 夜雨聆风
夜雨聆风大家好,我是AI产品经理Hedy!
一、我做的AI助手,自己都用不下去
凌晨2点,我盯着屏幕上的报错信息,崩溃了。
这是我花了3个月业余时间做的AI助手——能帮我整理邮件、安排日程、回复消息。上周还在朋友圈炫耀"终于有了自己的AI秘书",今天就被现实打脸。
它出了什么问题?
我问它:"把刚才那封邮件标记为重要" 它回我:"请问您需要什么帮助?" ——3秒前的对话,它完全不记得了。
早上打开应用,页面转了30秒才出来。查日志,除了一堆API调用记录,根本看不出卡在哪。更崩溃的是OpenAI账单:这周末两天,测试费烧了200美金。
我给自己做的工具,自己都不想用了。
其实一个月前,我还觉得AI产品很简单。
第一版跑通时,朋友看了Demo都说"太牛了" 我当时真以为:写点Prompt,调几个API,就能做出能用的AI产品。
但真正每天用起来,问题接二连三。
每次都要重复说三遍才听懂 经常要手动检查它有没有干错事 想加个新功能,发现要重写一大堆逻辑
我试过加长Prompt、换更模型、写一堆日志,都没用。
直到朋友给我发了篇关于OpenClaw的文章,我才恍然大悟。
原来我缺的不是更强的LLM,而是完整的架构思维:
Gateway - 多个数据源要统一管理,不能每个都单独对接 Memory - AI得真正"记住"对话,不是每次都从头开始 Skills - 每个能力要标准化,不能都写死在代码里 Subagent - 复杂任务要拆解,不能让一个AI干所有事 Runtime - 出错要能重试、能追踪,不能一挂就完蛋
我花了两周重构,现在这个助手我每天真的在用。
所以这篇文章,我想分享的是思维方式,不是代码。
接下来用最接地气的语言,拆解OpenClaw的五大核心组件。
只讲:为什么需要、怎么用、我踩过哪些坑。
希望能帮你少走弯路。
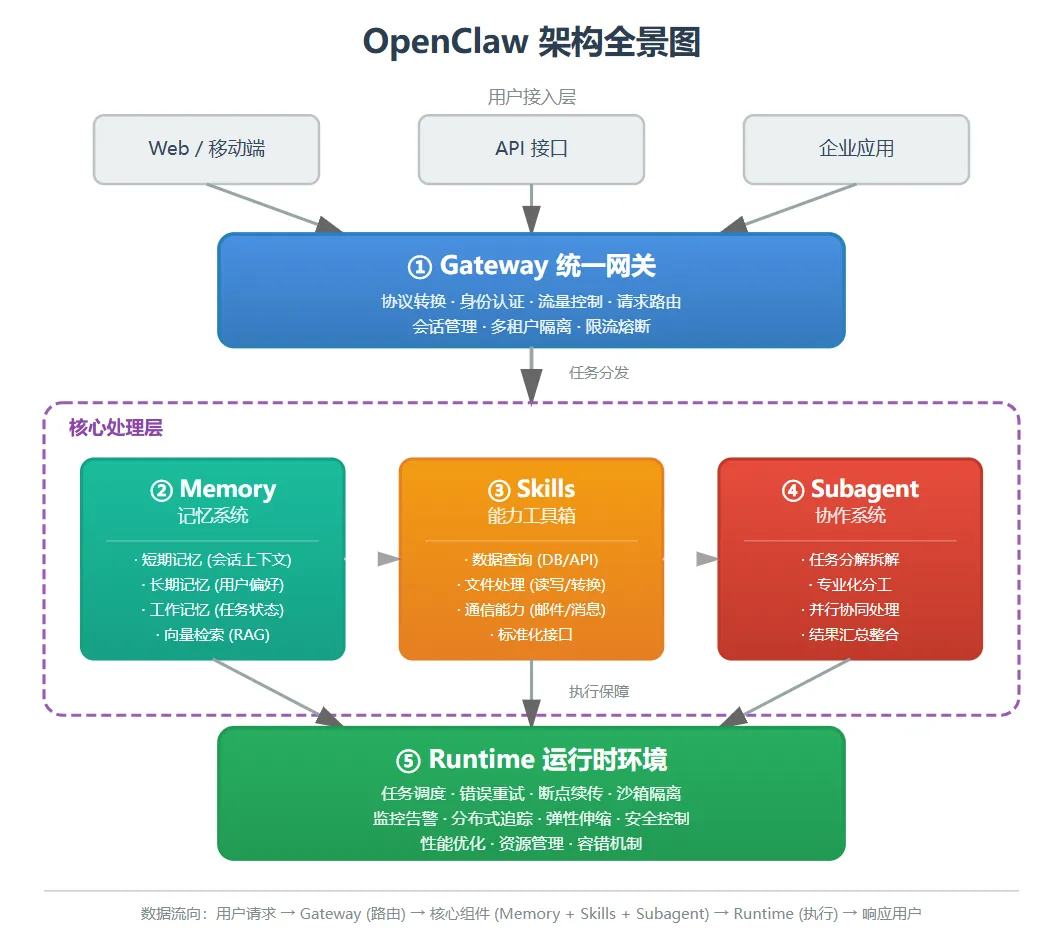
二、Gateway:Agent的统一入口
2.1 产品视角:为什么需要Gateway?
想象你正在构建一个客服Agent,用户可能通过以下方式接入:
Web网页聊天窗口 微信小程序 企业微信 API接口调用 语音电话
没有Gateway的世界:你需要为每个渠道写一套适配代码,消息格式不统一,用户身份认证各自为政,监控日志分散在各处。
有了Gateway之后:所有请求统一从Gateway进入,自动完成:
协议转换(HTTP/WebSocket/gRPC → 统一内部格式) 用户认证(Token验证、权限检查) 请求路由(根据用户属性分配到不同Agent实例) 流量控制(限流、熔断、降级)
2.2 技术实现:Gateway的三层架构
┌─────────────────────────────────────────┐│ Protocol Layer │ ← 接入层:处理各种协议│ (HTTP, WebSocket, gRPC, MQTT...) │└─────────────────────────────────────────┘ ↓┌─────────────────────────────────────────┐│ Gateway Core │ ← 核心层:统一处理│ - Auth & Authorization ││ - Rate Limiting ││ - Request Validation ││ - Logging & Monitoring │└─────────────────────────────────────────┘ ↓┌─────────────────────────────────────────┐│ Router Layer │ ← 路由层:智能分发│ - User-based routing ││ - Load balancing ││ - Circuit breaker │└─────────────────────────────────────────┘2.3 关键设计决策
决策1:同步 vs 异步
OpenClaw的Gateway支持两种模式:
同步模式:适合简单问答,用户等待即时响应 异步模式:适合复杂任务,Gateway立即返回任务ID,Agent后台处理,完成后通过Webhook通知
产品建议:
客服场景 → 同步模式,用户体验优先 数据分析、报告生成 → 异步模式,避免超时
决策2:会话管理
Gateway维护session_id,确保多轮对话的上下文连续性:
{"session_id": "sess_abc123","user_id": "user_456","message": "上个月的销售数据怎么样?","context": {"last_query_time": "2025-03-15T10:30:00Z","conversation_turns": 3 }}2.4 产品实践建议
场景1:多租户SaaS产品
为不同企业客户提供Agent服务,Gateway负责:
租户隔离(数据不串户) 差异化配额(企业版 vs 免费版) 个性化路由(VIP客户使用更强算力)
场景2:灰度发布
通过Gateway实现A/B测试:
# 10%的用户使用新版Agent,90%使用稳定版if user_id % 10 == 0: route_to("agent_v2")else: route_to("agent_v1")三、Memory:Agent的记忆系统
3.1 产品视角:记忆的三个层次
AI Agent的记忆不是简单的"记住聊天记录",而是分为三个层次:
短期记忆(Short-term Memory)
生命周期:当前会话 作用:理解上下文,避免用户重复说明 示例:"把刚才那个表格发给我" → Agent知道"刚才那个"是指3分钟前生成的销售报表
长期记忆(Long-term Memory)
生命周期:跨会话,永久保存 作用:记住用户偏好、历史交互 示例:用户上次要求"每周一早上9点发送周报" → 下周一自动执行
工作记忆(Working Memory)
生命周期:当前任务 作用:执行复杂任务时的中间状态 示例:分析100页PDF时,记住已处理到第37页
3.2 技术实现:Memory的存储架构
┌─────────────────────────────────────────────────┐│ Memory Interface ││ (统一的读写API,隐藏底层存储细节) │└─────────────────────────────────────────────────┘ │ │ │ ┌────┴───┐ ┌────┴────┐ ┌─────┴─────┐ │ Cache │ │ Vector │ │ Relational│ │ (Redis)│ │ Store │ │ DB (PG) │ └────────┘ └─────────┘ └───────────┘ ↑ ↑ ↑ 短期记忆 语义记忆 结构化记忆为什么需要三种存储?
| Redis缓存 | ||
| 向量数据库 | ||
| 关系数据库 |
3.3 核心能力:检索增强生成(RAG)
这是Memory最重要的功能——让Agent能够基于历史知识回答问题。
典型流程:
用户提问:"去年Q4的营收增长率是多少?" ↓1. 向量化问题 → embedding_query ↓2. 在向量库中检索最相关的3条历史记录 - "2025年Q4财报.pdf" (相似度: 0.92) - "2025年全年总结.docx" (相似度: 0.85) - "Q4销售数据.xlsx" (相似度: 0.78) ↓3. 把检索到的内容 + 原始问题一起发给LLM ↓4. LLM基于真实数据生成答案:"23.5%,主要由..."3.4 产品设计要点
要点1:遗忘机制
不是所有记忆都要永久保存。OpenClaw支持配置遗忘策略:
memory_policy:short_term:ttl:3600# 1小时后自动清理long_term:retention_days:90# 90天后归档working:max_size:100# 最多保留100条中间状态要点2:隐私合规
记忆系统必须支持:
用户数据删除:GDPR要求的"被遗忘权" 敏感信息脱敏:自动识别并隐藏身份证、银行卡号 访问审计:记录谁在何时访问了哪些记忆
要点3:记忆质量评估
建立指标体系评估记忆是否有效:
召回率:Agent能找到多少相关历史信息 准确率:检索到的信息有多少真正有用 时效性:是否优先使用最新的信息
四、Skills:Agent的能力工具箱
4.1 产品视角:Skills vs Plugins
很多人容易混淆Skills和Plugins,用一个类比说明:
Plugins(插件):像手机App,需要安装、配置,功能相对独立 Skills(技能):像人的能力,可以随时调用,相互组合
示例:
需求:"帮我预定明天下午3点的会议室,并邀请张三和李四"调用技能链:1. calendar_skill.check_availability("tomorrow 3pm")2. room_booking_skill.reserve(room_id, time)3. email_skill.send_invitation(recipients, meeting_info)4.2 Skill的标准化定义
OpenClaw使用JSON Schema定义Skill:
{"name": "query_database","description": "从数据库查询销售数据","parameters": {"type": "object","properties": {"table": {"type": "string","description": "表名","enum": ["sales", "customers", "products"] },"filters": {"type": "object","description": "筛选条件" },"date_range": {"type": "object","properties": {"start": {"type": "string", "format": "date"},"end": {"type": "string", "format": "date"} } } },"required": ["table"] },"returns": {"type": "array","description": "查询结果列表" }}为什么要这么详细?
因为LLM需要根据description和parameters决定何时调用、如何传参。定义越清晰,Agent的决策就越准确。
4.3 Skill的生命周期管理
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐│ 注册阶段 │ → │ 发现阶段 │ → │ 执行阶段 │ → │ 监控阶段 │└──────────┘ └──────────┘ └──────────┘ └──────────┘ ↓ ↓ ↓ ↓ 定义Schema Agent选择合适 传参并调用 记录成功率 配置权限 的Skill使用 处理返回值 追踪耗时 版本管理 错误处理 异常告警4.4 企业级Skill设计模式
模式1:Skill组合(Skill Chaining)
单个Skill职责单一,通过组合实现复杂功能:
任务:"生成上月销售报告并发送给CEO"Skill链:1. data_query_skill → 查询原始数据2. data_analysis_skill → 计算指标3. report_generation_skill → 生成PDF4. email_skill → 发送邮件模式2:条件分支(Conditional Branching)
if customer_value > 10000: use_skill("vip_service")else: use_skill("standard_service")模式3:并行执行(Parallel Execution)
任务:"同时查询销售、库存、物流三个系统的数据"并行调用:- sales_skill.query() - inventory_skill.query()- logistics_skill.query()等待全部完成后汇总结果4.5 Skill安全性考量
权限控制:不是所有Agent都能调用所有Skill
skill:delete_customer_dataallowed_roles:-admin-data_managerapproval_required:true# 需要人工审批audit_log:true# 记录所有调用速率限制:防止Skill被滥用
@rate_limit(calls=10, period=60) # 每分钟最多10次defexpensive_api_call():pass五、Subagent:专业化分工协作
5.1 产品视角:为什么需要Subagent?
单一Agent就像一个"全能员工",什么都会但什么都不精。Subagent架构把复杂任务拆解给多个专业Agent:
示例:智能客服系统
┌─────────────────────────────────────────┐│ Master Agent (总调度) ││ "用户想要退货并查询物流" │└─────────────────────────────────────────┘ │ ├─→ Intent_Agent (意图识别) │ └─ 识别出:退货请求 + 物流查询 │ ├─→ Order_Agent (订单专家) │ └─ 检查订单状态,发起退货流程 │ └─→ Logistics_Agent (物流专家) └─ 查询快递信息,预估退货时间5.2 Subagent的通信机制
方式1:消息传递(Message Passing)
{"from": "master_agent","to": "order_agent","task": {"type": "refund_request","order_id": "ORD-2025-001","reason": "质量问题" },"callback": "master_agent/receive_result"}方式2:共享内存(Shared Memory)
多个Subagent读写同一个Memory空间,实现状态共享:
Task State in Memory:{"task_id": "T-001","status": "in_progress","assigned_agents": ["order_agent", "logistics_agent"],"results": {"order_agent": {"refund_initiated": true},"logistics_agent": {"pickup_scheduled": "2025-03-20"} }}5.3 协作模式
模式1:Pipeline(流水线)
任务按顺序经过多个Subagent:
用户上传简历 → Resume_Parser_Agent → Info_Extraction_Agent → Matching_Agent → Recommendation_Agent → Email_Agent模式2:Hierarchical(层级式)
CEO_Agent │ ┌────────┼────────┐ Sales Product Support Agent Agent Agent │ │ │ ┌──┴──┐ ┌─┴─┐ ┌──┴──┐ 区域A 区域B 功能A 功能B 一线 二线模式3:Swarm(蜂群式)
多个平等的Agent自组织协作:
10个Research_Agent同时搜集信息→ 自动去重、交叉验证→ 投票决定最可信的答案5.4 关键技术挑战
挑战1:任务分解
Master Agent如何把"写一份市场分析报告"拆解成具体子任务?
OpenClaw的做法:使用Planning模块,先让LLM生成执行计划:
{"task": "市场分析报告","plan": [ {"step": 1,"description": "收集行业数据","assigned_to": "data_collection_agent","dependencies": [] }, {"step": 2,"description": "竞品分析","assigned_to": "competitor_analysis_agent","dependencies": [1] }, {"step": 3,"description": "SWOT分析","assigned_to": "analysis_agent","dependencies": [1, 2] } ]}挑战2:冲突解决
两个Subagent给出矛盾的建议怎么办?
投票机制:多数服从 优先级机制:领域专家的意见权重更高 人工介入:关键决策仍需人类确认
挑战3:成本控制
多个Agent同时运行,LLM调用成本飙升怎么办?
# 根据任务优先级分配计算资源if task.priority == "high": use_model = "gpt-4"elif task.priority == "medium": use_model = "gpt-3.5-turbo"else: use_model = "local_llm"# 使用本地开源模型六、Runtime:Agent的运行时环境
6.1 产品视角:Runtime解决什么问题?
如果说前面四个组件是"功能设计",Runtime就是"生产环境保障":
稳定性:Agent出错了怎么办?如何自动重试? 可观测性:任务卡在哪一步了?为什么失败? 安全性:如何防止Agent执行危险操作? 扩展性:并发100个用户请求时如何不崩溃?
6.2 Runtime的核心模块
┌────────────────────────────────────────────────┐│ Orchestrator (编排引擎) ││ - 任务调度 ││ - 资源分配 ││ - 优先级管理 │└────────────────────────────────────────────────┘ ↓┌────────────────────────────────────────────────┐│ Execution Engine (执行引擎) ││ - Skill调用 ││ - Subagent协调 ││ - 状态机管理 │└────────────────────────────────────────────────┘ ↓┌────────────────────────────────────────────────┐│ Monitoring & Logging (监控日志) ││ - 实时追踪 ││ - 性能指标 ││ - 异常告警 │└────────────────────────────────────────────────┘6.3 错误处理与重试机制
策略1:指数退避重试
defexecute_with_retry(skill, max_retries=3):for attempt in range(max_retries):try:return skill.execute()except TemporaryError as e: wait_time = 2 ** attempt # 1s, 2s, 4s time.sleep(wait_time)# 3次都失败后,降级处理return fallback_response()策略2:断点续传
复杂任务执行到一半失败,不用从头开始:
{"task_id": "report_generation_T001","checkpoint": {"completed_steps": [1, 2, 3],"current_step": 4,"step_4_progress": "60%" },"resume_from": "step_4"}6.4 安全沙箱机制
防止Agent执行危险操作:
沙箱规则:
sandbox_policy:allow:-read_file(path="/data/allowed/*")-api_call(domain="*.company.com")deny:-write_file(path="/etc/*")# 禁止修改系统文件-execute_shell(commandcontains"rm -rf")-api_call(domain="*.competitor.com")require_approval:-send_email(recipientcontains"@external.com")-database_write(table="financial_data")实际案例:
某企业的AI Agent在测试时,意外生成了一个删除数据库的SQL语句。Runtime的沙箱机制检测到危险操作,自动拦截并告警,避免了数据灾难。
6.5 可观测性:Tracing与Monitoring
分布式追踪:
Request ID: REQ-2025-03-16-001├─ Gateway: 120ms├─ Master Agent: 450ms│ ├─ Memory Retrieval: 80ms│ ├─ Planning: 200ms│ └─ Subagent Coordination: 170ms│ ├─ Order Agent: 90ms│ └─ Logistics Agent: 80ms└─ Response: 50msTotal: 620ms关键指标监控:
| P95延迟 | ||
| 错误率 | ||
| Token消耗 | ||
| 并发数 |
6.6 弹性伸缩
**场景:**电商大促期间,客服Agent的请求量是平时的10倍。
Runtime的应对:
# 自动扩容规则if current_qps > 1000and cpu_usage > 70%: scale_up(instances=current_instances * 2)# 缩容规则if current_qps < 200and cpu_usage < 30%: scale_down(instances=max(current_instances // 2, min_instances))七、五大组件的协同工作
现在,让我们用一个完整案例,看五大组件如何协同运作:
场景:智能财务分析Agent
用户请求:"分析我司上季度的费用支出,找出异常项并给出优化建议"
完整执行流程:
1️⃣ Gateway接收请求 - 验证用户身份(财务部门权限) - 创建session_id: SESS-001 - 路由到Finance_Master_Agent2️⃣ Memory激活 - 检索用户历史:"上次关注的是差旅费异常" - 加载公司财务规则库 - 获取上季度的数据访问权限3️⃣ Master Agent制定计划 调用Planning_Skill,生成任务拆解: - Task1: 数据收集 - Task2: 异常检测 - Task3: 根因分析 - Task4: 生成建议4️⃣ 派发给Subagents ├─ Data_Agent: 调用ERP_Skill获取费用明细 ├─ Analysis_Agent: 调用Anomaly_Detection_Skill └─ Report_Agent: 调用Report_Generation_Skill5️⃣ Runtime协调执行 - 监控各Subagent进度 - Data_Agent完成后,通知Analysis_Agent - 检测到Analysis_Agent超时,自动重试 - 记录全流程Trace6️⃣ 结果整合与返回 - 汇总各Subagent的输出 - Memory存储本次分析结果 - Gateway将报告推送给用户 - 发送"分析完成"的企业微信通知耗时分解:
Gateway: 50ms Memory检索: 200ms Planning: 300ms Subagents并行执行: 2.5s 结果整合: 150ms 总计: 3.2秒
八、产品经理的实战建议
8.1 如何评估Agent产品的成熟度?
用这5个维度给你的Agent产品打分:
| Gateway | |||
| Memory | |||
| Skills | |||
| Subagent | |||
| Runtime |
8.2 常见的产品设计误区
❌ 误区1:追求全能Agent
✅ 正确做法:让每个Subagent专精一个领域,通过协作解决复杂问题
❌ 误区2:忽视Memory的成本
向量检索、长期存储都要花钱。一个用户一年的Memory成本可能高达数百元。
✅ 正确做法:设计合理的遗忘策略,只保留真正有价值的记忆
❌ 误区3:Skills越多越好
Skills太多会导致Agent"选择困难",调用错误的概率大增。
✅ 正确做法:控制在20-30个高质量Skill,通过组合实现扩展
❌ 误区4:过度依赖LLM
不是所有逻辑都要让LLM决策,简单的if-else用规则引擎更快更便宜。
✅ 正确做法:LLM负责理解和生成,确定性逻辑用传统代码
九、对产品经理的技能要求
必备能力:
系统思维:理解分布式系统的基本原理 Prompt工程:会写高质量的Agent指令 数据敏感:用指标驱动产品迭代 成本意识:LLM调用、存储都是真金白银
十、写在最后
OpenClaw的五大组件,本质上是对"如何构建可靠的AI Agent"这个问题的系统性回答:
Gateway → 让Agent接入真实世界 Memory → 让Agent拥有记忆和知识 Skills → 让Agent具备实际能力 Subagent → 让Agent能处理复杂任务 Runtime → 让Agent稳定可靠地运行
结语
我在用Openclaw测试实例,40+场景。知识星球中有相关教程。
👇 点赞 + 在看,你的支持是我更新的动力
AI产品经理VIP社群↓
福利
关注我们,点赞+转发本篇文章
《AI产品经理-算法协作实战手册》PDF,包含:✅ 目标对齐工作坊模板✅ 技术链路共绘白板图(含RAG/Agent/推荐系统)✅ 数据闭环搭建 checklist✅ 常见协作冲突应对话术
关注我们,获取更多AI技术干货与职业成长指南与资料!
猜你喜欢


#AI Agent #OpenClaw #大模型 #AI产品经理 #AIGC #智能体 #企业AI #OpenAI #AgentOS
✨ 3秒操作,锁定价值:1️⃣ 点击公众号主页右上角「…」2️⃣ 选择「设为星标」⭐完成!从此不再错过任何一篇精彩内容。
