 夜雨聆风
夜雨聆风引言:那个灵魂问题
过去一个月,你用 OpenClaw 做了什么真正有意义的事?
是自动化处理了一百份报表,还是仅仅让它帮你打开了一次浏览器?是在生产环境省下了三天工作量,还是配置环境就消耗了三个晚上?
如果答不上来,你已经支付了“信仰税”——时间、焦虑、和技术判断力的透支。
GitHub 上 Star 182k 的 AutoGPT、体积小到 98% 的 Nanobot,功能与 OpenClaw 同质甚至更强。OpenClaw 没有技术壁垒,壁垒在心理操控。它跑通的不是技术范式,而是“门槛+焦虑+开源佃农”的三位一体收割模型。
点击以上链接,收听AI播客
一、祛魅:GitHub 上躺着几百个“OpenClaw”

同类项目全景:
AutoGPT(182k stars):2023 年即实现自主任务分解、工具调用,代码更成熟。
Browser-use:基于 Playwright 的浏览器自动化,OpenClaw 的核心依赖,单独使用无需本地部署。
Nanobot:体积比 OpenClaw 小 98%,同样支持多模型 API 切换,MIT 协议开源。
LobsterAI(网易)、CountBot(阿里):国产替代方案,支持渐进式安全。
技术本质:基于现有 LLM API 的流程编排层(截图+解析+API 调用),核心代码
你熬夜配置 Node.js、折腾 Docker、解决依赖冲突,是在为一串随处可见的开源代码支付“苦难修行税”。

二、收割流水线:三级跳榨取模型


第一关:门槛筛选(沉没成本陷阱)
复杂的配置方案、AI提示词、SKILL使用的功底、设备的依赖性 ——这不是技术限制,是心理筛选。目的是筛选出愿意投入沉没成本的“虔诚信徒”,排除“随便试试”的散户。
当你折腾三小时终于跑通,产生“必须证明这值得”的心理,自动转化为产品传教士——主动写教程、怼质疑者、维护社区秩序。
第二关:焦虑绑架(双向恐吓)
本地派:软件本就漏洞百出,安全隐患极大 →不怀好意者早就部署了各种黑客行为(读取所有文件、截屏、执行任意代码)。
云端派:“本地配置太复杂”→诱导你使用第三方托管(QClaw、ArkClaw),上传数据到不明服务器。
悖论:无论选哪边,你都在交出数据主权,只是换了个姿势被收割。
第三关:开源佃农制(数据榨取)
Skills 工具化:用户编写的 SKILL.md 被云厂商直接集成,零成本获取生态。
记忆锁定:USER.md 记录行为偏好、业务逻辑,形成无法导出的数字记忆资产——迁移成本是“记忆剥离”的心理痛苦。
隐形 RLHF:你纠正错误、终止失控任务、修改 Prompt 的过程,实为为模型提供高质量的强化学习标注。
全景监控:本地 Agent 的截屏分析、文件读取、操作路径,比传统 App 更赤裸的行为数据采集。

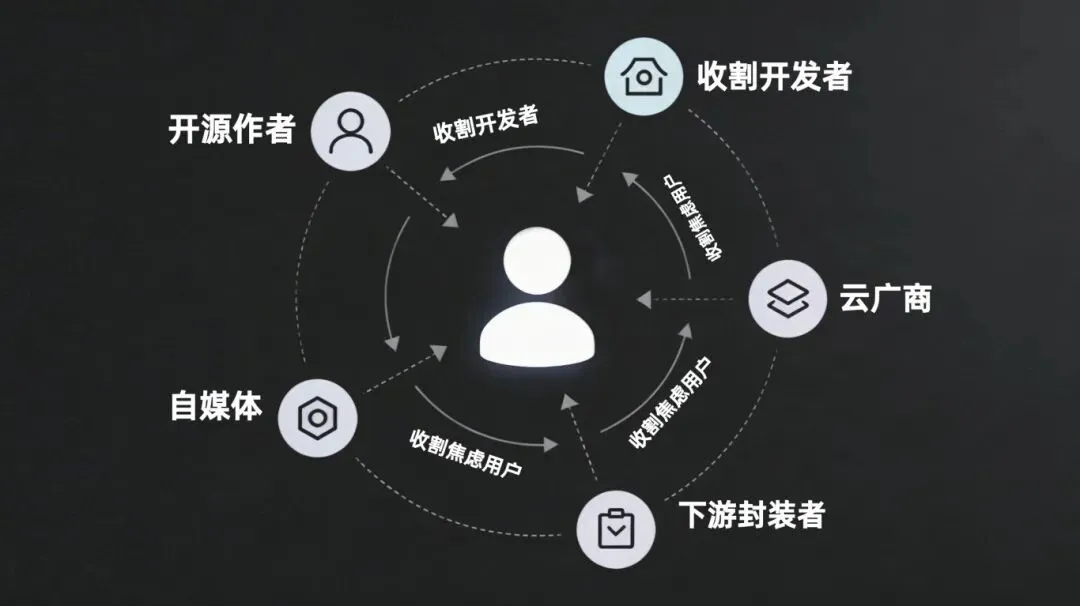
三、利益方解剖:分食你的价值

在这个利益链条中:
开源作者通过 GitHub 星数资本化和被收购预期获益,将维护成本转嫁给社区,收割的是贡献代码的开发者。
云厂商推出 QClaw/ArkClaw 托管服务来解决 OpenClaw 故意设置的门槛,开发成本依赖开源社区,收割跑不通本地部署的焦虑用户。
自媒体利用“一键部署教程”流量变现,技术验证成本转嫁给用户,收割试图降低门槛的跟风者。
下游封装者如 OneClaw、EasyClaw 提供“开箱即用”版本,直接 Fork 开源代码,收割不愿折腾的末端用户。
用户(你)则获得“数据主权”的幻觉,却支付了设备成本、学习时间和数据资产,成为全体早期测试者的被收割对象。
核心机制:OpenClaw 维持高门槛 → 用户产生焦虑 → 云厂商提供“解决方案” → 用户付费并贡献数据。开源作者制造焦虑,云厂商缓解焦虑,用户是唯一买单方。

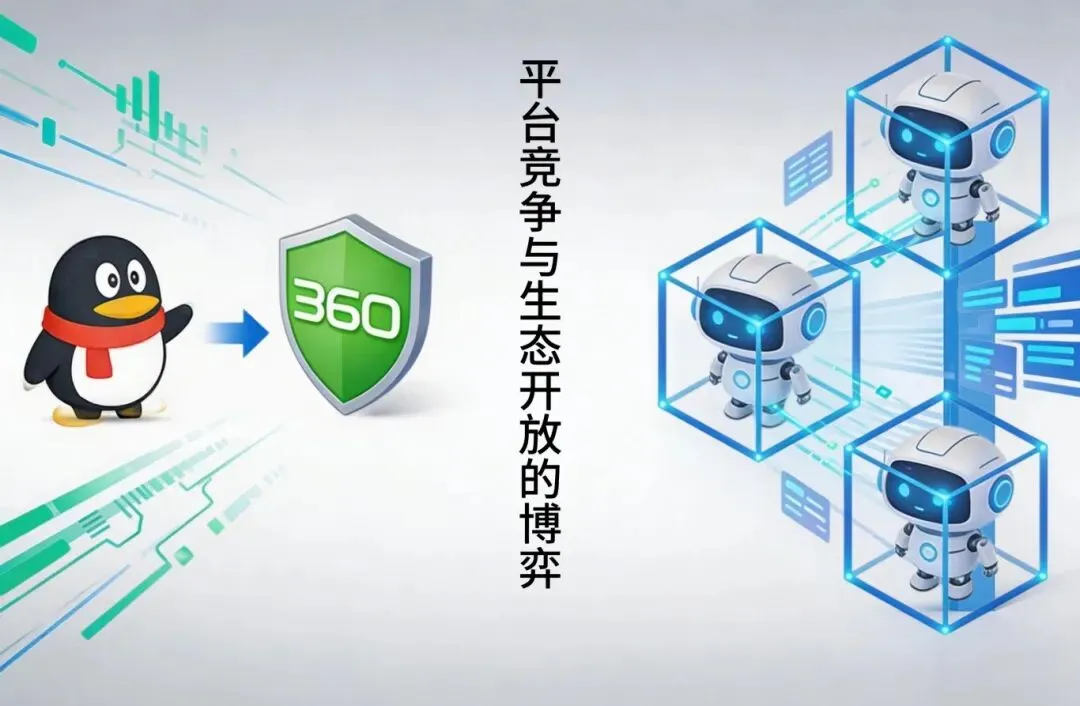
四、3Q 大战启示录:从“二选一”到“Agent 割据”

2010 年,腾讯与 360 爆发“3Q 大战”,强迫用户在 QQ 和 360 之间“二选一”,
数亿用户被当作争夺筹码而非服务对象,被迫接受弹窗恐吓和软件不兼容。
最终工信部介入,腾讯虽赢得官司但输了舆论,从封闭走向开放。
今天的 Agent 生态正在重演历史:QClaw、Kimi Claw、MaxClaw 各自为战,记忆互不相通。你在 OpenClaw 训练三个月的偏好、业务逻辑,无法迁移到其他平台,被迫重复训练或多平台维护。
用户依然是被争夺的筹码,而非被服务的中心。
马化腾的觉醒值得铭记:3Q 大战让腾讯意识到“用户是生态的中心,不是战利品”。今天的 AI Agent 行业却在重复当年的错误——将用户当作数据佃农而非生态中心。

五、用户中心论:夺回数字主权

1.拒绝“信仰税”
等待商品化阶段再入场。看到“革命性Agent”,先去 GitHub 搜“autonomous agent”,识破换皮代码(AutoGPT 182k stars vs OpenClaw 数k stars)。
2.数据防火墙
在 Docker/虚拟机中运行 Agent,投喂假数据污染训练集。定期导出 USER.md,拒绝数字记忆绑架。
3.协议反击
贡献 Skills 时使用 GPL/AGPL 强 Copyleft 协议,迫使集成方开源衍生作品,不让云厂商白嫖。
4.平台中立
选择支持多模型 API 的框架,拒绝单一生态绑定。采用渐进式安全(本地无限制 + 远程密码认证),而非非此即彼的二选一。
5.要求互操作性
要求支持 USER.md 标准导出,打破记忆孤岛,拒绝生态锁定。

OpenClaw 验证了一个危险公式:门槛 + 焦虑 = 数据收割机。
3Q 大战教会我们:用户被当筹码时,行业整体受损;用户被当中心时,生态才能繁荣。
你不是在参与技术革命,你是在自费参与一场针对你自己的数据采集实验。
GitHub 上躺着 182k stars 的 AutoGPT 和体积小到 98% 的 Nanobot,它们不制造焦虑,不要求你开放系统权限——技术从来就在那里,只是你选择被收割。
用户才是中心。别让自己成为下一个数字佃农。
附录:
《OpenClaw”养龙虾”热潮:深度调查报告》
报告编制日期:2026年3月调查对象:OpenClaw AI Agent框架(曾用名Clawdbot/Moltbot)核心议题:技术民主化还是安全灾难的转移?
详见飞书文档:
https://rako5rhbymj.feishu.cn/wiki/BEOtwYS6HiLesrk5E60czhnknjd?from=from_copylink


END


欢迎加入AI商学院
商务合作:13917563317
