 夜雨聆风
夜雨聆风





Github 147K Star 的文档转换神器MarkItDown,如何用三层架构打通 LLM 的数据壁垒
开篇:一个大模型的”阅读障碍”
你有没有遇到过这种情况——
花了一个周末搭好了 RAG 知识库,把公司三年的文档一股脑喂进去,结果检索效果一塌糊涂。PDF 里的表格变成了乱码,PPT 里的图片消失了,Excel 的多 Sheet 数据只剩第一页。你盯着 LangChain 的日志,发现向量化之前的文本就已经是残废的。
这不是你的 prompt 写得不好,也不是 embedding 模型不够强。问题的根源在更上游——大模型只”吃”文本,而真实世界的文档,是 PDF、是 Word、是 PPT、是扫描件、是带图表的 Excel。
这条路,几乎所有做 AI 应用的团队都走过。而微软的 AutoGen 团队,用一个 147K Star 的开源项目给出了答案:MarkItDown。
一、MarkItDown 是什么?
一句话:把 20+ 种文档格式一键转成 Markdown,专为 LLM 消费而设计。
它不是什么黑科技大模型,不涉及复杂的深度学习推理。它就是一个 轻量级 Python 工具,做的是一件”脏活累活”——把 PDF、Word、PPT、Excel、图片、音频、HTML、CSV、JSON、EPub、Jupyter Notebook、Outlook 邮件,甚至 YouTube 字幕和 Wikipedia 页面,统统转成结构化的 Markdown 文本。
但就是这件”脏活累活”,切中了 LLM 应用开发中最大、最普遍、最绕不过去的痛点。
截至 2026 年 6 月,MarkItDown 在 GitHub 上积累了 147,777 Star,PyPI 月下载量超过 640 万,在 MCP 生态的工具注册表中长期占据星标数第一。它没有大张旗鼓的发布会,没有顶会论文,就靠一个 README 和 pip install 一行命令,成为了 AI 基础设施层的”隐形冠军”。
这背后,藏着什么样的设计哲学?
二、核心原理:为什么是 Markdown?
在聊架构之前,必须先回答一个问题:为什么不直接提纯文本,非要转 Markdown?
答案藏在 LLM 的训练数据里。GPT-4o、Claude、Gemini 这些主流模型在训练时接触了海量 Markdown 格式文本——GitHub 上的 README、技术文档、Wiki 页面。它们对 Markdown 语法的理解是”与生俱来”的。
一段 Markdown 格式的表格,模型能准确按行按列理解;一段带层级标题的文档,模型能精准抓住结构脉络。相比之下,纯文本丢失了所有结构信息,而 HTML 则夹带了大量标签噪音。
Markdown 刚好卡在一个微妙的平衡点上:它比纯文本多了结构信息,比 HTML 少了噪音——Token 消耗通常只有 HTML 的 1/3 到 1/2。在 API 按 Token 计费的今天,这个差异直接对应着真金白银。
MarkItDown 团队在 README 里的原话很直白:
Mainstream LLMs, such as OpenAI’s GPT-4o, natively “speak” Markdown, and often incorporate Markdown into their responses unprompted.
翻译过来就是:模型天生”会说”Markdown,你喂它 Markdown,它消化得最舒服。
三、架构拆解:三层设计中的优雅
MarkItDown 的代码量并不大,核心调度逻辑只有几百行。但它的架构设计非常精妙,体现了微软工程团队对”可扩展性”的深刻理解。
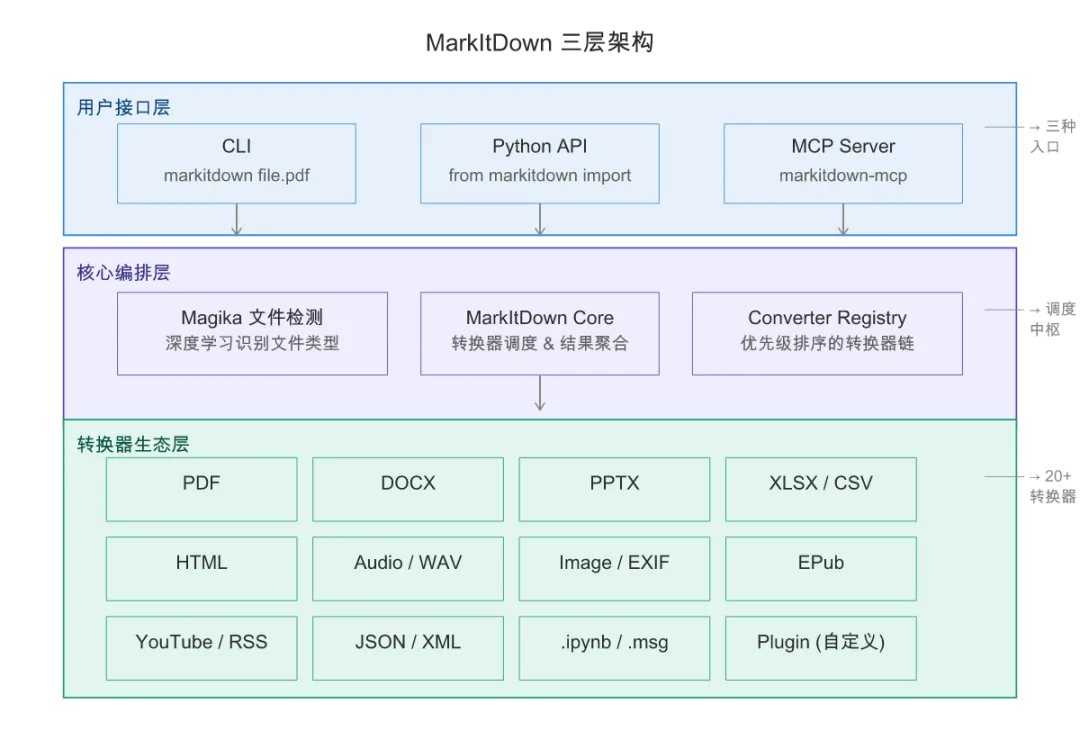
3.1 三层架构总览
MarkItDown 采用了经典的三层架构:
-
第一层:用户接口层 —— CLI 命令行、Python API、MCP Server 三种入口,覆盖从终端用户到 AI Agent 的完整场景 -
第二层:核心编排层 —— MarkItDown 主类,负责文件类型识别、转换器调度、结果聚合。这是整个系统的”大脑” -
第三层:转换器生态层 —— 每种文件格式对应一个独立转换器,通过优先级注册系统接入核心调度
MarkItDown 三层架构图:
3.2 核心设计模式:转换器链
MarkItDown 的核心是一个优先级转换器链。每个文件进入系统时,不会走”if-else”的分支判断,而是被所有已注册的转换器依次尝试。
具体流程如下:
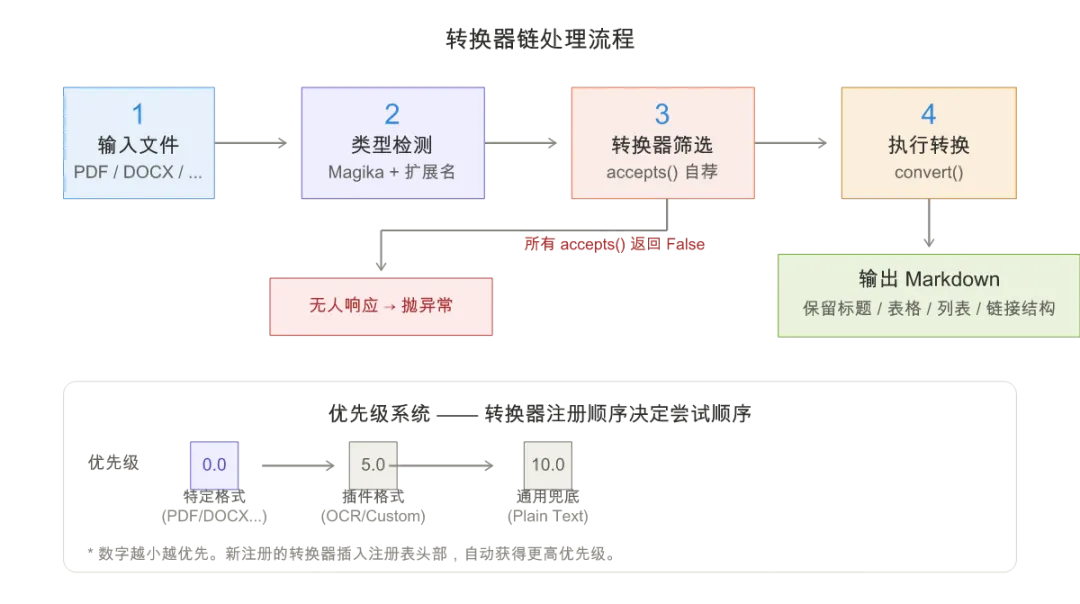
这里面有三个设计细节值得拆开看:
第一,优先级系统。 转换器的优先级决定了尝试顺序。特定格式的转换器(如 PDF、DOCX)优先级为 0.0,通用兜底转换器(如纯文本)优先级为 10.0。数字越小越先尝试。这意味着如果你写了一个”增强版 PDF 转换器”注册为 -1.0,它会自动取代内置的 PDF 转换器——无需修改源码。
第二,Magika 文件类型检测。 MarkItDown 没有用传统的”看扩展名”或”看 MIME type”的方式,而是用了 Google 开源的 Magika——一个基于深度学习的文件类型识别工具。它能从文件内容的二进制特征推断真实类型。一个被改名为 .txt 的 PDF 文件,Magika 依然能正确识别它是 PDF。
第三,防御性流位置管理。 转换器链的每个 accepts() 调用都不能改变文件流的读取位置——如果某个转换器偷看了前 100 字节但没有恢复指针,系统会在 assert 中断言失败。这个看似过度谨慎的设计,防止了转换器之间的互相干扰,在调试多格式混合处理时极其关键。
3.3 插件系统:按需扩展的生态
MarkItDown 的插件系统基于 Python 的 entry point 机制,设计非常克制——默认关闭,显式开启。
# 默认:不加载插件
md = MarkItDown()
# 显式开启:加载所有已安装插件
md = MarkItDown(enable_plugins=True)
这个设计决策背后是安全考量。MarkItDown 经常在服务端环境中处理用户上传的文件,第三方插件可能引入未知的代码执行风险。默认关闭意味着用户需要显式信任一个插件才会启用它。
目前最受关注的官方插件是 markitdown-ocr:它在 PDF、Word、PPT 转换过程中,自动检测嵌入的图片,通过 LLM Vision API 提取图片中的文字。不需要安装 Tesseract 之类的传统 OCR 引擎——你只需要配好 llm_client 就行。
这个插件揭示了一个重要思路:MarkItDown 本质上是一个编排框架。简单格式用内置解析器快速处理,复杂内容(图片里的文字、扫描件、模糊表格)交给 LLM,最终统一输出 Markdown。它不是要”自己解决所有问题”,而是”用最合适的工具解决每个子问题”。
3.4 可选依赖分组:别让 Docker 镜像爆炸
一个经常被忽视但实际影响巨大的设计是 可选依赖分组:
# 只装 PDF 支持,不装其它
pip install 'markitdown[pdf]'
# 只装 Office 文档
pip install 'markitdown[docx, pptx, xlsx]'
# 全都要
pip install 'markitdown[all]'
核心包只依赖 beautifulsoup4、requests、markdownify、magika 等 6 个轻量库。像 pdfminer.six、python-pptx、pandas、openpyxl 这些重型依赖,只有在你确实需要对应格式时才会引入。
对于 Docker 镜像和 Lambda 函数来说,这意味着你的部署包可以小几个数量级。一个只处理 CSV 和 JSON 的服务,根本不需要安装 PDF 相关的依赖链。
四、竞品对比:没有银弹,但有最优组合
光说 MarkItDown 好是不够的,必须放在真实竞争环境里看。
| 维度 | MarkItDown (微软) | Docling (IBM) | Marker (开源) | textract | Pandoc |
|---|---|---|---|---|---|
| 核心优势 | 速度+格式广 | 复杂布局精准 | 代码/图片处理优 | 格式最广 | 格式互转万能 |
| 最佳场景 | LLM数据管线、批量预处理 | 学术论文、金融报告 | 技术文档、代码PDF | 纯文本提取 | 排版级转换 |
| 速度 | ⚡ 最快 | 🐢 较慢 (AI分析) | 🚀 快 | ⚡ 快 | 🚀 快 |
| 输出质量 | 基础结构好 | 结构保真度最高 | 人类可读性最好 | 无结构 (纯文本) | 可排版 |
| 格式覆盖 | 20+ 种 (最广) | 聚焦文档类 | 聚焦PDF | 极广 | 极广 |
| 依赖复杂度 | 低 (按需安装) | 高 (需下载模型) | 中 | 低 | 高 (需安装) |
| Token优化 | ✅ 专为LLM设计 | ❌ 非核心目标 | ❌ 非核心目标 | ❌ 非核心目标 | ❌ 非核心目标 |
| MCP 集成 | ✅ 原生支持 | ❌ | ❌ | ❌ | ❌ |
关键结论:
MarkItDown 和 Docling/Marker 不是替代关系,而是互补关系。 在实际 RAG 项目中,成熟的方案是:
-
MarkItDown 做第一遍粗转换——速度快、覆盖广,把 80% 的内容搞定 -
对复杂文档(扫描 PDF、嵌套表格)用 Docling 做精排 -
用 LLM 做最终校验——检查结构是否完整、关键信息是否丢失
这个”粗转+精排+校验”的三段式管线,比用任何一个单独工具的效果都好。
五、实战:从零搭建 RAG 文档预处理管线
理论说完,我们来点实操。下面是用 MarkItDown 构建一个完整的 RAG 文档预处理管线。
5.1 基础用法:三行代码搞定
from markitdown import MarkItDown
md = MarkItDown()
result = md.convert("quarterly-report.xlsx")
print(result.text_content)
就这么简单。result.text_content 就是转换后的 Markdown 字符串,可以直接拼 LLM prompt 或送入向量化。
5.2 LLM 增强模式:让 GPT 帮你”看图说话”
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI()
md = MarkItDown(
llm_client=client,
llm_model="gpt-4o",
llm_prompt="请用中文详细描述这张图片的内容,包括图表数据"
)
result = md.convert("product-roadmap.pptx")
# PPT 中的图片会被 GPT-4o "翻译"成文字描述
5.3 批量处理管线
from markitdown import MarkItDown
from pathlib import Path
import json
def preprocess_documents(doc_dir: str, output_dir: str):
"""批量预处理文档,输出 Markdown 供 RAG 使用"""
md = MarkItDown()
doc_path = Path(doc_dir)
output_path = Path(output_dir)
output_path.mkdir(exist_ok=True)
results = []
for file in doc_path.iterdir():
if file.is_file():
try:
result = md.convert(str(file))
md_file = output_path / f"{file.stem}.md"
md_file.write_text(result.text_content, encoding="utf-8")
results.append({
"source": file.name,
"chars": len(result.text_content),
"status": "success"
})
except Exception as e:
results.append({"source": file.name, "status": "error", "error": str(e)})
report = output_path / "report.json"
report.write_text(json.dumps(results, indent=2, ensure_ascii=False))
success = sum(1 for r in results if r["status"] == "success")
print(f"转换完成: {success}/{len(results)} 成功")
# 一行调用
preprocess_documents("./raw_docs", "./markdown_output")
5.4 MCP 集成:让 AI 助手能”读”任何文件
MarkItDown 提供了官方的 MCP Server:
pip install markitdown-mcp
markitdown-mcp # STDIO 模式启动
在 Claude Desktop 的配置里加上:
{
"mcpServers": {
"markitdown": {
"command": "docker",
"args": [
"run", "--rm", "-i",
"-v", "/home/user/data:/workdir",
"mcr.microsoft.com/markitdown-mcp:latest"
]
}
}
}
配置完成后,你可以直接对 Claude 说:”读一下这个 PDF”,Claude 会通过 MCP 调用 MarkItDown 转换,然后基于转换后的 Markdown 进行分析。整个流程对用户完全透明。
5.5 完整 RAG 管线架构
把 MarkItDown 放在完整的 RAG 系统里看,它的位置就非常清晰了:
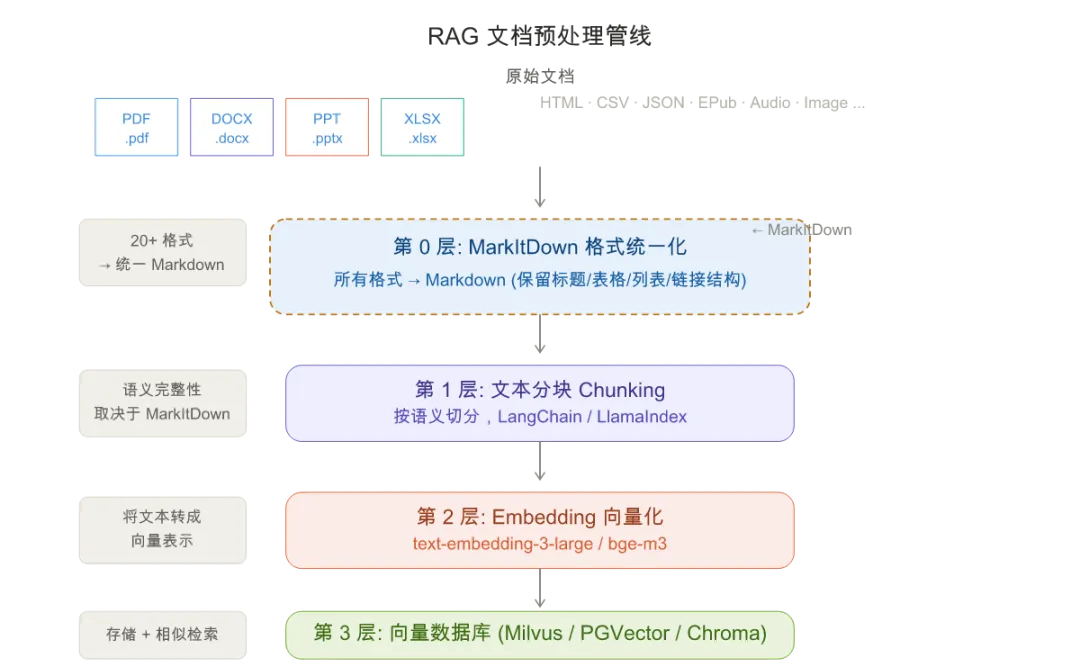
MarkItDown 在第 0 层做的事情,决定了后面三层能跑多好。Garbage in, garbage out 的道理在这里完全适用——如果输入的 Markdown 结构混乱、表格丢失、图片缺失,再好的 embedding 模型和检索算法都救不回来。
六、为什么 MarkItDown 能爆火?
147K Star 不是天上掉下来的。它之所以能火,是踩中了三个关键节点:
第一,时机绝佳。 MarkItDown 爆发的时间,正好是 LLM 应用从”demo 阶段”进入”生产阶段”的转折点。2024-2025 年,RAG 成为企业级 AI 应用的首选架构,知识库、智能客服、合同审查、合规检查——这些场景的前提条件是”文档能被 LLM 理解”。MarkItDown 恰好提供了从文档到 LLM 的”最后一公里”。
第二,微软的品牌势能。 AutoGen 团队出品 + MIT 协议 + GitHub 官方账号,这三重背书让开发者敢于在生产环境中依赖它。对比之前的同类工具(如 textract),大多是个人的业余项目,维护的持续性和代码质量参差不齐。
第三,架构的”刚刚好”哲学。 MarkItDown 没有试图做一个”完美”的文档转换器——它很清楚自己的边界。复杂排版的 PDF 转不好?没关系,接 Azure Document Intelligence 或者 LLM Vision。图片里的文字提取不到?没关系,有插件。它的核心只做一件事:尽可能简单、快速地把常见格式转成能用的 Markdown。然后用插件和外部服务解决长尾问题。
这种”核心精简 + 插件扩展”的设计哲学,和 Linux 内核、VSCode 的成功逻辑一脉相承。
七、给行业的启示
MarkItDown 的成功,至少给 AI 基础设施领域三个启示:
启示一:AI 时代的”无聊基础设施”价值被严重低估。 所有人都在追大模型、Agent、多模态,但真正决定 AI 应用落地质量的,往往是文档解析、数据清洗、格式转换这些”无聊”的环节。MarkItDown 147K Star 的背后,是无数开发者被 PDF 转换折磨后的投票。
启示二:”做得少”比”做得多”更难,也更有价值。 MarkItDown 故意不做高保真格式还原(那是人类阅读的需求),只做 LLM 需要的最小结构化输出。这种克制的产品定义,让它的代码量和复杂度远低于同类工具,反而获得了最大的采用率。
启示三:AI 工具链的标准化才刚刚开始。 MarkItDown 的 MCP Server 在 AI 开发者中的渗透率说明一件事:AI Agent 需要一个”统一文档入口”。今天的文档格式五花八门,明天的 AI 工具链要做的事情,就是用 MarkItDown 这样的工具把差异抹平,让上层应用只看到一个统一的接口。
总结
MarkItDown 不会解决所有文档转换问题,但它用最低的成本解决了 80% 的问题。在 AI 基础设施的版图上,它是那种”你平时感受不到它的存在,但没了它整个系统就会散架”的工具。
一句话核心观点:当所有人都在卷大模型的能力上限时,微软用一个 147K Star 的项目证明了——AI 落地的真正瓶颈,往往不在模型本身,而在模型面前那堵由 PDF 和 Excel 筑成的数据高墙。
如果你想在自己的 RAG 管线里试试 MarkItDown,记住一个简单的原则:用它做粗排,用 Docling 做精排,用 LLM 做最终校验。三者组合,是目前性价比最高的文档处理方案。
数据来源:GitHub (microsoft/markitdown),截至 2026 年 6 月 24 日。