 夜雨聆风
夜雨聆风各位道友请了!
我是猫来gogogo,一介 AI 散修 。
AI一天,人间一年。
1、背景:
我们知道,
公众号文章有严格的反爬机制,
页面结构也和普通网页不一样。
很多通用抓取工具,一上来就会遇到这些问题:
- •
请求被拦,返回异常内容
- •
抓不到正文,只拿到壳页面
- •
标题、封面、图片提取不完整
- •
抓出来一堆噪音,根本没法直接用
- •
同一个方案,换一篇文章就失效
所以我专门做了这个 skill。 专门解决 公众号文章抓取 这件事。
最终效果是:
- •
只需要提供公众号链接,这个 skill 就可以:
- •
抓出封面图,文章标题;
- •
抓出文章正文,包括图片;
- •
如果在飞书中,让小龙虾用这个skill,还会自动写飞书文档。
2、成果演示:
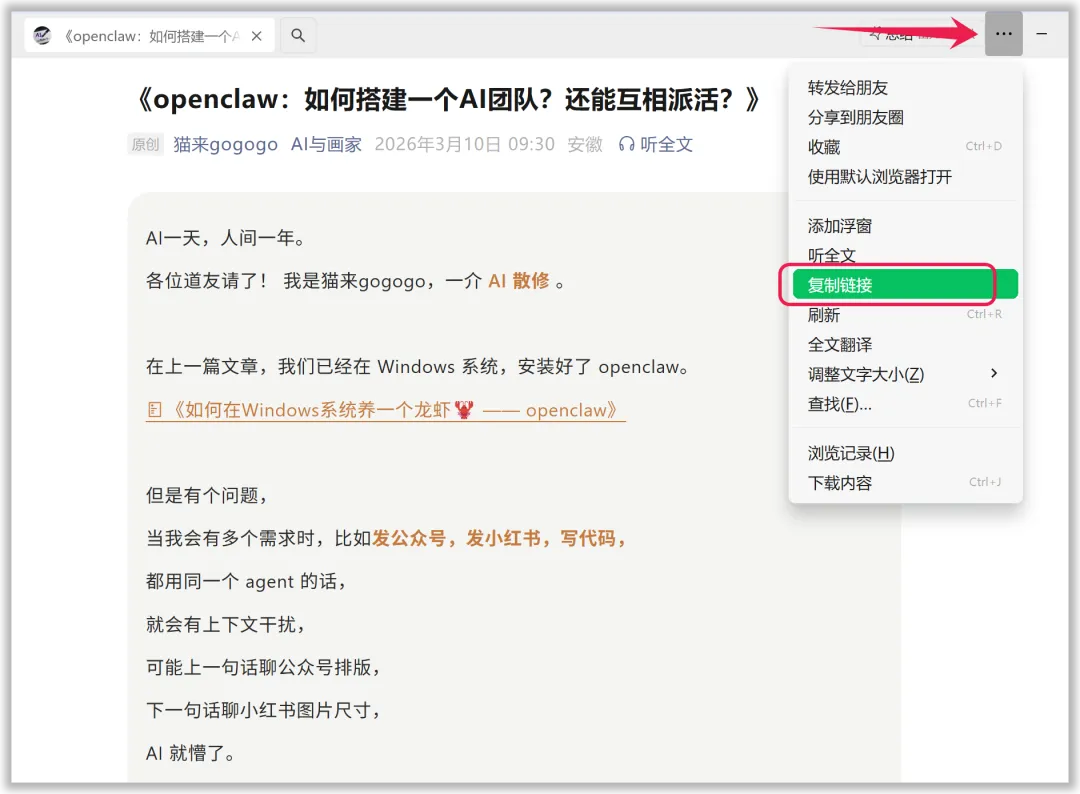
首先复制公众号链接,我以自己的一篇公众号为例:
原文链接:https://mp.weixin.qq.com/s/_rI1LdrY5KcZfMTsxBHIGw
然后在飞书中,把链接发给我的小龙虾,并让它抓取这篇公众号文章:
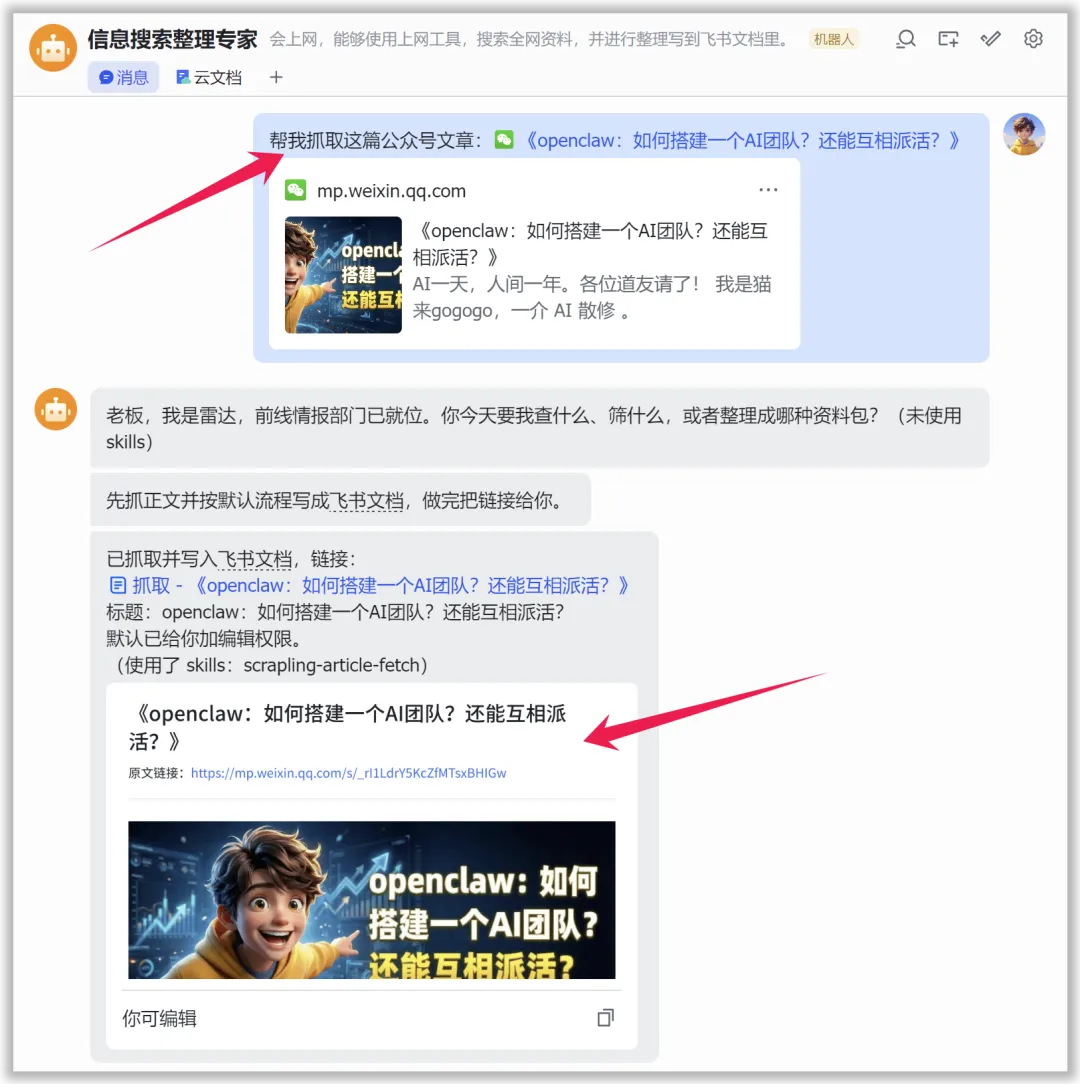
过了一会,不仅文章抓取好了,
飞书云文档也写好了,
我的编辑权限也打开了。
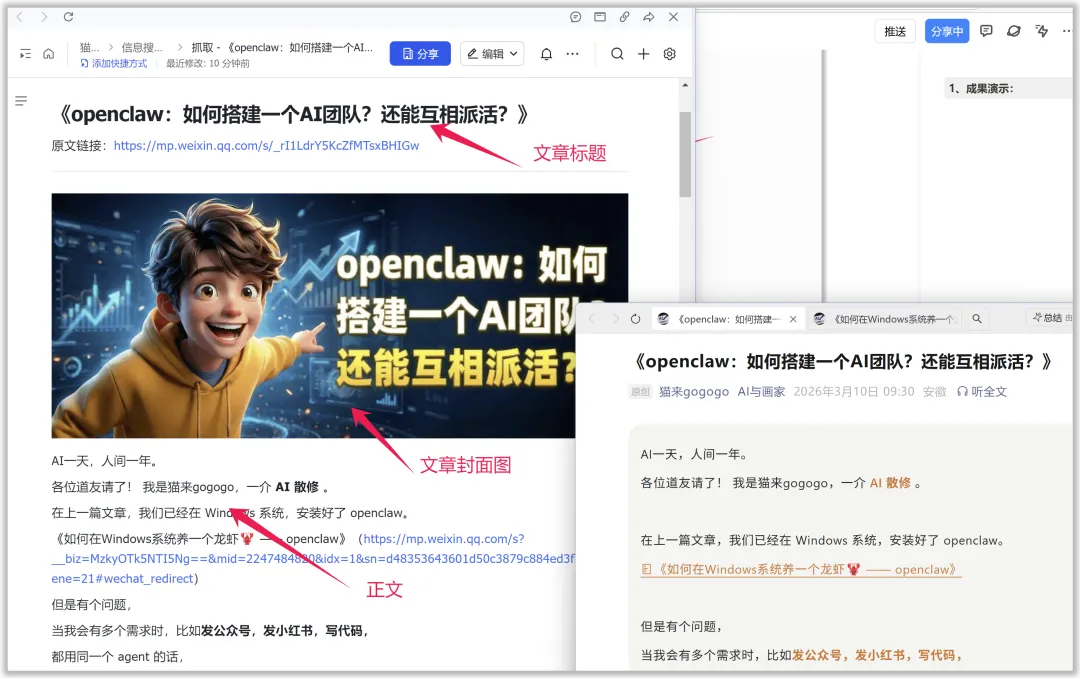
我们打开飞书文档看看效果,
文章标题、封面都在;
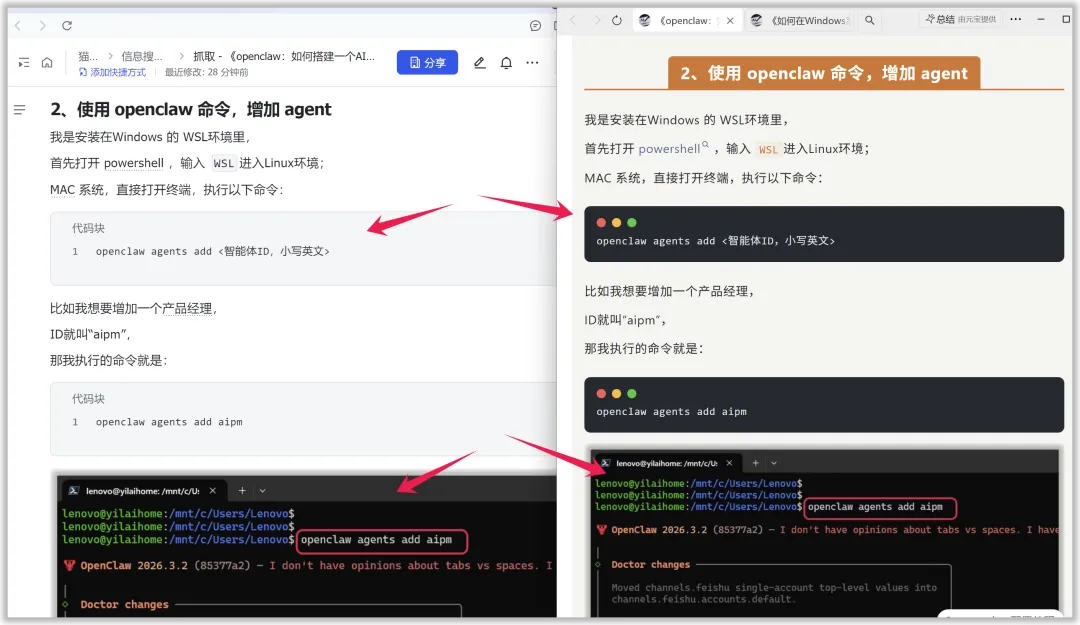
再继续往下看,
标题,代码块,图片都在,
完美~
接下来,你想基于公众号内容改写,
或者把多篇同类型的文章一起让AI分析都可以,
希望大家合理使用。
3、如何得到这个 skill ?
我已经开源到了 GitHub 上~
https://github.com/maolai7/agent-skills/tree/main/scrapling-article-fetch
直接复制 GitHub 链接给你的小龙虾,或者其他AI,让它自己安装就行。
如果不能打开GitHub, 后台私信【抓取公众号skill】,
我会自动回复你这个skill文件。
你把文件下载下来以后,
手动复制到你本地的 skills 文件夹目录下,就可以使用了。
如果有问题可以评论区留言,我再迭代优化。
感谢你看到最后。
这篇分享就到这里啦,希望其中的内容, 能给你带来一点点启发 。
如果你觉得有收获,欢迎点个「在看」和「转发」,
也欢迎关注我,之后我会继续 分享更多 AI 学习、使用和实践笔记。
我是「猫来gogogo」,一边学习,一边记录这个 AI 时代。
我们下次再见。
往期精彩推荐:
