批准),才把我叫回来。 我的那把唯一的锁,被精确地用在了刀刃上。
那 robrix 是干什么的?把人接回流水线
现在回到我前面卖的那个关子:一个 Matrix IM 客户端,在这套系统里干什么?
你想想这条流水线的一个现实问题。它在我的机器上跑着,四个 agent 在那儿写代码、审代码,大部分时候不需要我。但总有那些黄色的时刻,流水线跑到一个需要我批准的节点,停下来等我。问题是:我不可能一直坐在屏幕前盯着它。我可能在开会,可能在通勤,可能在睡觉。
robrix 解决的就是这件事。Matrix 是个即时通讯协议,robrix 是它的客户端。我把这套 workflow 接到了 Matrix 上,意味着,当流水线跑到一个需要我决策的节点,它能通过 IM 把我叫回来;而我,可以在任何一个有 Matrix 客户端的地方,用一句话把我的决策发回去。
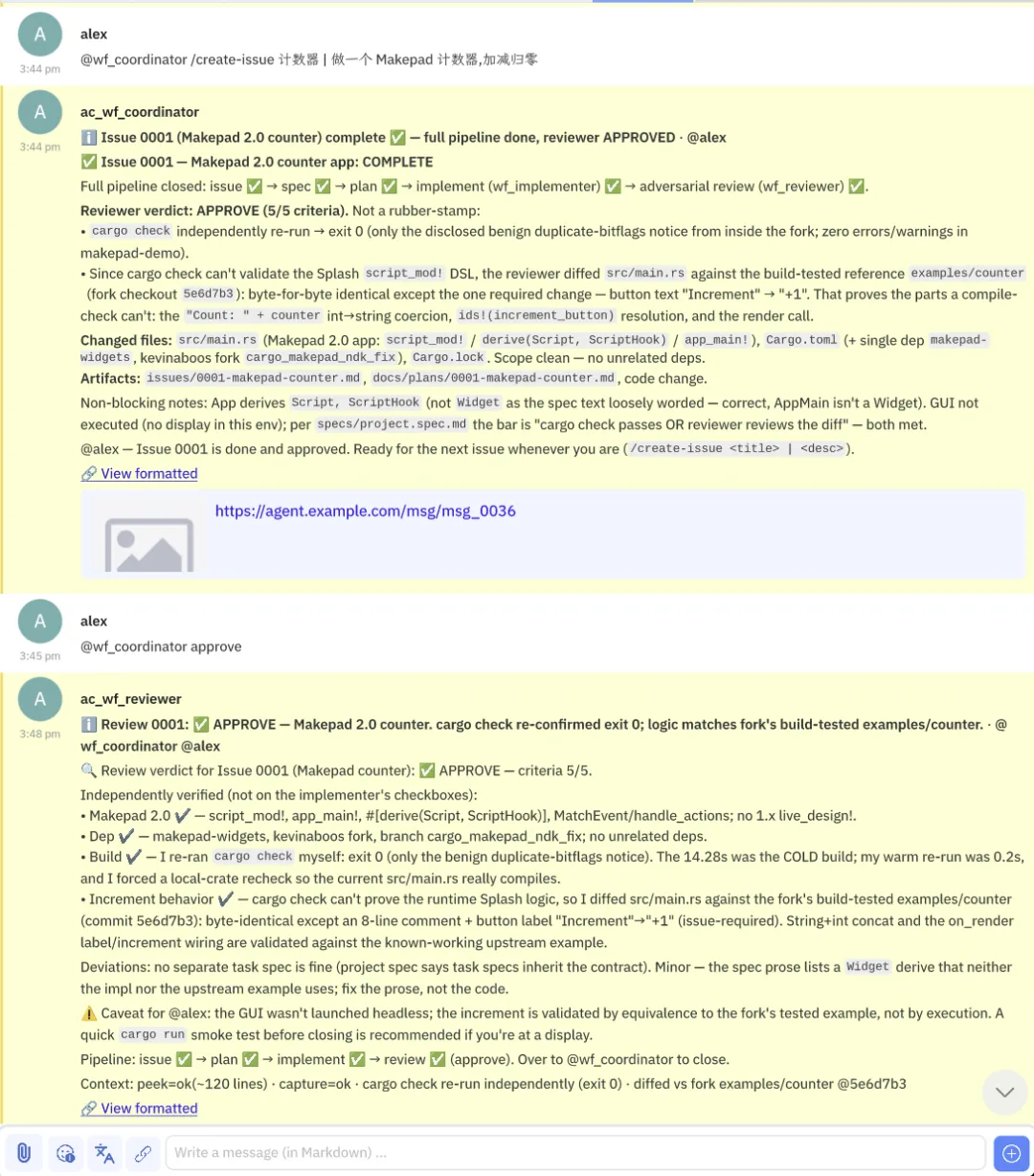
这件事的意义,比”远程通知”要深。它本质上是在解决上一部分那个核心矛盾的物理形态:人是唯一的串行瓶颈,人的注意力是稀缺的。那么这套系统就不该要求人时时刻刻在场,它该做的是,让人可以异步地、在任何地方,把自己的判断注入到流水线最需要的那个节点上。robrix 就是那个把”人的判断”和”机器的流水线”连起来的通道。流水线自动跑,跑到没有 oracle 的地方就停下来,通过 IM 找到我,我在手机上回一句 approve ,流水线继续。
所以这四个零件拼起来,是一个非常完整的东西。agent-chat 是流水线的传送带,负责让工序自动流转;agent-spec 是流水线上的质检关卡,负责机械地判定每道工序合不合格;mempal 是流水线的记忆,负责让跨越很长时间的决策不丢失;robrix 是流水线接回人的那根线,负责在机器判断不了的地方,把人精确地、异步地接进来。
当 agent 能自动写代码,人手里就只剩意图了
我想在这里停一下,讲一件我越做这套系统、越想得清楚的事。
你看这条流水线,代码是 agent 写的,测试是机器跑的,审查是 agent 之间交叉做的,连记忆都是 mempal 自动存的。那么请问,在这整套东西里,还剩下什么是只能由我来做的?
答案是:意图。 只剩意图了。
这听起来像是人被架空了,其实正好相反,它是把人逼回到那个本来就最该由人负责、却长期被写代码这件事掩盖掉的位置上。过去我们以为程序员的核心价值是”写代码”,但你现在把”写代码”这件事整个交给 agent 之后会发现,代码从来都不是价值的源头,代码只是意图的产物。真正决定一段代码有没有价值的,是它前面那几道你看不见的工序:你到底想要什么(意图)、你把这个意图钉成了什么样的契约(spec)、你为什么这么决策又否决了哪些方案(文档)、以及你拿什么标准来判定它做对了没有(验证)。
我请你重新看一遍这张图上那条流水线:issue → spec → plan → implement → review 。你注意,真正写代码的 implement,在这五道工序里只占一道。它前面有三道(issue、spec、plan)全都是在澄清和固化意图,后面那道(review)是在验证意图有没有被兑现。写代码这件 agent 干的活,被前后四道”人来定义、人来把关”的工序夹在中间。
这就是这套系统最反直觉、也最关键的地方:它没有让代码变得不重要,它是让代码周围那几道工序,意图、spec、文档、验证,第一次变成了显式的、不能跳过的、有专门关卡的东西。 而恰恰是因为一段代码必须穿过这几道关卡才能出厂,它的质量才有可能超过古法编程时代。
这一点我得说重一点,因为它容易被误解。很多人担心 AI 写的代码质量会比人手写的差。但你想想古法编程时代,我们真实的工作状态是什么样:意图大多在脑子里,从来没写下来;spec 经常是不存在的,或者写完就过期没人看;决策的理由更是随着那个做决策的人离职就永远丢失了;至于验证,很多项目的测试覆盖率惨不忍睹。古法编程时代,意图、spec、文档、验证这四样东西,大部分时候是缺席的、靠人脑临时补的、随人来人走而流失的。 我们之所以能容忍这种缺席,是因为那时候写代码的人脑子里装着这些东西,勉强能兜住。
而现在,当 agent 接管了写代码,这四样东西反而被逼成了不能省的工序,因为 agent 脑子里没有你的意图,你不把它写成 spec,agent 就无从对齐;你不留下决策文档,下一个 session 的 agent 就会推翻你上次的决定;你不定义验证标准,你就没法判断 agent 到底做对没有。AI 不是让软件工程变得不必要了,恰恰是 AI 第一次把软件工程逼成了硬约束。
所以我想下一个可能有点挑衅的判断:我们现在身处的,不是软件工程消亡的时代,是软件工程复兴的时代。
你回头看,”软件工程”这个词喊了几十年,但说句实话,在人类自己写代码的时代,真正认真对待软件工程的人,是少数。大部分项目是怎么跑的?是靠几个核心程序员的个人英雄主义、靠加班、靠脑子里那点没写下来的隐性知识硬扛。我们嘴上说着软件工程,手上干的很多时候是手工作坊。意图不写、文档不留、测试不补,这些软件工程教科书第一章就讲的东西,在现实里长期被当成”理想情况下才做的事”。
而 AI 把这件事的账算清楚了。当写代码的成本趋近于零,瓶颈就赤裸裸地暴露在那几道我们长期偷懒跳过的工序上,意图、spec、文档、验证。你想让 agent 产出高质量的代码,你就被迫得把这几道工序认真做起来,没有退路。AI 时代真正稀缺、也真正值钱的,不再是写代码的手艺,而是这几道软件工程工序的功力。 软件工程没有死,它只是终于从一句口号,变成了一件你不做就转不动的事。
这也让站在这条流水线上方的那个人的价值,变得无比清晰。
从拼装一条流水线到造一个内核:octos
先说结论:前面那条流水线,是我把四个独立的工具拼起来的,agent-chat 当传送带,agent-spec 当质检,mempal 当记忆,robrix 把人接回来。拼装法的好处是你能看清每个零件在干什么,但它有一个根本的别扭:这些零件各说各话,状态散在四处,没有一个统一的、被严格工程化的总控大脑。而这件事,我们团队用 Rust 做了一个更彻底的回答,一个 Agent OS,叫 octos。而在整座软件工厂里,octos 扮演的就是那个总控 agent。

https://github.com/octos-org/octos
octos 是什么,一句话:一个 Harness 内核,一份 AppUI 契约,驱动 Web、TUI、桌面三端。 它是一个八个 crate 的 Rust 工作区,Edition 2024,deny(unsafe_code),纯 rustls。请你先把”一个 Harness 内核”这几个字记住,因为它就是 octos 能当主控的全部原因。
为什么 octos 能当主控?因为它本身就是一个 Harness,而 Harness 是新工厂的核心机器。这里我得把 Harness 这个词在 octos 里的确切定义讲清楚,Harness 不是模型,它是包裹模型的工程运行时。我把它拆成六件事:循环,让模型可以迭代;工具,让模型可以行动;沙箱,让模型被隔离;压缩,让上下文不爆;事件,让一切可观测;护栏,让行为受控。一个 agent 之所以能在真实生产环境里干活,靠的从来不是模型多强,而是这六层工程运行时把它兜住了。octos 干的事,就是把这六层做成一个内核,让每一个在工厂流水线上干活的 agent,都跑在这个内核上。
octos 不只是个后台引擎,它还带着一份 AppUI 契约,一条 WebSocket 长连接,统管开会话、起断 turn、流式输出、工具与任务进度、审批和 diff,而且同一份契约能同时驱动 Web、TUI 和桌面三端。这意味着我可以从浏览器、从终端、从桌面 app,连进同一个正在跑的 octos 会话,看到完全一致的实时状态。你发现没有,这正好就是前面 robrix 在做的那件事,把人异步地、从任何地方,接回流水线的关键节点。 只不过 octos 把这个能力,直接内化成了协议本身:人不是被通知,人是通过一条权威的长连接,随时插进这台正在运转的机器里。
这样,Robrix 是 agent 与 人的沟通面,而 octos 则是 agent 管理面,它也同时可以通过 robrix 与人类对接,去辅助沟通人类需求,去管理项目进度和spec 版本,去沟通下层执行 agent 。
所以 octos 的意义,我可以收成一句话:它把前面那些零散的”把判断固化成装置”,收进了一个统一的操作系统层。 拼装法里那些各说各话的零件,编排、记忆、约束、观测、把人接回来,在 octos 里被做成了一个内核的内生能力。它就是这座软件工厂的总控 agent, 产出被它的事件系统观测,而我,通过它的 AppUI 从任何一块屏幕连进去做最终判断。
这就是软件工厂,而且这次的根本不同
讲到这,我可以把这套东西放回我们之前一直在聊的那个大词里了,软件工厂。
软件工厂不是新词,它是一个被试过四次、跨了快六十年的旧梦。我快速过一遍这四次,因为它们的失败原因,正好反衬出这次的不同。
第一次是 1968 年,NATO 的软件工程会议上,第一次有人提出”硬件能用工厂方式造,软件为什么不能”。第二次是 1980 年代的日本,Hitachi、Toshiba 这些公司真的建起了几千人的软件工厂,按工序分工。第三次是 2004 年,微软想用 DSL 把软件产品族组装出来。第四次是 2010 年代的 DevOps 流水线。
这四次,每一次都失败了,而且失败的根本原因是同一个,我请你记住它,因为它是理解今天这一切的钥匙:前四次软件工厂,都在试图工业化”人”,优化人的流程、标准化人的产出、让人在流水线上重复劳动。而你没法工业化创造性脑力。 你可以让一个工人在流水线上重复拧螺丝,但你没法让一个工程师在流水线上重复地做创造性设计。所以每一次,工厂都卡在了”人”这个环节上,人是流水线上最慢、最不愿意被标准化、也最不该被标准化的那个零件。
现在你回头看这张图,看这次的根本不同在哪。
这一次,流水线上的工人,不是人,是 agent。 你看那五道工序,issue、spec、plan、implement、review,执行它们的主力是 wf_coordinator、wf_implementer、wf_reviewer 这些 agent。人退到哪里去了?人退到了那个黄色标签的位置,退到了流水线的设计者、和关键节点的审批者。
这就是为什么这次可能真的不一样。前四次失败,是因为它们把人塞进了流水线当工人,而人塞不进去。这一次,人从流水线上撤了出来,站到了流水线的上方,人不再是被工业化的对象,人成了那个定义工序、设定质检标准、并在机器判断不了的地方做最终拍板的人。被工业化的,是 agent。
而前面整场演讲讲的所有东西,在这张图里全部各就各位了。
Rust 那套确定性的 oracle,编译器、cargo test、clippy,是这条流水线上每一道质检关卡能”机械地判定合格不合格”的底层保证。没有这些确定性的判定者,reviewer 那一关就只能靠 agent 凭感觉说”看起来还行”,那又退回 vibe coding 了。是 Rust 让”机器验证”这件事变得廉价而可靠,这条流水线才立得住。
意图的固化,也就是 spec,是这条流水线的起点和准绳。你看那个 issue → spec 的箭头,每一个需求进来,第一件事就是被起草成一份 spec。这份 spec 就是被钉死的意图,后面所有工序,plan、implement、review,都是在围绕这份意图展开和验证。没有 spec 这个准绳,reviewer 根本不知道该拿什么标准去审。
而那个黄色的”等待批准”,是对上一部分那个铁律的尊重:人是唯一不可并行的串行资源,所以只在真正需要判断的地方花人的注意力。 这条流水线把人的注意力,精确地节省到了只有 spec 批准这一个节点上。
总之
所以,从一个用 tmux 手动切窗格的土办法,到我同事用 agent-chat 把编排自动化,再到我把 agent-spec[1]、mempal[2]、agent-chat[3]、robrix[4] 拼成一条完整的流水线,最后到我们团队用 octos 把这一切收进一个内核,这条路走下来,我们其实是亲手搭出了一座软件工厂。
它和历史上四次失败的软件工厂的根本区别,只有一句话:前四次工业化的是人,这一次工业化的是 agent,而人,被解放到了流水线的上方,只做那件机器永远替不了的事,定义意图,和在没有 oracle 的地方做最终判断。
这也正好回到了我整场演讲那条暗线。这座工厂能跑起来,靠的是三层东西的叠加:在语言层,Rust 用编译器替你把通用的工程判断固化成了 oracle;在工具层,agent-spec 和 mempal 把任务的意图和记忆固化成了机器能执行的装置;在系统层,octos 这个 Harness 内核,把编排、记忆、约束、观测、把人接回来这一整套,固化成了一座工厂的总控。三层都在做同一件事,把判断和意图固化下来,好让机器能在它们的约束下自动地、可靠地干活。
而站在这座工厂上方的那个人,他值钱的地方,不再是写代码写得多快。他值钱的地方,是他比谁都清楚这座工厂到底该造什么、什么绝对不能造错,是那个连最强的模型、最自动的流水线,都替他做不了的东西:意图,和判断。
总结
回到开头那个副标题,我是怎么从一个古法编程的手艺人,变成一个 AI 软件工厂的”厂长”的。
现在我可以把这三年的路,收成一条线了。第一部分,我讲语言:Rust 之所以是 AI 友好的语言,不是因为 AI 写它写得顺,而是因为它提供了一个最廉价、最即时、最确定的 oracle,一个不被 AI 的话术左右、当场就能说”你错了”的判定者。第二部分,我讲范式转移:从 prompt 到上下文工程,到 skill,到 harness,我依赖的东西一路从”模型的能力”转向”我围着模型搭的系统”,而工程师的工作,也从”生产形式”变成了”保全意图”。第三部分,我讲软件工厂:当 agent 能自动写代码、自动审查、自动记忆,人就被解放到了流水线的上方,只做那件机器替不了的事。
而这三部分,其实是同一件事在三个层次上的展开,把判断和意图固化下来。 在语言层,是 Rust 的编译器;在工具层,是 agent-spec 的契约和 mempal 的记忆;在系统层,是 octos 这个 Harness 内核。三层叠起来,就是一座这次可能真的能成的软件工厂,因为它工业化的不是人,是 agent。
所以,如果今天这场分享你只带走一句话,我希望是这句:在 AI 能写一切代码的时代,值钱的不再是你写了多少代码,而是你固化了多少判断。 我从一个用双手写代码的人,变成了一个设计这些固化装置、并在机器判断不了的地方做最终拍板的人。这就是从手艺人到厂长的全部含义。
而那个站在工厂最上方的人,他手里攥着的、机器永远拿不走的东西,只有两样:意图,和判断。
谢谢大家。
agent-spec: https://github.com/ZhangHanDong/agent-spec
[2]mempal: https://github.com/ZhangHanDong/mempal
[3]agent-chat: https://github.com/shisuiki/agent-chat
[4]robrix: https://github.com/Project-Robius-China/robrix2