 夜雨聆风
夜雨聆风
各位折腾 AI 管家的朋友,最近是不是被 API 账单“背刺”了?
前两天在开发者交流区看到,有个哥们只是用默认配置跑了几天 OpenClaw,月底一查,340 美元的纯 API 费用直接让他破防。还有更离谱的,仅仅是因为后台监控配错了一个小参数,睡一觉醒来 141 美元就没了。
OpenClaw 确实香,能连通讯软件、能读写本地文件、甚至能直接接管浏览器帮你干活。但这种“赛博全自动”体验的背后,其实藏着无数个疯狂烧钱的小黑洞。今天咱们不拽那些高深莫测的架构词汇,就掰开揉碎地聊聊,你的 Token 到底是怎么没的,以及怎么用一套最接地气的方法,把成本断崖式地降下来。
一、 你的钱到底花哪了?(扒一扒底层的吞金机制)
别再把 OpenClaw 当成简单的“对话框”了。它其实是个死磕细节的“控制狂”,每一次行动都在偷偷疯狂消耗你的流量。
1. 越滚越大的“聊天包袱”:每次你发一句话,系统不仅发你的话,还会偷偷打包一大堆东西:系统基础指令、当前能用的技能清单、你的本地习惯设置文件,还有之前长篇大论的聊天记录。这就导致,在调试了几个小时代码后,你哪怕只发一句简单的指令,系统可能都在向大模型发送几万字的冗余历史。
2. 看不见的“工具说明书”:为了让大模型准确操作你的电脑(比如查日历、发邮件),系统必须把这些工具的详细使用规范(严格的 JSON Schema)全发给模型。这些看不见的规则定义,全都在悄悄吃你的请求额度。
3. 潜伏在后台的“吞金兽”:心跳机制如果你不改配置,OpenClaw 默认每半小时就会在后台唤醒一次,问问大模型“有没有什么事要办?”。更要命的是,它默认会用最贵的全局主模型来回答这句废话,顺便把刚才说的那一大堆上下文全传一遍。一天下来啥正事没干,快 7 美元就烧没了。
4. 系统清理内存时的“暗坑”:当聊天记录快撑爆大模型上限时,系统会自动触发一次静默清理,让大模型把关键记忆写进本地文档。这时候有个隐藏的坑:如果你没给大模型预留足够的输出空间(reserveTokensFloor 参数),大模型写总结写到一半就会直接报错。结果就是:昂贵的推理 Token 烧了,重要记忆还没存上,妥妥的赔了夫人又折兵。
二、 止血指南:手把手教你改配置
看懂了它是怎么偷跑额度的,我们就知道该怎么对症下药了。
第一招:别拿大炮轰蚊子,给任务分配不同档次的模型
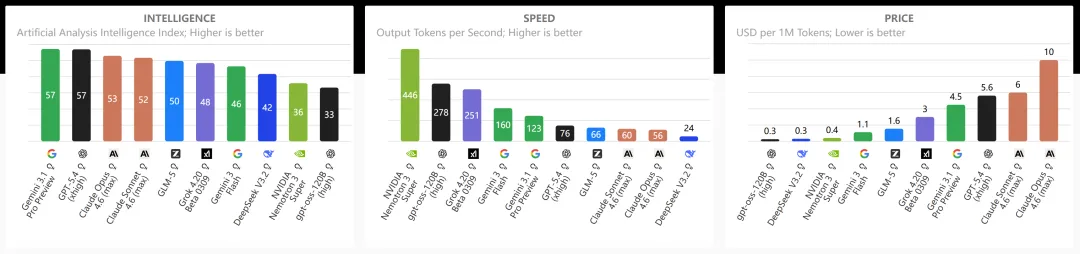
很多朋友不管干啥都用最强的模型,这太奢侈了。我们要学会“看人下菜碟”,除了国外的模型,强烈建议接入国内高性价比的开源或付费模型:
后台心跳 / 状态监听:坚决换成便宜模型!强烈建议接入本地免费运行的 Ollama (比如qwen3.5 9b),实现零成本待机。如果嫌本地跑麻烦,可以直接切到国产的 DeepSeek-V3.2 或者 Kimi K2.5,成本直接砍掉 90%。
日常调度 / 轻量文字处理:交给通义千问 Max、DeepSeek 或者是 GPT-5-mini 就足够了。处理常规的工具调用,速度快价格又香。
深度代码重构 / 复杂逻辑:好钢用在刀刃上。这种容错率极低的任务,再请出 Claude 4.6 Opus 这种旗舰级选手,以防产生劣质结果导致无限报错。
💡 避坑提示:部分老版本系统有个 Bug,会导致心跳配置失效,强制调用贵模型。遇到这种情况,高级玩家通常会把内置心跳关掉,用电脑自带的定时任务配合小脚本来触发。
第二招:勤倒垃圾,及时清理没用的工具日志
当大模型去执行终端命令、搜索网页或者抓取文件时,往往会带回来成千上万字的“冗余数据”。如果不管它,这些垃圾数据会永远驻留在会话内存中,迅速逼近大模型上下文的极限。
要清理这些垃圾,你需要打开 OpenClaw 的本地配置文件(通常在 ~/.openclaw/openclaw.json 中),找到 contextPruning(上下文修剪)功能。这里有两种核心工作模式,你需要根据自己的使用习惯来配置:
场景 A:你是断断续续地提问(推荐配置
cache-ttl缓存过期模式)
如果你是偶尔问个问题,敲完指令去喝口水,推荐使用官方默认的智能配置 cache-ttl。它的逻辑是:只要你的会话闲置超过指定时间(比如 5 分钟或者 1 小时),系统就会自动把那些过期的工具返回结果“卸载”掉。这就好比去餐厅吃饭,吃完赶紧撤盘子。这个模式能完美配合大模型提供商的提示词缓存(Prompt Caching)机制,防止后续被重新激活时产生全额的重传计费。
场景 B:你在高强度连续敲代码(必须配置
rolling消息计数滚动模式)
如果你在让 AI 帮你疯狂写代码、连续数十次无间断交互,会话根本不会闲置,cache-ttl 模式就无法触发修剪。这时候必须开启按交互回合数修剪的 rolling(或 message-count)模式。它会在每次调用大模型前运行,把超出指定交互回合的陈旧工具结果进行“软修剪”或“硬清除”。
👇 可以直接抄作业的 JSON 配置代码:
如果你属于高强度使用的极客,可以直接把下面这段代码合并到你的 openclaw.json 配置中 :
"agents": {"defaults": {"contextPruning": {"mode": "rolling", // 开启滚动修剪模式 [cite: 64]"keepLastAssistants": 8, // 核心机制:只保留最近 8 轮的完整交互 [cite: 65]"minPrunableToolChars": 50000, // 仅对超过 5 万字符的超长工具结果“开刀” [cite: 67]"softTrim": {"maxChars": 4000, // 软修剪后最多保留 4000 字符 [cite: 70]"headChars": 1500, // 保留头部 1500 字符(通常是执行环境与前置状态) [cite: 71]"tailChars": 1500 // 保留尾部 1500 字符(通常包含核心的报错堆栈或成功标识) [cite: 72]},"hardClear": {"enabled": true, // 开启硬清除 [cite: 74]"placeholder": "[Old tool result content cleared]" // 显式占位符,避免大模型产生幻觉 [cite: 75]}}}}
把这段配置加上,就像是给你的智能体装了一个自动运转的“垃圾粉碎机”。那些动辄几万字的网页抓取记录、报错堆栈,只要超出了你设定的 8 轮对话,就会被自动掐头去尾,或者直接替换成一句 [Old tool result content cleared]。这能帮你省下海量的 Token 冤枉钱。
第三招:别盲目追求“多智能体”,一个主脑带技能库就够了
刚上手时,大家都喜欢建一堆互相独立的子智能体,什么财务专家、代码专家分得清清楚楚。但实际上,每次这些智能体互相交接工作,都要重新加载一遍各自的背景设定,不仅慢,Token 浪费还极其严重。
真正精打细算的玩法是:养一个全知全能的单一“主智能体”,然后把那些专业能力拆解成一个个轻量级的技能文件。平时系统只给大模型看个“技能目录”,遇到具体问题了,大模型再去按需阅读对应的技能详情。这样一来,本来常驻的几万字背景介绍,瞬间被压缩到了几百个字的目录级别。
三、 写在最后
玩转这种全自动的 AI 管家,其实就是在跟计算资源精打细算地过日子。别让最强的模型干打杂的活,别逼着它背下整本百科全书再工作,更别让没用的历史数据一直堆着。只要稍微花点时间把底层逻辑理顺,这台 AI 引擎绝对能跑得又快又省钱。
