 夜雨聆风
夜雨聆风





【OpenClaw】浏览器自动化:像人一样操作网页

· · ·
能稳定执行的网页自动化,永远是先观察,再操作,最后验证。
引子:别再手工点后台了
做运营、开发、内容的人,大概率都被网页后台折磨过:签到、复制数据、填表、上传文件、保存草稿。动作不难,但重复、烦、容易漏。
OpenClaw 的浏览器自动化,解决的就是这类问题。它让 AI 按步骤打开网页、识别按钮、填写内容、上传文件、截图确认。你给流程,它负责执行。
· · ·
一、最小可用流程:先看,再点
第一步:navigate 打开目标网页,例如后台首页、表单页、编辑器页面。
第二步:snapshot 读取页面结构,找出按钮、输入框、链接、下拉框。不要一上来猜 CSS 选择器,先让页面告诉你现在能操作什么。
第三步:click、type、fill 执行动作。点击按钮用 click,少量文本用 type,大量表单字段用 fill。
第四步:screenshot 或再次 snapshot 验证结果,比如是否出现“保存成功”、按钮是否变成“已签到”。
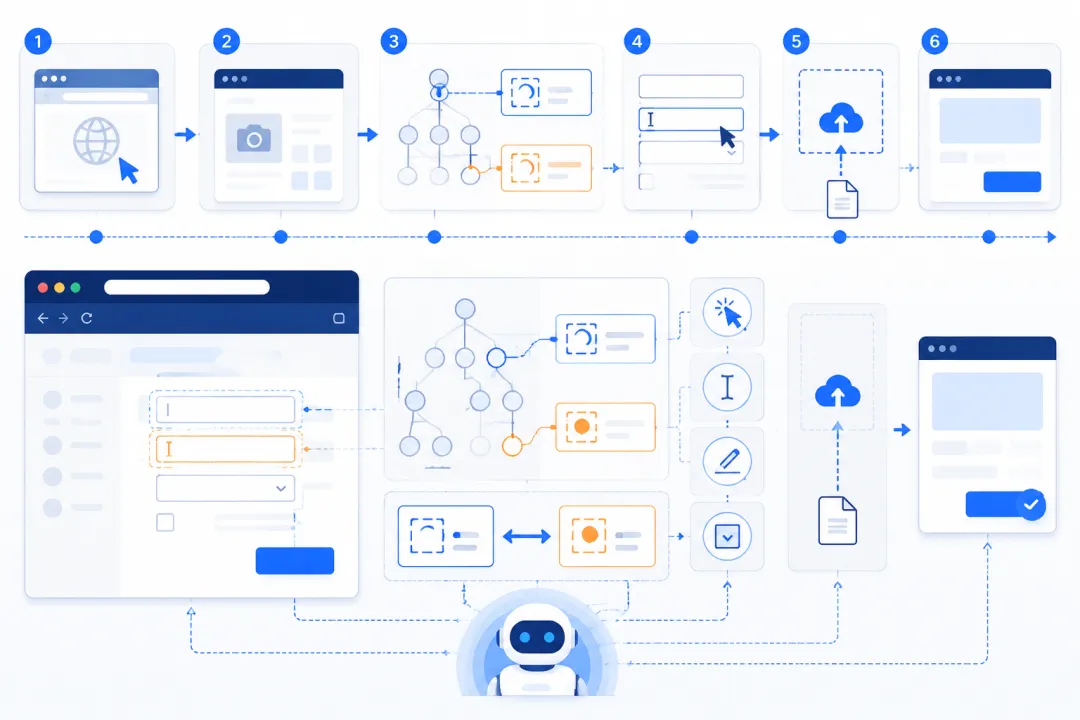
二、元素怎么找:role ref 和 aria ref
snapshot 会给页面元素生成 ref,后续操作直接引用 ref。你可以把它理解成“当前页面里这个按钮的临时编号”。
role ref 更适合快速调试。比如看到“button 文档导入”,就直接点它。优点是直观,缺点是页面复杂时可能有多个同名按钮。
aria ref 更适合正式流程。它更稳定,适合弹窗、后台系统、公众号编辑器这种组件很多的页面。
实际建议:探索用 role ref,固定流程用 aria ref;页面变化后重新 snapshot,不要拿旧 ref 硬点。
三、表单填写:先读字段,再批量填
遇到报名表、配置页、资料页,不要一个输入框一个输入框猜。先用 web_read_forms 读取字段,确认页面需要哪些信息:标题、姓名、手机号、下拉选项、是否必填。
字段确认后,用 web_fill_form 批量填写,比手动 type 更快,也更不容易漏字段。
如果前端框架没识别 fill 的值,就换成 web_type。它走真实键盘事件,适合有校验、联想和动态提示的输入框。
涉及个人信息、账号、付款、发布动作时,先确认再填写;最后提交按钮尽量留给用户确认。
· · ·
四、文件上传:不要和系统弹窗较劲
很多后台上传文件时,会弹出系统文件选择窗口。这个窗口对自动化很不友好,也容易卡住。
更稳的方式是找到网页里的文件 input,然后通过 upload 或 CDP 文件注入,把 docx、图片、PDF 直接塞进去。
公众号“文档导入”就是典型例子:进入编辑器,点击文档导入,定位上传入口,注入本地 docx,等待完成,再检查标题、图片和字数。
五、登录态怎么处理
公开网页、测试页面,用 sandbox profile 就够了。它干净、隔离,不会碰你的真实账号。
公众号后台、内部系统、云控制台,用 user profile 复用浏览器登录态。
建议先在 sandbox 跑通点击逻辑,再切到 user profile 做真实后台操作。这样更安全,也少踩坑。
· · ·
六、四个可以直接做的案例
自动签到:打开网站,snapshot 找签到按钮,click,截图确认结果,失败就记录原因。
数据抓取:打开列表页,读取表格和链接,翻页抓取,最后整理成 CSV 或 xlsx。
表单提交:读取字段,批量填写,截图给用户确认,最后再提交。
公众号自动发文:生成文章和配图,打开公众号后台,导入 docx,检查标题、图片、字数,保存草稿。
总结:把流程写清楚,AI 才能稳定执行
浏览器自动化不是魔法,关键是把动作拆细:打开哪个页面、找哪个按钮、填哪些字段、上传哪个文件、看到什么算成功、失败后怎么止损。
只要流程足够清楚,OpenClaw 就能把很多网页重复劳动接过去。下一篇我们聊记忆系统:怎么让 AI 不再每次都像第一次认识你。