 夜雨聆风
夜雨聆风核心洞察:OpenClaw 使用过程中,Token 消耗随上下文长度呈正相关增长。缺乏系统性管控时,同一问题的 Token 消耗可从数千级跃升至数十万级。本文基于MECE 原则,从操作层、架构层、知识管理层三个维度,构建完整的 Token 降本框架。
一、操作层:斜杠命令体系——即时降低单次对话成本
底层逻辑:每次 API 调用的 Token 消耗直接由上下文长度决定。通过内置斜杠命令,可在不影响业务连续性的前提下,快速压缩或重置上下文。
三条命令均在聊天框中直接发送,零配置成本。
1. /compact —— 上下文压缩
功能:对当前会话历史执行摘要式压缩,保留关键信息节点,清除冗余数据。
适用场景:
场景 A:长对话导致响应延迟与成本上升 场景 B:任务尚未完成,无法清空上下文 场景 C:仅需核心结论,无需全量历史
操作方式:直接发送 /compact
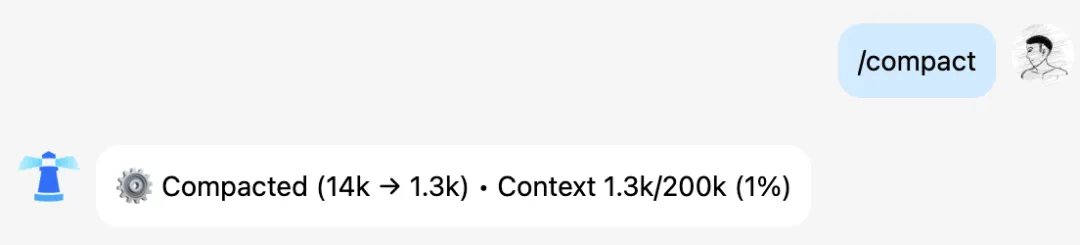
量化结果:单次执行可实现 14k → 1.3k 的上下文压缩,压缩率超过 90%。后续每轮对话的边际 Token 成本显著下降。
2. /reset —— 短期上下文重置
功能:清空当前会话的短期上下文,保留长期记忆与全局配置。
关键区分:
| 清除项 | 保留项 |
|---|---|
| 当前对话历史 | 个人偏好设置 |
| 临时讨论内容 | 项目背景信息 |
| 已过期的任务上下文 | 团队代号与配置 |
适用场景:
场景 A:任务切换——当前话题结束,进入全新议题 场景 B:上下文膨胀——Token 消耗持续走高 场景 C:需保留组织知识——历史培训数据不可丢失
操作方式:直接发送 /reset
3. /new —— 全新会话实例
功能:创建完全独立的新会话,与历史上下文零关联。
适用场景:
场景 A:需要无干扰的精确输出环境 场景 B:A/B 测试——对比有无上下文的输出差异 场景 C:同一频道内并行多条独立对话链
操作方式:直接发送 /new

三命令对比矩阵:
| 命令 | 历史上下文 | 长期记忆 | 适用场景 |
|---|---|---|---|
/compact |
压缩保留 | 保留 | 同话题继续,降低成本 |
/reset |
清空 | 保留 | 切换话题,保留认知 |
/new |
清空 | 不继承 | 全新隔离环境 |
二、架构层:多 Agent 分工——从组织设计降低系统性成本
底层逻辑:单一 Agent 承载多职能任务,会导致上下文交叉污染和线性膨胀两个结构性问题。
问题诊断:
第一,记忆熵增:代码、文档、运营、管理等异构信息混杂于同一 workspace,模型推理时需在大量无关数据中低效检索。
第二,上下文膨胀:为维持信息连续性,持续向同一 Agent 注入历史数据,Token 消耗呈非线性增长。
解决方案:职能化 Agent 架构
第一步,按团队/飞书群/职能维度拆分独立 Agent
第二步,为每个 Agent 配置专属 workspace、记忆库、技能集与模型
第三步,确保各 Agent 的对话历史与知识积累物理隔离
赋能效果:
✅ 上下文纯度提升 — 单个 Agent 聚焦单一领域,推理精度提升 ✅ 成本可量化 — 按 Agent 维度独立计量,精准归因 ✅ 运维闭环 — 问题排查与优化可针对特定 Agent 独立执行
💡 落地参考:配置相互独立 Agent(飞书多 Agent 实战教程)
最佳实践:架构层拆分 + 操作层精控形成完整闭环。先通过多 Agent 分工实现宏观隔离,再在每个 Agent 内部用 /compact / /reset 做微观调控。
三、知识管理层:memory-search——从"全量加载"到"按需检索"
底层逻辑:将知识存储与知识调用解耦,用检索替代上下文堆叠,实现 Token 消耗的边际递减。
核心机制:OpenClaw 的 memory-search(默认开启)支持 Agent 在推理时主动检索历史记忆,而非依赖上下文全量加载。
实施路径:
第一步,将关键信息固化到 memory 文件 / 知识库
第二步,Agent 在推理时通过查询接口检索相关片段
第三步,模型输入 = 当前问题 + 精确匹配的记忆碎片
ROI 对比:
| 维度 | 全量上下文模式 | memory-search 模式 |
|---|---|---|
| Token 增长曲线 | 线性递增 | 趋于稳态 |
| 信息精准度 | 噪声干扰大 | 精确匹配 |
| 长期可持续性 | ❌ 不可持续 | ✅ 可持续 |
关键动作:每完成一轮重要对话或任务后,向 OpenClaw 发出指令——"记住这些关键信息"。这是激活 memory-search 长期价值的必要条件。

总结:三层策略框架
基于以上分析,Token 降本的完整策略框架如下:
🔹 操作层 —
/compact、/reset、/new,实现单次对话级成本控制 🔹 架构层 — 多 Agent 职能化分工,实现系统级成本隔离 🔹 知识管理层 — memory-search 按需检索,实现长期成本收敛
预期产出:
质量维度 — 对话响应稳定性提升,输出偏差率下降 成本维度 — Token 月度消耗从"持续爬坡"转为"平稳可控"
以上三层策略相互赋能,形成完整的降本增效闭环。
如果本文对你的团队有参考价值,欢迎点击「在看」扩散。
关于 Token 管理,你的团队还有哪些实战经验?欢迎在评论区交流,共建最佳实践。
声明:本文灵感来源于腾讯云开发者社区。OpenClaw 使用推荐云上部署,云上部署推荐使用腾讯轻量云 Lighthouse。养虾就用轻量云。 🦞
