夜雨聆风
夜雨聆风





OpenClaw 定时任务系统的设计理念
Agent 已经有了心跳轮询——每 30 分钟自动拉起来巡检一次,看看有没有事情需要处理。这已经是一种”自主工作”了。
那 cron 定时任务系统在心跳之上还要解决什么问题?
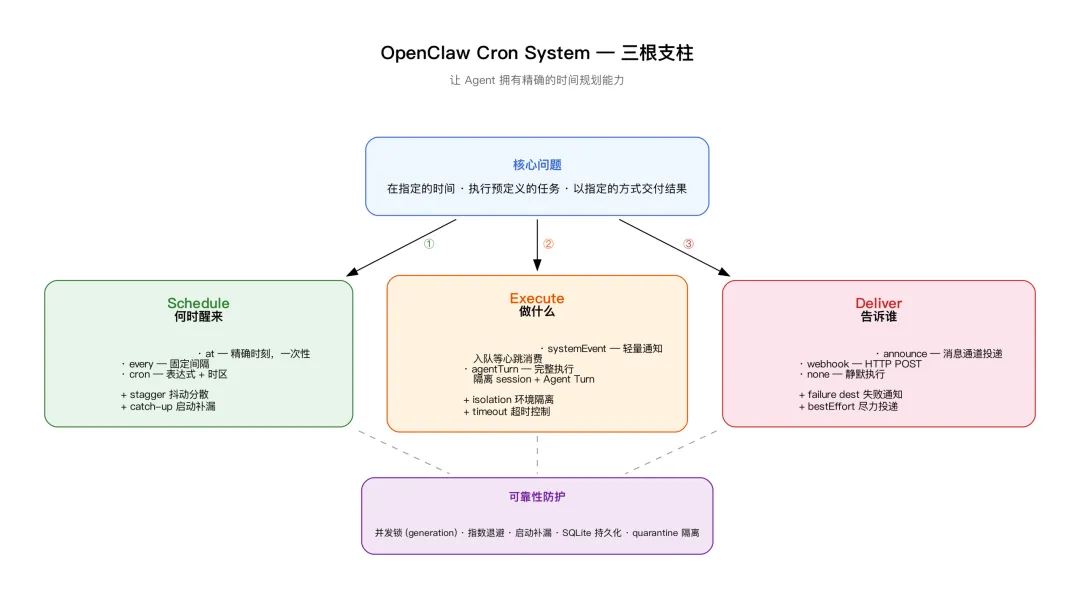
怎么让 Agent 拥有精确的时间规划能力,即在指定的时间、执行预定义的任务、以指定的方式交付结果。
心跳是”无目标巡检”,固定间隔拉起,Agent 自己去判断借鉴。Cron 是”有明确意图的定时执行”——用户或 Agent 主动创建,精确到”什么时间做什么事、结果告诉谁”。
要有时间规划能力,那么需要解决三个子问题:
-
1. 什么时候醒来? — 精确的时间计划 -
2. 醒来做什么? — 预定义的任务内容 -
3. 做完怎么告诉你? — 明确的结果投递
下面来看OpenClaw 的 cron 系统是怎么设计的。
问题 1:什么时候醒来?
从最简单的方案开始
用户每创建一个定时任务,系统就生成一个 job(”每天 9 点查邮件”是一个 job,”20 分钟后提醒我”也是一个 job)。最直觉的调度方式:每个 job 配一个 setTimeout,到点回调执行。100 个 job 就有 100 个 timer。
为什么不行?首先是动态管理复杂——用户随时增删 job,每次都要取消旧 timer、创建新的,边界条件满地。其次是并发不可控——100 个 timer 独立回调,可能同一瞬间触发 10 个 job,压垮模型 API。最后是重启丢失——进程重启后所有内存里的 timer 消失,错过的 job 就丢失了。
OpenClaw 设计:单 timer 轮询
只维护一个 setTimeout
→ 指向"下一个最近要触发的 job 的时间"
→ 到期后遍历所有 due jobs
→ 执行完重新计算下一个最近时间
→ 重新 arm(“武装”定时器——设定一个新的 setTimeout 让它开始倒计时,因为 setTimeout 是一次性的,触发后就消耗了)为什么是单 timer?新增/删除 job 只需要重新计算”下一个最近时间”并重设一个 timer,不需要管理 N 个 timer 的生命周期。执行时串行(或受控并发),不会突然爆发。重启后从 SQLite 加载所有 job,立即算出哪些错过了,再去补执行。
MAX_TIMER_DELAY_MS = 60 秒——假设现在系统里只有一个 job,明天早上 9 点触发。按理说 timer 可以 sleep 十几个小时。但如果 timer 真的睡了 10 小时,中间你对 Agent 说“20 秒后提醒我”,Agent 创建了一个新 job——这个 job 20 秒后就该触发,但 timer 还在沉睡,不会醒来检查。所以设了一个上限:不管下个 job 多远,timer 最多睡 60 秒就醒来重新扫一遍所有 job。新 job 最多被晚发现 60 秒。
MIN_REFIRE_GAP_MS = 2 秒——这解决的是相反方向的问题:timer 醒得太快。正常流程是 job 执行完→算下一次触发时间→设 timer 等到那个时间。但 cron 表达式解析库(croner)在某些时区 + 日期组合下有个 bug:nextRun() 返回的”下一次时间”实际上就是当前时间(或者极近的过去时间)。这导致:执行完→算下次→发现”下次”就是现在→立即再执行→执行完→算下次→还是现在→无限循环,CPU 100%。这就是 issue #17821 报告的问题。修复方式是加一个最小间隔:同一个 job 两次触发之间至少隔 2 秒。即使 nextRun() 算出来就是现在,也强制等 2 秒再触发,打断 spin-loop。
三种调度模式
openclaw把对时间的表达定义为三种。”20 分钟后提醒我”——精确时刻,一次性,对应 at 模式。”每 30 分钟检查一次”——固定间隔,基于 anchor 对齐,对应 every 模式。”每天早上 9 点”——cron 表达式 + 时区,对应 cron 模式。
三种表达方式差异巨大,但调度器只需要一个信息:下一次该触发是什么时候。所以它们在计算层统一成一个函数:computeNextRunAtMs(schedule, nowMs) → number | undefined。调度器不关心你用的哪种表达方式,它只看这个函数返回的结果。
问题 2:醒来做什么?
两条路径
Agent 被”叫醒”后要做事。做什么事,决定了用什么方式叫醒它。
路径一:systemEvent(轻量通知)。 Job 触发后,一行文本写入消息队列,完事。等心跳消费时 Agent 看到,自主判断是否行动。适用场景是提醒类——”该查邮件了””会议快开始了”。
路径二:agentTurn(完整执行)。 Job 触发后,创建独立 session,启动完整的 Agent Turn,结果投递给你。适用场景是需要 Agent 真正去”做事”的任务——查邮件、整理知识库、监控竞品。
为什么路径二需要隔离 session?
如果在主会话里执行定时任务,会出三个问题。上下文污染——一个定时任务灌了 10000 token 的工具输出,你下次聊天时上下文被占满。状态竞争——你正在和 Agent 对话,突然定时任务插入一轮执行,打断对话流。无法并发——主会话同一时间只能有一个活跃推理。
所以隔离是必然的——每个定时任务开自己的 session,跑完就销毁,不污染主对话。
问题 3:做完怎么告诉你?
Openclaw设计了三种方式:
三种投递方式对应三种场景。announce——通过消息通道(Telegram/Discord/WhatsApp)发给你,大多数场景用这个。webhook——POST 到一个 URL,适合集成到外部系统。none——不投递,适合静默任务(整理文件等,做完不需要通知 )。
投递还有为投递失败设计的附加策略,bestEffort 意味着投递失败时不重试、不阻塞后续任务。failureDestination 让正常结果发主通道、失败单独发到另一个通道(比如运维群)。threadId 让投递进入正确的话题,不污染主聊天。
如果执行出了问题怎么办?
并发防护
同一个 job 不能同时跑两次。active-jobs.ts 用全局 Map 追踪正在执行的 job:
typeCronActiveJobMarker = {
jobId: string;
generation: number; // Gateway 重启时自增
token: number; // 唯一标识本次执行
};generation 设计中,当Gateway 重启时 generation 自增,旧 generation 的 marker 自动失效,这样重启前卡死的 job 不会阻塞重启后的调度。
错误处理
不是所有错误都值得重试。网络超时、503、rate limit 属于 retryable,走指数退避重试(30s → 60s → 5min → 15min → 60min)。认证失败、格式错误属于 permanent,不重试,直接标记失败。
启动补漏(Catch-up)
进程挂了 2 小时重启,期间错过了 10 个 job。全部立即补执行会压垮系统。所以有渐进策略:最多补执行 5 个(maxMissedJobsPerRestart),补执行间隔 5 秒(missedJobStaggerMs),Agent Turn 类型的 job 额外延迟 2 分钟再补(等模型 API 稳定)。
持久化策略
Job 定义存在 SQLite——不能丢,重启后要恢复调度。执行历史存在 SQLite——需要查询和展示。运行状态(lastRun、连续错误次数)也在 SQLite——退避计算需要。异常 job 写到 quarantine sidecar JSON——坏数据不能阻塞整个系统启动。
设计理念总结
从三个问题出发,可以看出Openclaw的设计理念: