 夜雨聆风
夜雨聆风
题图摄于故宫
最近,科技圈被一只“龙虾”(OpenClaw)刷屏了。它之所以火爆,是因为打破了传统 AI 的“只说不做”的规律,能真正理解指令并直接操作电脑完成任务。它是怎样做到的呢?本文将深入解读 OpenClaw 完成任务的机理。
想象一下,你手下有位特别靠谱的行政助理,接到了这样一个任务:
“把上个季度所有部门的会议纪要翻一遍,找出已经拍板的决策事项,按部门整理成一份简报,下午领导要看。”
这位助理会怎么做?
今天要聊的 OpenClaw,干的就是这么个事儿——只不过,它的“脑子”是大语言模型,它的“手”是本地各种工具。两者配合,才能把一个模糊的自然语言请求,变成实实在在的交付成果。
OpenClaw是个啥?一句话:大脑+工具箱
OpenClaw 是一个基于大语言模型的任务执行框架。它的设计理念特别简单:
每一次任务,都是一场大模型和工具之间的“多轮对话”:大模型发指令,工具执行并回报结果,大模型看了结果再接着思考下一步……直到任务搞定。
举个例子:整理会议纪要,生成决策简报
咱们来个实打实的办公场景:
这活儿要是人干,少则十几份、多则几十份文件,每份都得仔细看,还得分辨哪些是“真拍板”,哪些只是“讨论讨论”。下面是 OpenClaw 干这活儿的全过程:
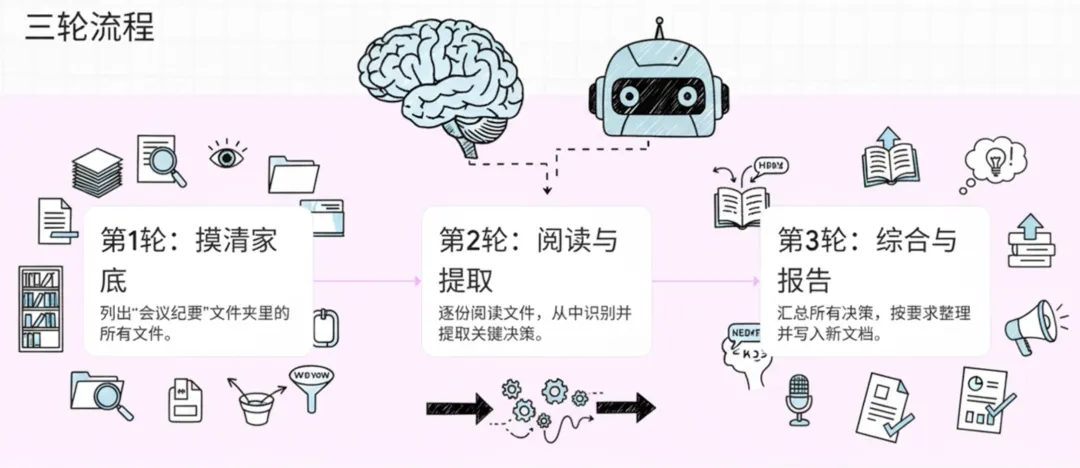
第1轮:先摸清家底
用户下达指令后,OpenClaw把它连同可用工具清单一起发给大模型。大模型像个刚接手任务的小组长,先琢磨:“要干啥?从哪下手?”
它推理:要处理会议纪要,得先知道文件夹里有哪些文件。于是发出第一个指令:列举“会议纪要”文件夹所有文件。
OpenClaw 执行指令,返回 18 份文件名,比如“2025Q1_市场部_产品策略会.docx”、“2025Q1_技术部_架构评审会.docx”。
这一步的精髓:大模型没瞎猜,而是先看全貌——就像新助理不会连文件柜都没打开就动笔写报告。
第2轮:逐份阅读,提取决策
拿到清单后,系统把文件名拼进上下文,再次调用大模型。这回大模型看到了真实文件,开始干正事:一份份读,从中找出“已确认的决策”。
它连续发出多个文件读取指令,OpenClaw把一份份纪要正文返回来。大模型开始“阅读”:
遇到“会议决定,自下季度起将华东区销售目标上调15%”或“技术部确认采用新数据库方案,由王工牵头推进”,它能准确识别这是拍板的决策,记下内容、部门和日期。
碰上“有人提出可以考虑”“下次再研究”,就自动过滤掉。
这是全流程的高光时刻:十几份散乱纪要,在大模型手里变成结构清晰、分类明确的决策清单。这种语义理解力,是关键词搜索永远做不到的。
第3轮:整理成文,写入文档
所有纪要读完、决策提取完,大模型进入收尾:把结果整成用户要的简报。
它按部门归类决策条目,每条注明来源会议和日期,格式简洁清爽。然后调用文件写入工具,保存为新 Word 文档,命名“2025Q1_各部门决策汇总简报.docx”。
完成后,OpenClaw 回报用户:简报已生成,共涵盖18份会议纪要,提取47条明确决策,按市场、技术、运营等六部门分类,文档已保存至指定位置。
整个过程调用大模型3次。每一次都在前一次基础上累积更多上下文——从“不知道有啥文件”到“读完了所有内容”再到“整理好可以交差”,一步步收敛到最终结果。
为啥非得折腾好几轮?一次干完不行吗?
这是个好问题。它恰恰点出了大模型的本质局限。
第1轮:感知——用大模型理解任务,规划第一步行动 第2轮:行动与反馈——工具执行,结果返回,大模型根据真实内容调整判断 第3轮(及更多):收敛——基于充分信息,完成最终输出
五、这背后有个“洋气”的名字:ReAct范式
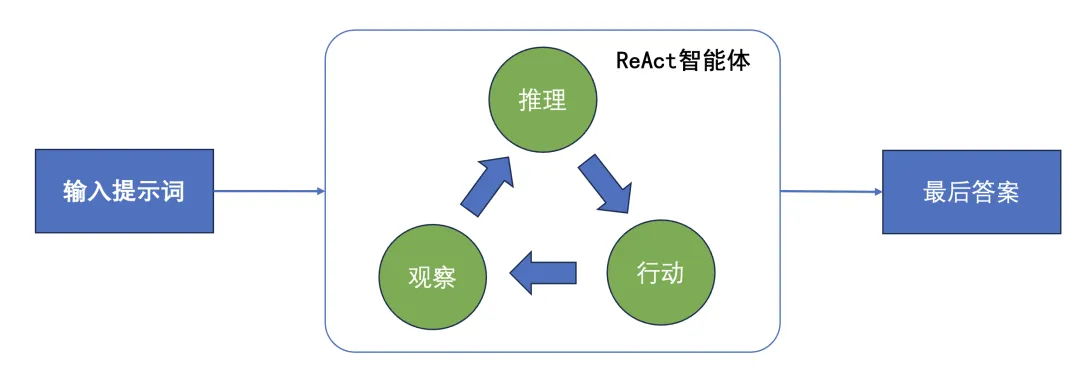
想:大模型分析当前状态,判断下一步干啥,比如用什么工具,获取什么信息等等 做:调用工具,执行具体操作 看:把工具返回的结果送还给大模型,作为下一轮推理的输入
就这么转圈,直到大模型判断任务已完成,输出最终答案。
这个循环里,不同的模型的结果差异很大,也决定了哪个模型更聪明。聪明的模型可以用较少的轮次成功地解决问题;“笨”的模型则需要更多的轮次才能找到答案,或者根本就找不到问题的解。
这里学问很多,打算另外写篇文章来探讨更多的细节,也回答诸如“为什么我的模型很费token”这类问题。
LangChain、AutoGen、OpenAI 的 Function Calling(函数调用),本质上都是 ReAct 这个思路的工程实现。
这套“想—做—看”的循环,不只是 OpenClaw 在用。如果你关注过最近火热的 AI 编程工具——比如 Cursor、 Winsurf,或者所谓 Vibe Coding 的玩法——会发现它们底层也是同样的逻辑。
只不过,OpenClaw 的双手是文件读写工具,目标是帮你整理文档;而 Vibe Coding 的双手是代码编辑器、编译器和终端,目标是帮你写出能跑的程序。
一个是行政助理,一个是程序员助理;干的活儿不一样,但干活的方式出奇地一致。这也说明,ReAct 正在成为 AI 智能体执行真实任务的通用模式。
本地工具:从“知道”到“做到”的最后一公里
如果说大模型是“知识渊博的军师”,那本地工具就是“能动手干活的士兵”。少了谁都不行。
OpenClaw 支持好几种本地工具,常见的有:
文件系统工具:列举、读取、写入各类文档。这是绝大多数办公任务的地基——不管处理 Word、PDF 还是表格,都离不开它。 格式转换工具:在不同文件格式间转换,比如把PDF转成可编辑文本,或者把多份文档合并成一份,满足公文处理的各种要求。 网络工具:访问在线资源、查数据库、调企业内部系统接口,让大模型能拿到本地文件之外的实时信息。 代码执行工具:对数据做计算、统计、分析,适合需要对大量文档内容做定量汇总的场景。
OpenClaw的设计围绕三条核心原则:
第一,决策与执行分离。大模型只负责“想”,工具只负责“干”。大模型灵活但够不着文件,工具可靠但听不懂人话——各司其职,互不越界。
第二,上下文累积驱动推理。每一轮工具执行的结果,都追加进上下文,作为下一轮思考的依据。就像助理桌上堆的资料越来越多,判断自然越来越准。
第三,自主判断何时收工。大模型每轮自己判断:任务没完就接着调工具,处理好了就生成答案。这种自主性,让 OpenClaw 能应对开放式任务,而非死板的固定流程。
绕不开的问题:数据隐私咋办?
读到这里,细心的人可能犯嘀咕:会议纪要送进大模型,内部信息不就泄露出去了吗?
这顾虑没错。调用公有云API,文件确实经网络传到第三方服务器。碰上机密数据,风险不容忽视。
好在有解。实际部署有几种成熟路子:
本地化部署。在企业内网部署开源大模型(如Llama、Qwen、DeepSeek),推理全程内网完成,数据不出企业网络。
企业专属服务。主流云厂商提供专属服务,合同承诺数据不用于训练、不作留存,适合有合规要求但暂不自建的情况。
数据脱敏。送进大模型前,先用工具对人名、金额等敏感字段做替换,处理完再还原,降低实质风险。
说白了,问题不在“能不能用AI”,而在“怎么用”。合理部署,完全能在享受智能化效率的同时,把隐私风险控制在可接受范围。
写在最后
当大模型和本地工具紧密协作,当多轮调用把感知与推理串成完整闭环,原本需要数小时人工处理的文档工作,就可以交给系统自主完成。

欢迎关注 亨利笔记, 👍 点赞 | ⭐ 收藏 | ↗️ 转发。欢迎评论区聊聊你的看法。
近期文章:
龙虾政策直击:OpenClaw 爆火背后,OPC “超级个体”时代真的来了
别再只会写提示词了!MCP+Skills这两大杀器,正在终结“AI智障”时代!
本公众号聚焦人工智能,云原生和区块链等技术原理,请立即关注亨利笔记( henglibiji ),以免错过更新。
