 夜雨聆风
夜雨聆风





Hermes vs OpenClaw 全方位对比 + Harness Engineering 实现深度验证
Hermes vs OpenClaw 全方位对比 + Harness Engineering 实现深度验证
这是系列最后一篇,做两件事:把 Hermes 和 OpenClaw 放在一起比清楚,然后验证 Hermes 在多大程度上实现了 Harness Engineering 的工程范式。
先说结论:Hermes 和 OpenClaw 不是直接竞品。它们解决的是不同层次的问题——OpenClaw 是一个多平台 Agent 网关框架,Hermes 是一个自进化 Agent 运行时。选哪个取决于你需要的是”把 Agent 能力接进各种平台”还是”让 Agent 在使用中自动变强”。
Part 1:Hermes vs OpenClaw
OpenClaw 的核心设计是一个插件化的消息网关——你通过插件系统把 Agent 能力接入 Telegram、Discord、Slack 等平台,Agent 行为本身由你配置的后端模型和 prompt 决定。OpenClaw 的价值在于连接:它让 Agent 无处不在。
Hermes 也做了消息网关,但它不会说自己的核心价值是”连接”。Hermes 的核心价值是学习——消息网关只是让 Agent 能随时随地接收信息的一种手段。
|
|
|
|
|---|---|---|
| 核心定位 |
|
|
| 记忆系统 |
|
|
| Skills |
|
|
| 学习能力 |
|
|
| 模型绑定 |
|
|
| 多平台 |
|
|
| 部署方式 |
|
|
| 定时任务 |
|
|
| 子代理 |
|
|
| 规模化能力 |
|
|
| 许可证 |
|
|
你该选哪个
如果你需要一个”把 AI Agent 接入所有聊天平台”的网关框架,并且各个平台的 Agent 行为可以统一配置管理——OpenClaw 更直接。如果你想让 Agent 在使用过程中持续学习你的偏好、自动积累经验、越用越懂你——Hermes 目前在这个方向上是唯一的开源选择。
两者不冲突。你可以用 OpenClaw 做网关层(如果它的插件系统更符合你的需求),背后接 Hermes 做 Agent 运行时。只是目前没有人做这个集成——技术上可行,但需要自己写适配层。
Part 2:Harness Engineering 验证
Harness Engineering 是一套让 AI Agent 行为”可控、可验证、可改进”的工程范式,核心三个支柱:约束层(Constraining)、验证层(Verifying)、反馈层(Feedback Loop)。我用这套框架审视 Hermes 的完整架构,看它实现了多少、缺了什么。
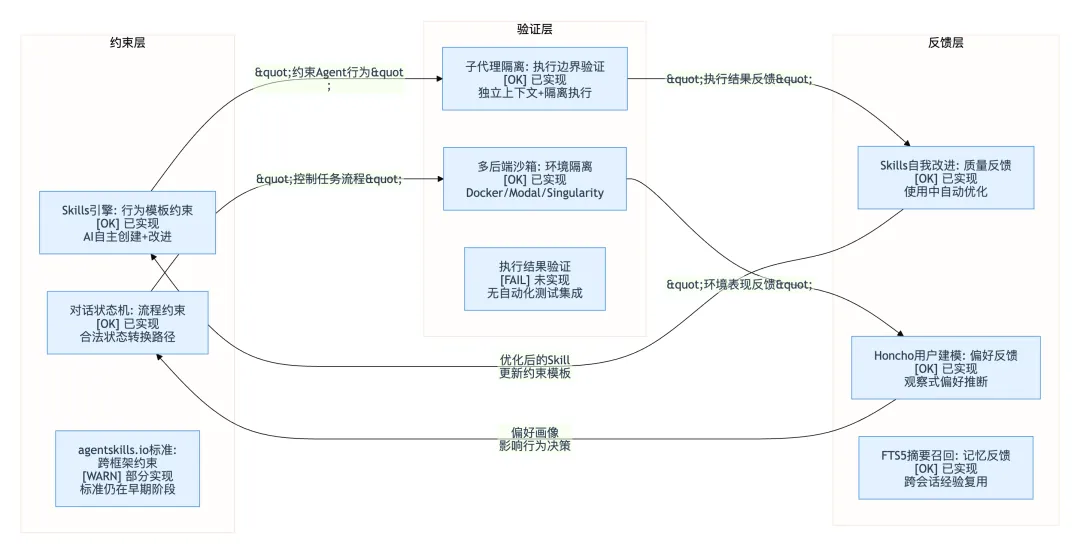
约束层的评估
Hermes 在约束层的实现是完整的。Skills 引擎提供了行为模板约束(Agent 按 Skill 定义的流程执行,不能跳过关键步骤),对话状态机提供了流程约束(任务只能在合法状态之间转换)。两者的关键差异化在于约束是自动维护的——Skills 由 Agent 在实战中自行提炼和改进,不是人工一次性配置。
约束层有一个缺口:agentskills.io 标准仍在早期阶段。现在 Hermes 的 Skills 理论上是跨框架可移植的,但实际能使用 agentskills.io 标准的框架还很少。这个标准的生态成熟度决定了 Hermes Skills 的跨框架可迁移性。
验证层的评估
验证层有优势也有明显缺失。子代理隔离是 Hermes 验证层最强的能力——每个子代理独立上下文、独立执行,一个代理的偏差不污染另一个。多后端沙箱提供了环境级隔离(Docker/Modal/Singularity),代码在明确定义的沙箱中执行。
验证层的缺失:没有自动化的执行结果验证机制。Hermes 可以生成代码、执行代码,但没有内置的测试集成来验证”生成的代码是否通过了项目已有的测试套件”。Claude Code 在这方面走得更前——它可以在生成代码后自动运行 go test 或 pytest,验证代码的正确性。Hermes 缺少这个”验证闭环”的最后一步。你可以在 Hermes 里手动让它运行测试,但它不会在每次代码生成后自动做这件事。
反馈层的评估
反馈层是 Hermes 最强的部分——也是它和所有其他 Agent 框架拉开差距的地方。三条反馈回路都在正常运行:
-
Skills 自我改进回路:Skill 使用中的成功率、被纠正频率驱动自动优化 -
Honcho 用户建模回路:你的纠正行为转化为偏好信号,影响未来 Agent 的决策策略 -
FTS5 摘要召回回路:历史对话的检索结果持续影响上下文组装质量
三条回路都不需要人工介入,形成了一个自动运转的”使用→反馈→改进→更准”的飞轮。
综合评估
|
|
|
|
|
|---|---|---|---|
| 约束层 |
|
|
|
| 验证层 |
|
|
|
| 反馈层 |
|
|
|
| 综合评分 | 23/30 |
|
Hermes 在 Harness Engineering 的实现上,反馈层的成熟度远超其他框架,验证层的自动化测试缺失是最需要补齐的短板,约束层的自立维护设计解决了”Skills 写完就不更新”的系统性熵增问题。
如果 Hermes 在未来的版本中加入”代码生成后自动运行项目测试套件、测试通过才提交”的能力,它的 Harness Engineering 实现会接近完整——从约束到执行到验证到反馈形成完整闭环。
系列到此六篇写完。从架构全景开始,经过安装配置、对话引擎、记忆系统、多平台部署,到最后的竞品对比和工程范式验证。Hermes 不是我见过的最成熟的 AI Agent 框架——OpenClaw 的平台网关更完善,Claude Code 的推理深度更强——但它是我见过的唯一一个把”Agent 应该在使用中自动变强”作为核心设计前提的框架。这一点值得所有做 AI Agent 工程的人关注。