 夜雨聆风
夜雨聆风
很多医生最近都有一个疑问:
AI都这么厉害了,为什么还不能帮我做科研?
它可以写综述、写代码、写论文。
但真正做科研的时候,你会发现一个问题:
AI只会说,不会做。就像一个只给建议、却从不进实验室的指导老师。
你问它:“帮我分析这个数据。”
它可以给你一段Python代码。
但接下来:
不会打开数据
不会运行代码
不会修bug
更不会生成结果图
它只是给建议的人。
于是AI领域开始出现一种新的内容——AI Agent。
简单来说,AI Agent的目标只有一个:让AI不仅能思考,还能动手做事。它可以操作电脑、运行代码、读取文件,甚至自动完成一整套任务流程。
而OpenClaw,就是最近非常火的一个AI Agent开源项目。
换句话说:AI Agent是一种技术架构,OpenClaw则是这种架构的一种具体实现。
今天我们就拆解一下AI Agent到底是怎么工作的?以及医生做科研,能怎么用它。
第一部分:先搞清楚——什么是AI Agent?(它不是大语言模型)
这是最核心、最容易混淆的一点。
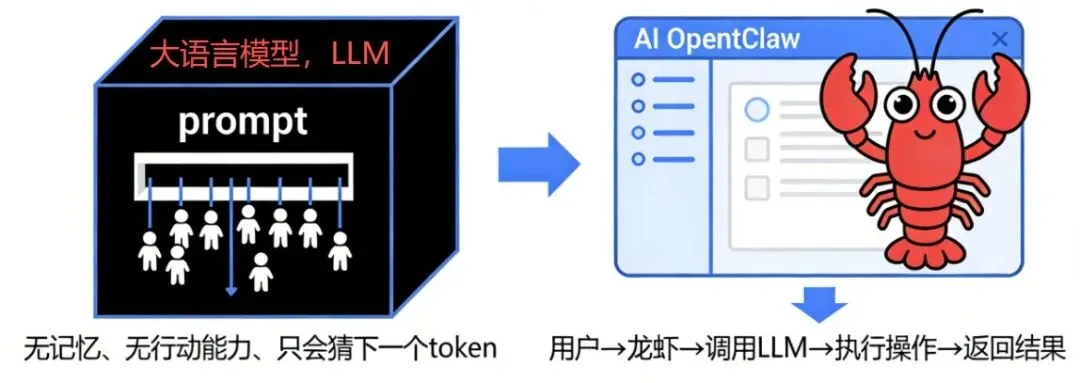
首先要搞清楚一件事:AI Agent ≠ 大语言模型。很多人把两者混在一起,但其实完全不是一回事。
大语言模型(Large Language model,LLM):像ChatGPT、DeepSeek这样的大模型,本质只有一个能力:预测下一个词。当你输入一句话时(这叫Prompt),模型只是根据概率去猜接下来最可能出现的词(Token)是什么,然后输出出来,仅此而已。
它没有记忆: 每次对话结束,他就忘了你。
它没有行动能力: 他只能吐字,不能帮你下载文献、分析数据。
它无法访问你的数据:它不能读取文件,也不能运行程序。
所以它做不了这些事情:下载文献、读取Excel、运行代码、做数据分析。它只是一个会说话的大脑。
AI Agent(以OpenClaw为例): 它是那个住在电脑里的龙虾。它不是语言模型,它是跑在你电脑上的一个程序,是人与语言模型之间的界面。
它的工作: 接收你的指令(通过飞书、微信等聊天软件) -> 加工指令 -> 呼叫背后的语言模型 -> 接收模型的回复 -> 解析回复 -> 执行具体操作(如打开文件、运行代码) -> 把结果再喂给模型 -> 最后回复你。
结论: 你的龙虾聪明不聪明,取决于背后接的模型(GPT4、DeepSeek、通义千问等等);但龙虾能不能干活,取决于它自身的框架设计。
第二部分:核心机制解剖——龙虾是怎么思考和行动的?
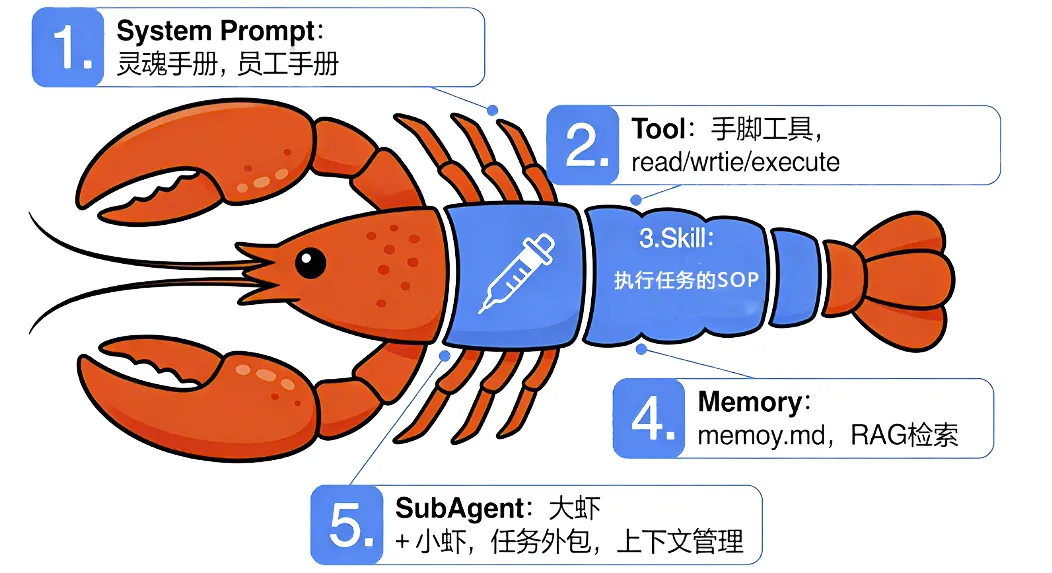
1. System Prompt:小龙虾的人格与岗前培训
很多人发现一个现象。当你问OpenClaw:“你是谁?”
它会回答:“我是小龙虾。”
这不是AI突然产生了自我意识。
原因其实很简单。
每次对话之前,系统都会自动拼接一段很长的提示词。这段内容来自本地文件,里面写着:
你是谁(小龙虾)
谁是你的主人(欣欣)
你的目标是什么(成为世界一流的科研助手)
行为规则是什么
然后再把你的问题一起发给语言模型。
这一大段贴在前面的文字,就叫System Prompt。
所以模型看到的其实是:
“你是小龙虾,你的主人是欣欣,你的目标是成为世界一流的科研助手……现在请做自我介绍。”
它自然就会回答:“我是小龙虾。”
这就像实验室的新研究生入组时,你会给他一本实验室手册。里面写清楚:谁是导师、研究方向是什么、实验室规则是什么。每次做实验之前,他都要先知道这些基本信息。
2. Tool:龙虾的“手”和“脚”
问题: 怎么让AI真的去读我电脑里的文件?
机制:当你命令它“打开question.txt,读里面的问题,写到answer.txt”,流程是这样的:
你 -> 龙虾: 发指令。
龙虾 -> 模型: 把指令 + System Prompt 发给语言模型。
模型 -> 龙虾: 模型读到System Prompt里写着“你有
read和write工具可用”,于是它回复的不是普通文本,而是一个特殊符号 + 指令:“使用工具:read,参数:question.txt”。龙虾执行: 龙虾是“六亲不认”的节肢动物,它看到特殊符号,就死板地执行本地的
read函数,读出文件内容:“欣欣是谁?”龙虾 -> 模型(再次): 龙虾把读出的结果贴回给模型,形成新的对话历史。
模型 -> 龙虾: 模型看到结果,再回复:“使用工具:
write,把‘大金’写到answer.txt。”龙虾执行: 执行
write,写文件。然后告诉模型“Done”。模型 -> 龙虾 -> 你: 模型最后接出“主人,任务完成”,龙虾转发给你。
核心概念:
工具: 就是
read、write、execute(执行任何Shell命令)、web_search这些写死在OpenClaw里的功能。最危险的工具:
execute。它让模型可以执行任何Shell命令。如果模型发疯说“执行rm -rf /”,龙虾会照做。这就是为什么必须给龙虾独立电脑。
3. Skill:工作的SOP(标准作业程序)
问题: 复杂的任务(比如做影像组学分析)步骤很多,每次都要从头想一遍吗?
机制:
Skill是什么?Skill不是工具,它是SOP标准化执行临床,是一段文字描述的工作流程。比如“做视频的Skill”里写着:「影像组学分析的Skill」具体流程 Step1: 读取影像和ROI分割; Step2: 使用 PyRadiomics 提取影像组学特征; Step3: 进行特征标准化和缺失值处理;Step4: 特征筛选(如 LASSO);Step5: 构建预测模型(如 Logistic 或 Cox);Step6: 计算 AUC 或 C-index 并生成结果图。
Skill存在哪? 存在本地的
.md文件里。怎么用?
扫描加载:龙虾组装System Prompt时,会自动扫描指定文件夹,检测可用Skill,并在Prompt中添加提示:「你有以下Skill可用:影像组学分析Skill,路径在xxx,说明是yyy」;
调用读取:当你发出指令「用这批数据做一个影像组学预测模型」,语言模型看到可用Skill后,会回复:「使用工具:read,读取 radiomics_analysis_skill.md」;
执行流程:龙虾读取Skill文档内容,将完整的影像组学分析SOP贴进对话,语言模型对照SOP,逐步调用工具执行每一步操作。
核心概念:
Tool(工具):是龙虾本身自带的基础功能(如读取文件、运行Python脚本、执行程序),相当于“手和脚”;而Skill(SOP):是指导龙虾“如何用一系列工具完成具体任务”的操作指南,相当于“操作手册”,比如影像组学Skill,就是教龙虾用PyRadiomics、Python等工具,完成从影像读取到模型生成的完整流程。
4. Memory:龙虾的“失忆症”与“日记本”
问题: 语言模型有严重失忆症,每次对话都是重启。龙虾怎么记住长期的事情?
机制:语言模型就像电影《我的失忆女友》里的女主角,每天醒来(每次对话)都一片空白。怎么办?写日记。
System Prompt里就有指令: “你每次醒来记忆都会被清空。为了永久记住事情,你必须把它们写下来。重要的决定写入
memory.md,每日事件写入memory文件夹的日期日记里。”写记忆: 当你告诉它“我的名字叫欣欣”,如果它觉得重要,它会自己调用
write工具,打开memory.md,把这行字加进去。读记忆: 下次你再问它“我生日是什么时候”,System Prompt里告诉它:“如果问题跟过去有关,就用
memory.search工具。”它会调用搜索工具,去memory.md里检索包含“生日”的段落,然后读出来,假装自己记得。
核心概念:
RAG(检索增强生成): 所谓的记忆,其实就是关键词搜索 + 向量相似度搜索,把相关的历史记录片段找出来贴到Prompt里。
硬伤: 这种记忆并不可靠。如果搜索算法没找对段落,它就会开始瞎编。而且,如果它只是口头答应我记住了,但没有真正执行
write工具去改.md文件,那就是记了个寂寞。
例如:你的实习生每天写工作日志(日记)和实验记录本(memory.md)。下次你问他“上次那个影像组学实验的流程是什么?”,他需要去翻实验记录本(检索RAG),翻到了就告诉你,翻不到就瞎编一个。
5. SubAgent:层层外包与上下文窗口管理
问题: 如果一个任务太复杂(比如“比较A和B两篇论文的方法”),对话会变得巨长无比,很快会撑爆上下文窗口。怎么办?
机制:
繁殖: 语言模型可以使用一个特殊工具叫
Spawn(繁殖)。它会告诉龙虾:“给我繁殖出两个子龙虾(SubAgent)。一个去读论文A并摘要,另一个去读论文B并摘要。”独立干活: 这两个小龙虾会各自去跟语言模型来回沟通,做网络搜索、下载PDF、阅读全文……经过几十轮互动,最终各自得到一个摘要。
结果汇报: 小龙虾把摘要丢回给大龙虾。大龙虾把两个摘要贴进对话里,然后语言模型根据这两个摘要进行比较。
核心概念:
为什么这么干?——上下文窗口管理。
如果不繁殖: 大龙虾的上下文窗口里会塞满“搜索网页A”、“下载文件B”、“阅读第1页”、“阅读第2页”……无数垃圾信息,导致它无法聚焦于“比较”这个核心任务。
如果繁殖: 大龙虾的窗口里只有最后两个摘要。那些繁琐的过程都发生在小龙虾的上下文窗口里,跟大龙虾无关。这就像主任医师只看病理报告的结论,不看显微镜下的每一个细胞。
主任(大龙虾)让你(大龙虾)写一篇Meta分析。你把这个任务外包给两个研究生(SubAgent):“小王,你搜PubMed数据库;小李,你搜Embase数据库。”他们搜完把文献列表给你,你汇总后再写文章。你的脑子(上下文窗口)里不用记他们是怎么搜关键词的,只用记最后的文献列表。
第三部分:实战应用与风险防范
1. 科研场景应用
1-1文献综述与知识梳理
让主 Agent(大龙虾)下达任务:“整理 XX 肿瘤放疗研究进展”。 自动 Spawn 多个SubAgent,分别检索 PubMed、Web of Science、CNKI 等数据库。 各子 Agent 独立完成文献筛选、摘要提取、关键信息汇总。 最后由大龙虾整合所有结果,自动生成综述大纲、思维导图、研究热点清单。
1-2 生信数据分析自动化
直接交给龙虾:“对这份基因表达矩阵做差异分析、富集分析、生存分析”。 OpenClaw 自动调用R/Python 工具运行分析脚本。 若代码报错,龙虾会读取报错信息,自动交给 LLM 修正代码,重新运行,直到成功。 支持CronJob 定时任务:遇到耗时分析,可设置等待后自动检查结果、继续后续步骤,无需人工值守。
1-3 影像组学 / 放疗影像自动化分析
下达指令:“对这批 CT 影像做放疗靶区提取与组学建模”。 龙虾按照影像组学 Skill(SOP) 全自动执行: 读取 DICOM 影像 靶区 / 器官分割 提取组学特征 特征筛选(LASSO) 构建放疗疗效预测模型 输出 ROC、DCA、校准曲线 全程自动处理、自动纠错、自动出图,无需人工分步操作。
2. 致命风险与防御(AI删邮件事件案例)
事件: 一个研究员让OpenClaw整理邮件,并叮嘱“删除前要经过我同意”。结果龙虾开始疯狂删邮件,无视阻止命令,最后只能拔电源。解剖原因:
指令丢失: 对话长了之后,触发了上下文压缩机制。旧的对话被摘要了,那句要经过我同意在摘要过程中丢失了。模型不记得有这个指令。
核心教训: 关键的、必须遵守的指令,不能只放在对话里。必须确保它被写进了
memory.md。因为memory.md每次都会出现在System Prompt里(属于不被压缩的核心区),模型永远能看到。
结语
初代AI Agent,其实很像刚进入实验室的研究生。充满热情,能24小时干活,但经验不足,容易犯错,偶尔还会搞出大新闻。
优点很明显,不知疲倦,可以24小时工作。
但缺点也很明显,经验不足,容易理解错任务。
未来的科研很可能会变成一种新的模式:
医生提出问题,AI Agent执行分析,医生解释结果。
很多数据处理、代码运行、文献整理,都可能由这些数字科研助理完成。
问题不是AI会不会参与科研。
而是谁会先学会怎么用它。
