 夜雨聆风
夜雨聆风





【Eviews12】Eviews12下载,Eviews安装包带激活
| 软件名称:Eviews | |
| 软件语言:简体中文 |
|
| 系统要求:Windows7或更高, 32/64位操作系统 | |
| 硬件要求:CPU@2+GHz ,RAM@4G或更高 | |
百度网盘下载链接https://pan.baidu.com/s/1fpjAfTcqBN9t9Fk9zlqqRQ?pwd=8888 夸克网盘下载链接https://pan.quark.cn/s/e98b7350b5f8 123云盘下载链接https://www.123865.com/s/j5j1jv-6evTH 备用网盘总链接https://www.kdocs.cn/l/crQ0aQ7xud0q?from=docs |
|
|
『下载方法』将链接复制到浏览器网址栏,输入提取码,点击【下载】。 『解压密码』公众号菜单栏点击解压密码,获取软件密码后,如果遇到安装问题,我们会有专业人员免费解决安装问题,直到安装成功! 如果您觉得有用,可以推荐给自己的朋友、同学,或者给我们点个右下角的“在看”,您的支持是我们做下去的动力! |
安装步骤
1、安装前请断开网络,然后将安装包进行解压
2.以管理员身份运行如下图程序
3.点Next
4.勾选 I accept,然后点Next
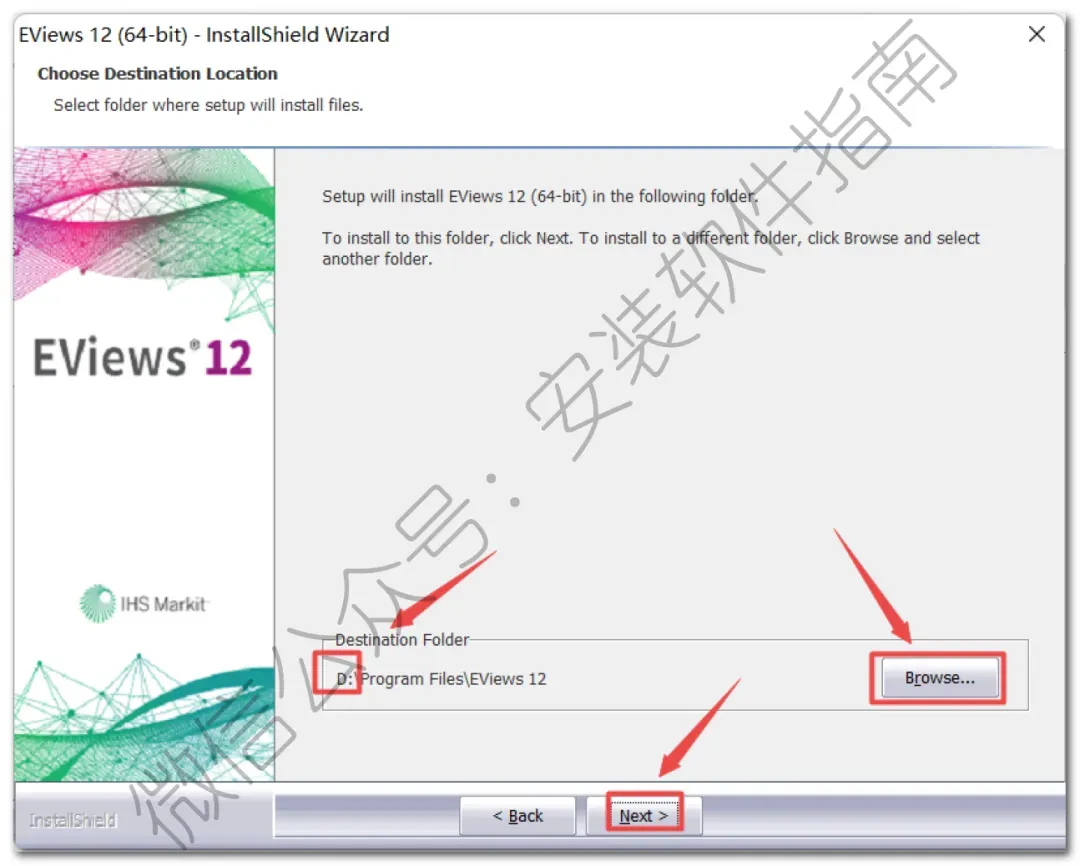
6.输入以下内容:
Serial Number: 11E11112 – 2C3B30F5 – 87654321
Name: softsara.ir
点击“Next”
7.点Next
8.、点Next
9.、点第二项NO,然后点Next
10.软件安装中,请等待
11、点是
12、点是
13、点Finish
14、返回刚开始解压出来的安装包,复制如下图程序
15、在桌面找到此软件,并打开文件所在位置
16、将刚刚复制的文件粘贴进去
17、找到并选中复制过来的“Patch.exe”文件,鼠标右键点击“以管理员身份运行”
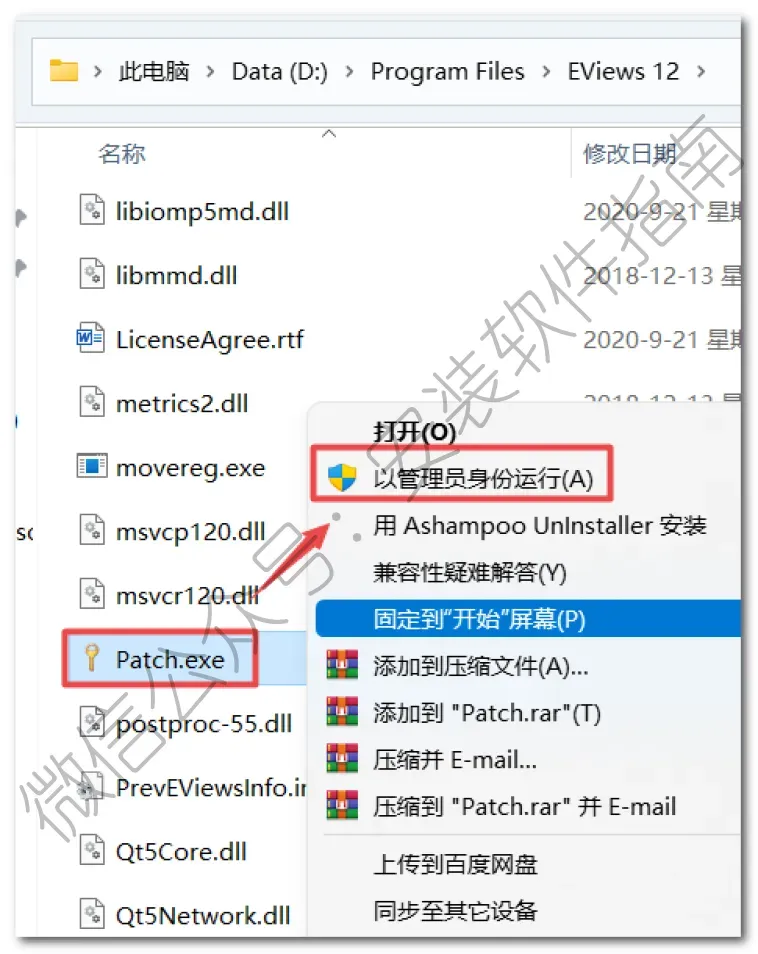
18、点patch
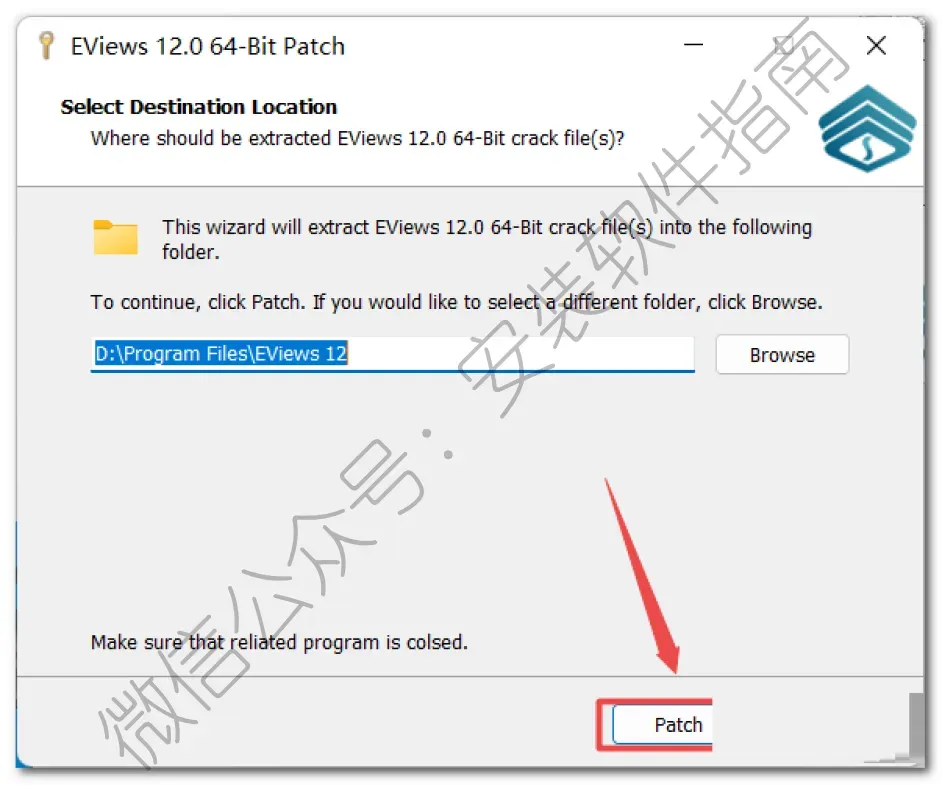
19、取消勾选,然后点Finish
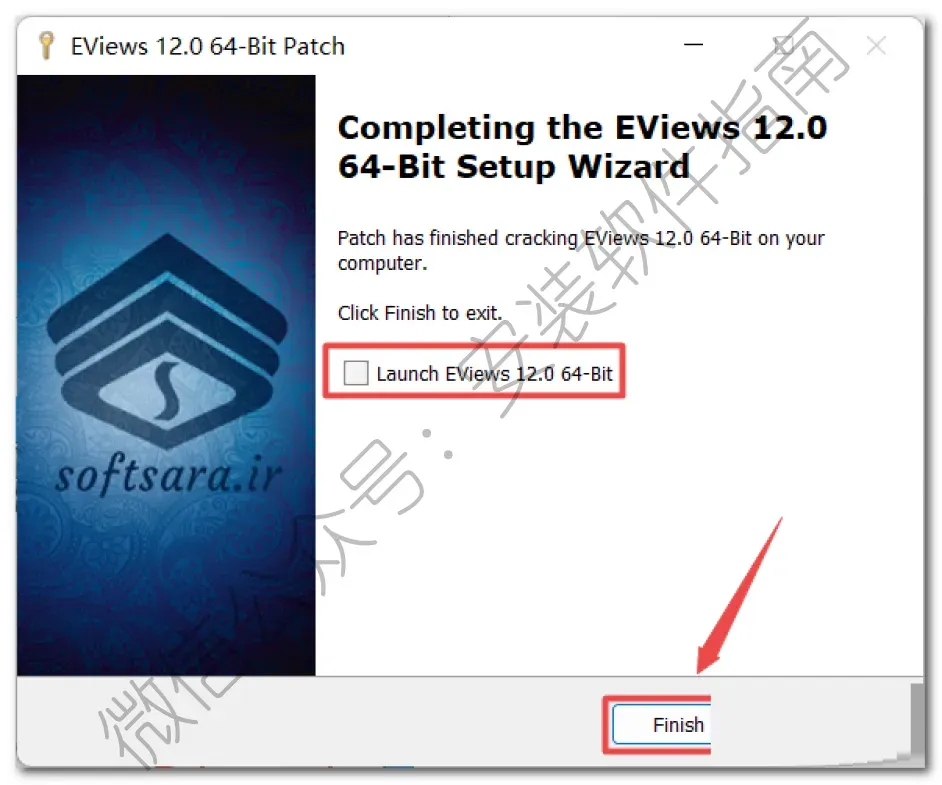
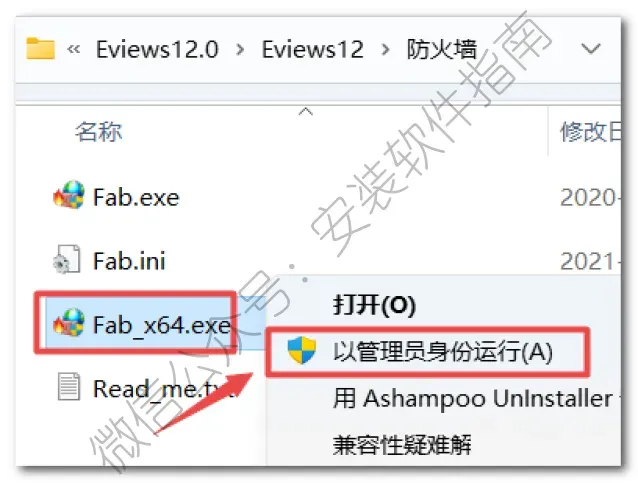
20、返回之前解压的“Eviews12”文件夹,双击打开“防火墙”文件夹,找到并选中“Fab_x64.exe”,鼠标右键点击“以管理员身份运行”
21、将EViews 12 (x64)程序直接拖动到程序界面中
22、点击“入站规则”,将EViews 12 (x64)程序直接拖动到程序界面中
23、在桌面找到此软件,并打开

24、点击顶部菜单栏“Help“,点击“EViews Registration…“
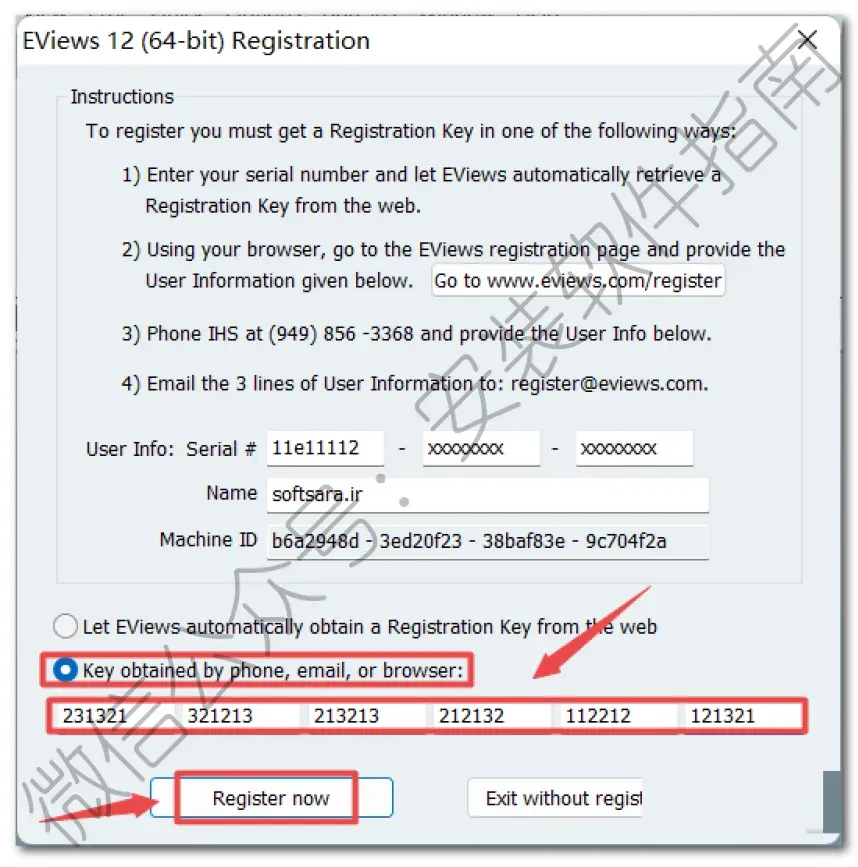
25.点选“Key…“,复制粘贴“231321-321213-213213-212132-112212-121321“ ,点击“Register Now“
温馨提示:为避免手动输入出错,建议使用快捷键复制粘贴以上内容,复制和粘贴可以使用快捷键”Ctrl+C”和”Ctrl+V”
26.点OK
27.OK软件打开界面如下图所示
做经管数据分析、写实证论文的同学和职场新人,基本都离不开EViews。不用写复杂代码,可视化操作直观,回归分析、序列检验、数据拟合一键就能跑通,算是计量入门最省心的工具。
但用久了真的发现,很多人建模翻车、预测失真、结果通不过检验,根本不是计量知识没掌握,全是软件操作的细碎坑。教程只会教点击步骤,没人提这些隐性bug,硬生生耽误论文进度。
最让人心态崩的高频问题:模型检验全过,预测结果却是一条平直线。
之前做时间序列实证分析,辛辛苦苦整理季度数据,平稳性检验、ARMA模型拟合、残差检验全部达标,参数显著性也完全符合要求。本以为模型没问题,点击动态预测后,出来的曲线直接贴平均值,毫无波动,完全不符合数据规律。
一开始反复调换模型阶数、重置样本区间,折腾大半天没用。后来才摸清问题根源,是动态预测的迭代机制导致的。小样本数据本身波动有限,动态迭代过程中误差不断累积,最后直接收敛成直线。
圈内通用的补救办法很简单,换成静态预测就能还原正常波动曲线。很多新手不懂这两个模式的区别,白白推翻重练,浪费大量时间。
工作文件类型选错,后面所有数据全部作废。
这是入门最容易踩的低级坑。新建工作文件时,很多人随手选非时序格式,后续导入年度、月度序列数据。看似能正常录入、显示数据,但后续做单位根检验、时序回归,全部都会报错或者结果失效。
我身边不少同学临查重才发现问题,整组数据全部白费,只能重新建文件、导数据、跑模型。时序数据必须严格对应时间频率,差一个选项,整套实证逻辑直接不成立。
空值NA的处理特别玄学。
做长周期数据统计,难免存在部分年份数据缺失。EViews不会主动提示空值异常,只会默默剔除缺失样本,导致前后回归样本量对不上。
之前做面板数据分析,前期描述性统计样本充足,回归结果样本量突然缩水大半,排查很久才发现是零散NA空值在作祟。更麻烦的是,手动删除空值很容易打乱时间序列顺序,一旦时序错位,整篇论文的实证结论都站不住脚。
版本兼容的割裂感,写论文阶段特别折磨人。
学校机房大多是老旧的7.2版本,自己电脑装新版10、12。新版保存的工作文件,低版本机房完全打不开,带去教室、实验室根本没法继续修改。
反过来旧版文件用新版打开,偶尔会出现变量格式错乱、数据精度丢失的情况,原本显著的回归结果,重新运行后直接变得不显著,数据偏差莫名其妙就出现了。所以定稿前,我都会统一用旧版环境核对一遍结果。
路径和命名的老毛病,依旧年年有人踩坑。
EViews对中文、空格、特殊符号的容忍度极低。工作文件、数据表格只要存在中文命名,导入数据极易乱码,严重时直接闪退、工程损坏。
而且它的保存机制很死板,异常断电、强制关闭软件后,几乎没有自动恢复文件,没手动保存的修改内容,百分百全部清零。做数据分析最忌讳中途挂机,容错率特别低。
顺带吐槽下硬件适配问题。
小体量样本数据,随便一台电脑都能流畅运行。一旦处理上千条时序数据、多变量面板模型,低配电脑跑检验会明显卡顿,迭代速度变慢,偶尔还会出现程序未响应的情况。
很多人误以为EViews轻量化不吃配置,其实大批量数据运算时,内存不足会直接导致检验结果失真,这点很少有人留意。
EViews上手简单,但想跑准结果真的不轻松。很多看似完美的模型,全是靠细节规范撑起来的。
最近一直在整理历年面板数据,每次最怕的就是样本错乱、数据精度丢失,太影响论文进度了。