夜雨聆风
夜雨聆风在OpenClaw的热潮里,你需要的其实是Codex
老实说,我最近有点烦OpenClaw的推送。
不是因为它不好用。是因为每隔三天就有人发来链接问我"你试了吗""XX学界要变天了"——然后我点进去,发现他们展示的那些案例,用Codex早就能做。
今天这期推文我打算给大家演示一个案例,让大家清楚一件事:对于我们这个圈子的日常分析需求,现有工具是否已经超乎想象了?
Prompt只有一句话
我打开Codex,输入:
从GBIF下载近十年中国境内朱鹮(Nipponia nippon)的occurrence记录,画出分布地图,并分析哪些省份记录最多、近年种群是否在扩散。
零数据准备。零代码。计时开始。
13分钟后,工作区里出现了:
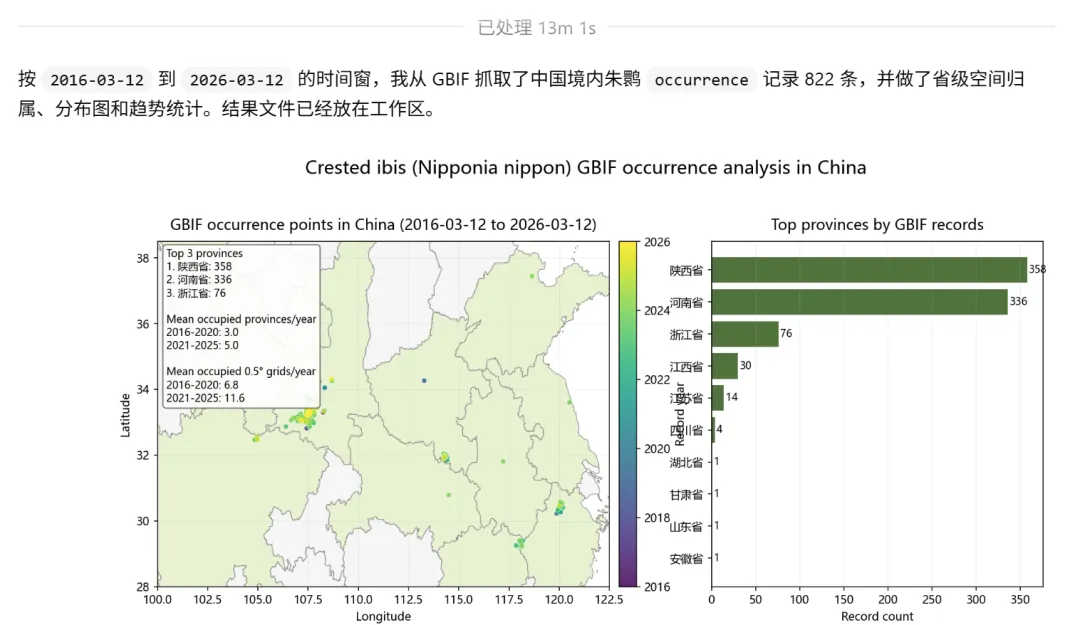
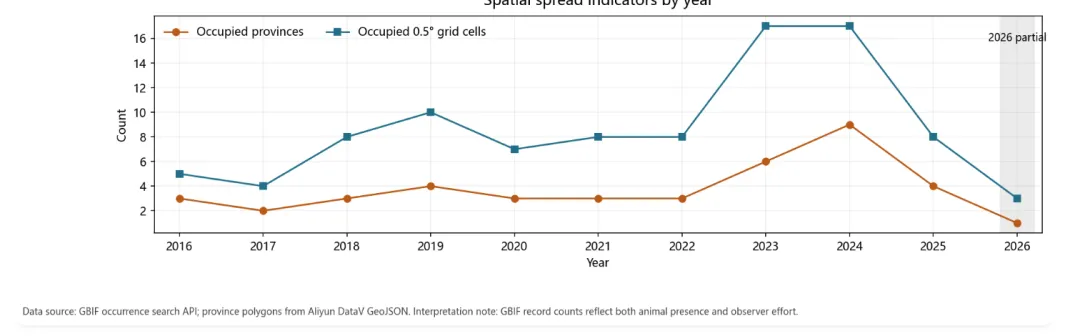
原始occurrence记录 CSV(822条,经GBIF API实时拉取,speciesKey: 2480810) 省份汇总表、年度汇总表 一张带省级polygon的分布点图,点色按年份渐变 逐年空间扩散指标图(occupied provinces + occupied 0.5° grid cells双轴) 可复现的Python脚本(+355行) 一段附有方法论注释的文字结论

然后它在最后问我要不要顺手出一张发表风格的图。
我盯着屏幕想了一会儿。这个流程我自己走一遍,从pygbif到geopandas到matplotlib,保守估计半天。
结果本身值得说两句
朱鹮的空间核心毫无悬念:陕西(358条)、河南(336条),这是人工繁育和野化放归的主战场。
但扩散信号是真实的。两个指标都指向同一个方向:
年均占据省份数:2016–2020均值3.0 → 2021–2025均值5.0 年均占据0.5°网格数:6.8 → 11.6 首次出现新省份的节点:2019年(4省)、2023年(6省)、2024年(10省)
江西婺源和江苏盐城出现了重复记录,不是偶发点,扩散趋势在空间上是有结构的。
值得一提的是,Codex在结论里主动加了这句话:
GBIF record counts reflect both animal presence and observer effort. 记录增加不能直接等同于种群扩张。
没有人要求它写这个。它自己判断这里需要一个方法论保留。这个细节让我觉得,它理解的不只是"帮你跑代码",而是"帮你做分析"。
OpenClaw解决的是另一个问题
我想说清楚,我不是在说OpenClaw没用。
OpenClaw的核心是Agent架构——它能感知本地文件系统、跨工具调用、维持跨会话的工作上下文、在你修改需求时自动更新整条pipeline。对于那种需要同时协调ENVI/GEE/本地数据库/Word输出的重型工作流,它解决的是工具之间的摩擦,这个痛点是真实的。
但我观察到的是,很多被OpenClaw"震撼到"的同行,展示的案例其实是:输入一个问题,得到一张图,加一段结论。
这件事,Codex现在就能做。
真正的迁移成本在哪
我认为现阶段对我们这个群体来说,学习一套新Agent框架的边际收益,低于把prompt工程这件事做扎实。
朱鹮这个案例能跑出来,不是因为工具多强,是因为那句prompt写得足够清楚——物种名、数据源、地理范围、时间窗口、分析目标,每个要素都在。把问题问清楚,工具自然会处理剩下的。
这个能力,说到底是我们本来就应该有的:在提笔写Methods之前,先想清楚Research Question。
追工具没问题,但先把手边的用够。
我的Codex还有很多没探索到的角落。OpenClaw等它真的解决了我现在解决不了的问题,我再去学。
相关问题的讨论,我们在AI for Science交流群里经常进行。如果你对这个话题感兴趣,可以联系我进群: