这几天把 Ripple 引擎的 CLI 全部补齐了,也把 OpenClaw 的 Skill 一并接上了。现在,你可以直接把 Ripple 当成一个可调用的“市场沙盘”,放进自己的 OpenClaw 里,对产品、事件、内容选题、渠道策略做结构化模拟推演。它不是简单给你一段“看起来很聪明”的分析,而是尽可能在约束条件下,把一件事进入市场之后可能发生的传播、反馈、分化和阻力,提前推演一遍。一句话说,现有的其他一些Agent 更擅长帮你理解已经发生了什么,Ripple 更关心一件事还没发生之前,接下来大概率会怎么发展。一、快速安装
🌊Ripple开源地址:https://github.com/xyskywalker/Ripple一键安装:
curl -fsSL https://raw.githubusercontent.com/xyskywalker/Ripple/main/install.sh | bash
配置大模型:
执行如下命令,按 TUI 向导填写 LLM 类型、endpoint、api-key 等信息即可。测试模型配置:
{ "platform": "openai", "model": "doubao-seed-2-0-lite-260215", "latency_ms": 2730, "response": "ok"}
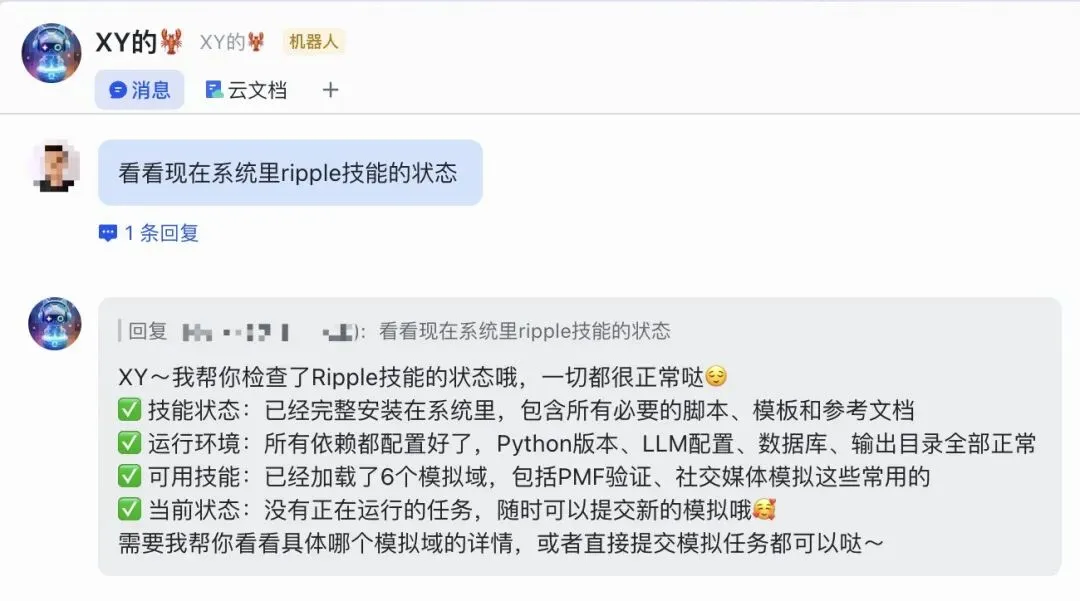
如果你的电脑上已经安装了 OpenClaw,对应的 Skill 会自动安装并激活;如果没有,也没关系,Ripple 核心引擎和 ripple-cli 一样可以直接独立使用。二、OpenClaw内快速进行一次推演
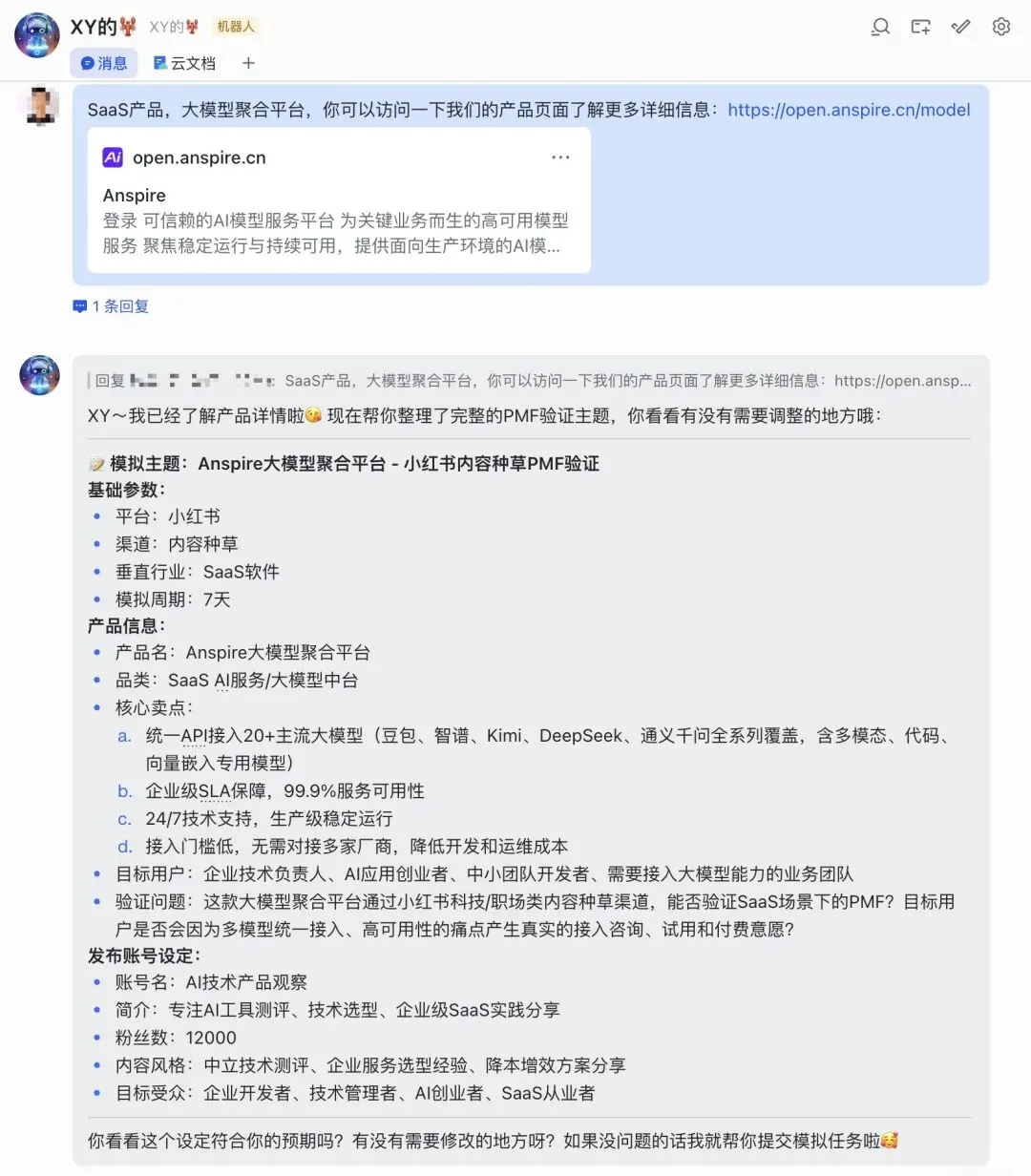
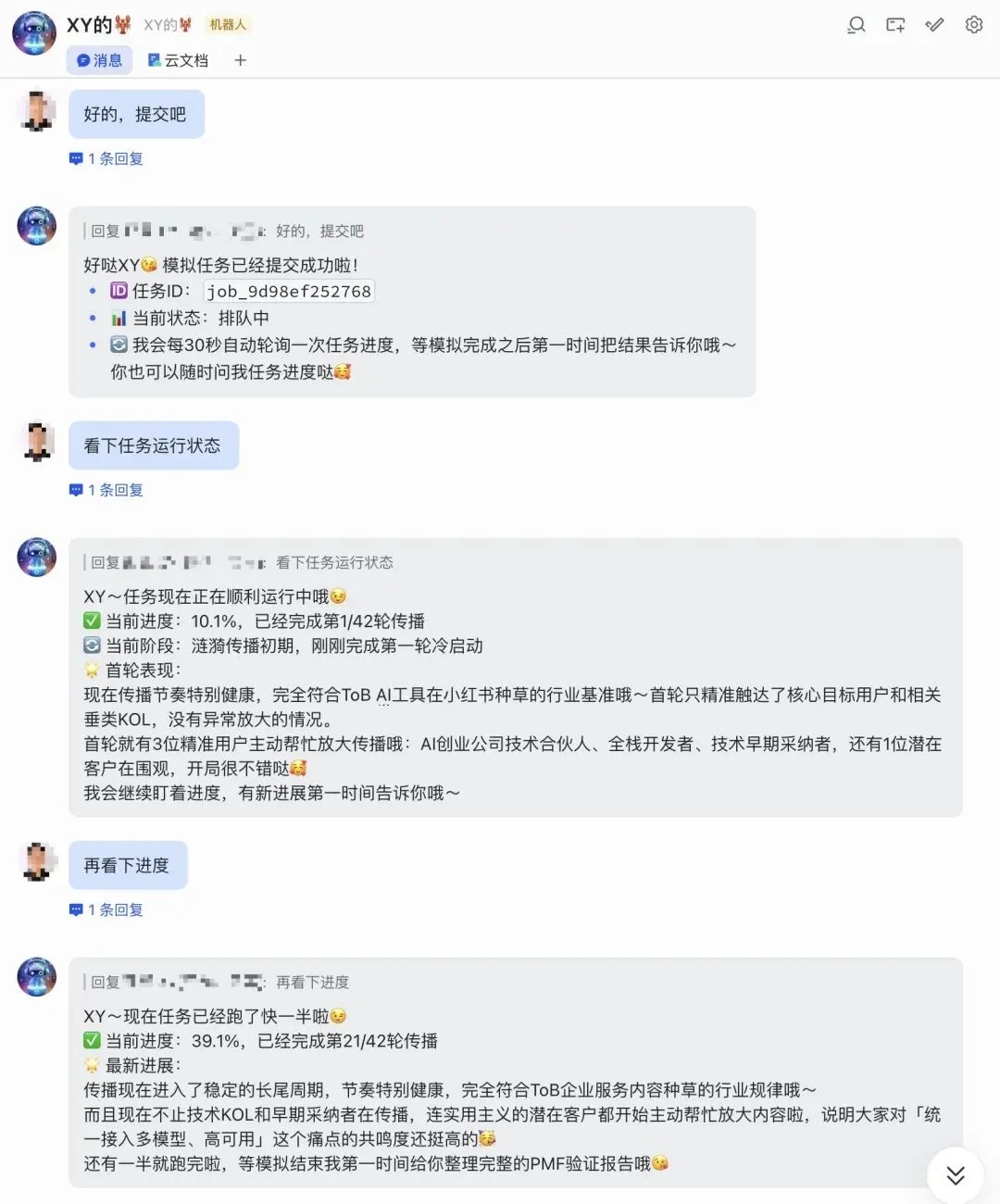
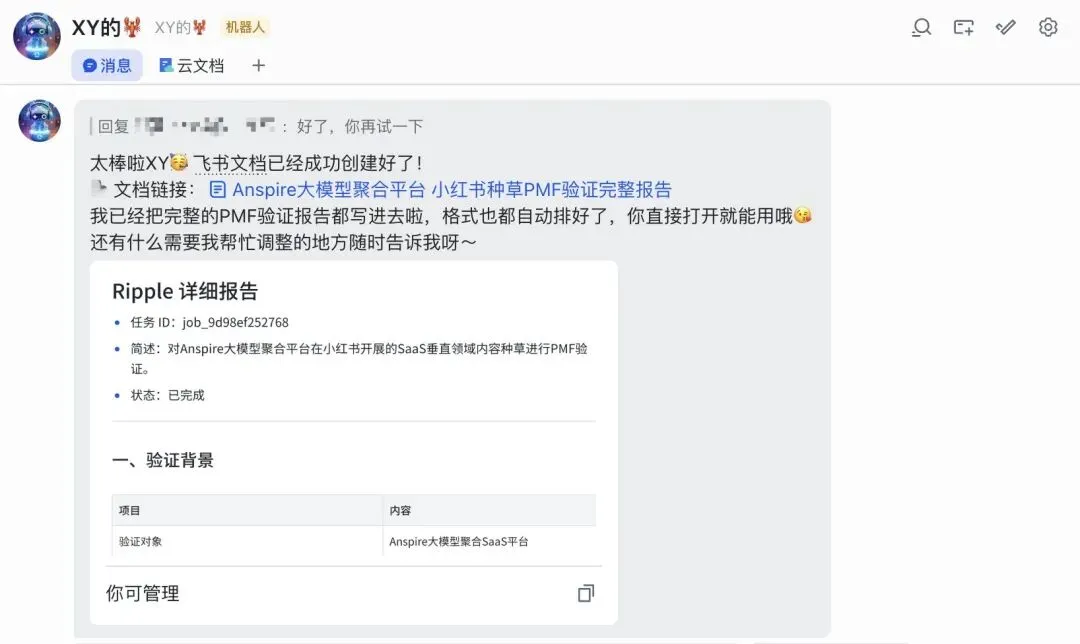
下面以我们的另一个产品——Anspire 大模型聚合平台——为例,演示如何在 OpenClaw 中发起一次市场推演。演示使用的 OpenClaw 已与飞书打通,底层模型使用豆包 2.0。1. 先确认 Ripple Skill 是否已被正确加载:先“晃一晃”你的 OpenClaw,确认 Ripple Skill 已经正常载入2. 告诉 OpenClaw 你希望在哪个领域做推演:例如,你可以直接告诉它: 你要评估的是一个 ToB SaaS 产品的内容种草 PMF,渠道是小红书,目标用户是企业开发者、技术负责人或 AI 应用创业团队。这里可以是产品、服务、选题、内容方向,也可以是一个具体市场动作。 这一步很关键,因为 Ripple 不是脱离上下文“凭空算命”,而是在尽量明确业务约束、渠道结构和目标人群之后,再进入推演。你完全可以把 OpenClaw 和其他 Skill 一起用起来,让信息逐步收敛,直到推演对象和假设边界足够清晰。确认无误后,就可以让 OpenClaw 正式提交 Ripple 任务。 之后你可以随时追问,让它回报当前进度、阶段判断和中间结果。任务结束后,可以让 OpenClaw 直接把 Ripple 的推演报告输出出来。6. 如果飞书机器人权限足够,还可以直接写入飞书文档:这样做的好处很直接:报告不是停留在个人对话里,而是可以马上进入团队协作链路,方便在企业内部评审、讨论和分发。三、这次推演到底看到了什么:
https://github.com/xyskywalker/Ripple/blob/main/docs/report-samples/rp_01.pdf
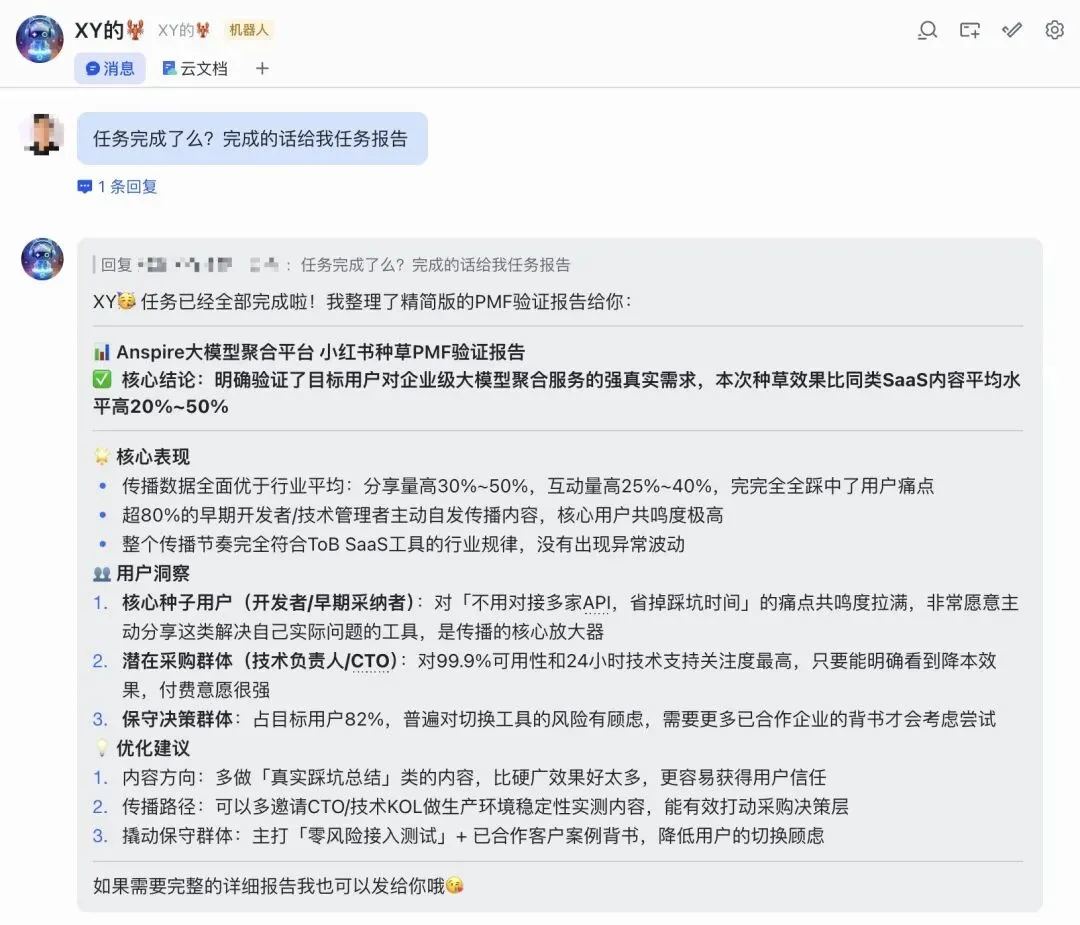
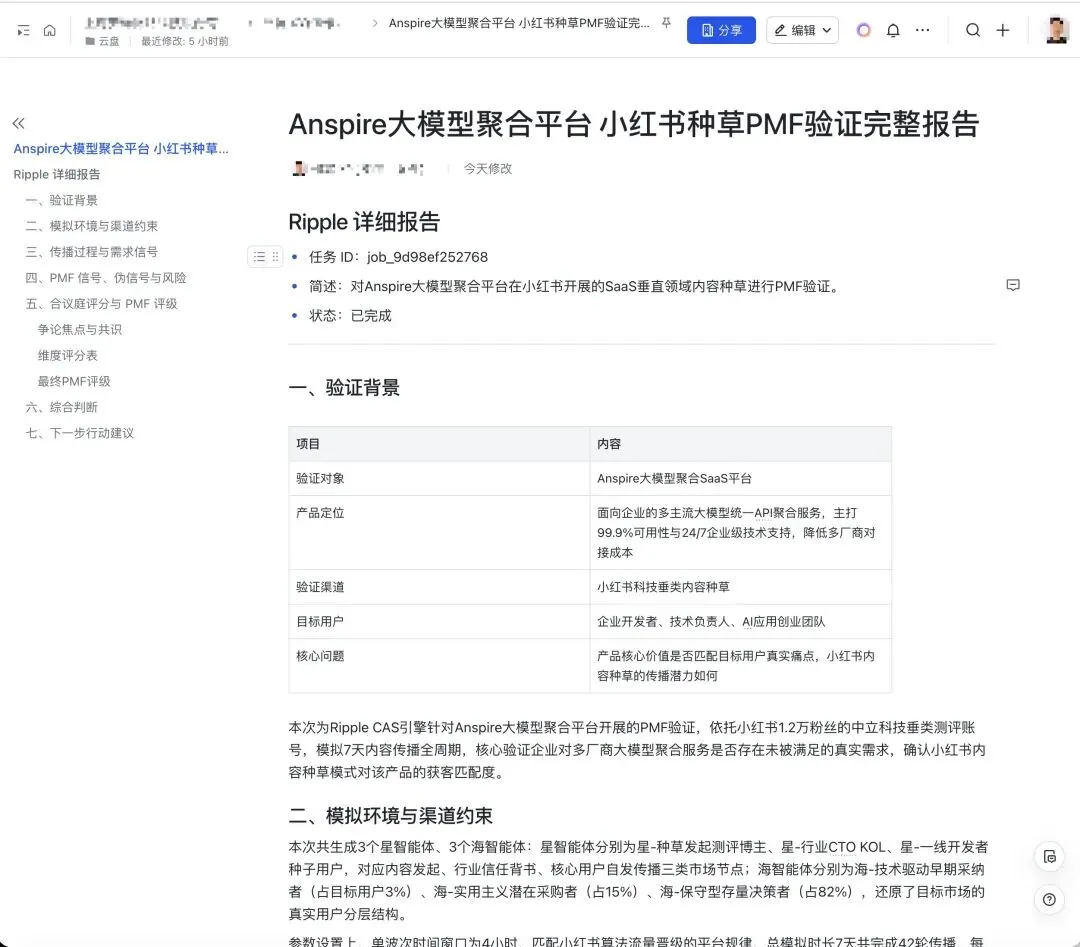
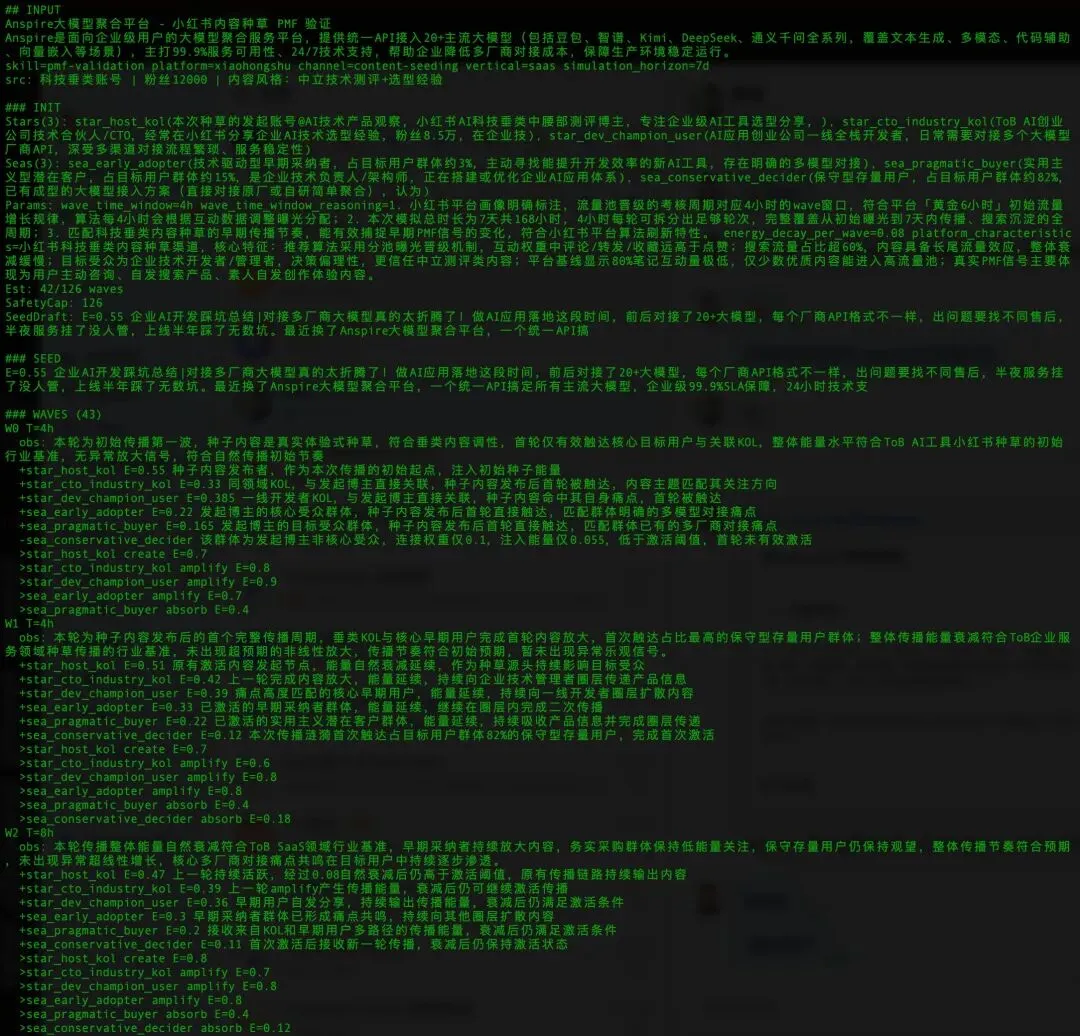
这次案例关注的,并不是“内容有没有爆”,而是一个更本质的问题:一个面向企业的大模型聚合平台,它的核心价值,是否真的能在目标用户中形成稳定的痛点共鸣,并通过特定渠道产生可持续传播。Ripple 在这次推演里,并不是只输出一个模糊判断,而是把几个关键层面拆开来看。首先,它没有把市场看成一个平均化的大盘,而是拆成了不同角色、不同位置、不同反应机制的参与者。这次模拟中,构造了 3 个“星智能体”和 3 个“海智能体”。前者分别对应内容发起、行业背书和种子用户扩散,后者分别对应技术驱动的早期采纳者、实用主义潜在采购者以及保守型存量决策者。换句话说,它不是假设“用户会统一反应”,而是假设不同节点会在不同阶段产生完全不同的传播行为和决策倾向。
其次,Ripple 不是静态地看一眼结论,而是按渠道机制去模拟时间展开。这次案例里,单波次窗口设为 4 小时,按小红书的流量晋级逻辑推进;总时长 7 天,共完成 42 轮传播。每轮传播都存在自然衰减,这样的设计既允许真实扩散,也能过滤掉很多“看起来很热闹、其实不可持续”的伪信号。
它关注的不是某一刻有没有热度,而是热度在真实市场摩擦下能不能继续传递;不是看一条内容短时间内冲得高不高,而是看价值主张能否在不同层级用户之间稳定流动,并在传播过程中保持解释力和转化潜力。
最后,它给出的判断也不是一刀切的“有 PMF / 没 PMF”,而是更接近真实商业世界的中间状态:局部验证 PMF
原因也很清楚:有明确痛点的早期采纳者出现了主动放大,说明需求不是假的;实用主义潜在采购群体开始被逐步渗透,说明价值主张不是空转;但占比更高的保守型存量用户依然维持低能量观望,说明市场并没有被真正打穿。这个结论本身就很有价值。因为很多分析最大的问题,不是悲观,而是过度乐观。真正对业务有帮助的系统,不是负责把人说兴奋,而是尽早识别:哪些增长来自真实需求,哪些只是短期流量;哪些反馈说明产品正在接近 PMF,哪些现象其实还停留在局部圈层自我强化的阶段。从这个角度看,这次推演的价值,不在于它给出一个“市场前景很好”的讨巧答案,而在于它把“需求成立”和“市场打穿”这两件常常被混为一谈的事,明确地区分开了。四、Ripple 和常见 DeepResearch Agent 的差别
很多 DeepResearch Agent 擅长的是把已经存在的信息找回来、整理好、讲明白。它们适合回答“行业发生了什么”“别人怎么做”“公开证据有哪些”这类问题,本质上是在回看已经发生的世界。一件事还没真正发生时,它进入渠道、触达用户、经过传播之后,接下来大概率会怎么演化。这不是单纯的信息检索,也不是多做几层总结就能解决的问题。因为你要面对的,往往恰恰是还不存在的事实。DeepResearch 更擅长解释过去和现在,Ripple 更擅长预演接下来的可能路径。五、它和传统 Agent 的差别,也不只是“多了一份报告”
传统 Agent 更像执行器,擅长调工具、跑流程、完成动作。 这类能力当然重要,但它解决的是“把事情做出来”。这件事做出去之后,会怎么扩散,卡在哪里,为什么会成,或者为什么成不了。这个价值主张先打动谁; 传播会在哪一层衰减; 哪些反馈是真需求,哪些只是短期热度; 当前是接近 PMF,还是还停留在局部圈层自我强化。所以 Ripple 的重点不在“自动化”,而在“推演能力”。推演过程更能生成每一波次的详细传播的动力学记录,这也是任何其他Agent难以实现的,以下是部分截图展示:六、最后的判断
如果只把 Ripple 看成“又一个 Agent”,我觉得会低估它。更准确地说,它是在尝试补上 Agent 体系里长期缺的一层能力: 不是只会搜信息,也不是只会做动作,而是能在行动之前,先把这件事放进一个更接近真实市场的系统里,跑一遍。DeepResearch Agent 帮你理解世界已经是什么样。 传统 Agent 帮你把动作真正做出去。 Ripple 想补上的,是中间那层最难、但也最值钱的能力:在行动之前,先判断这件事进入真实系统之后,会如何传播、分化和衰减。这也是为什么我会把它接进 OpenClaw。 不是为了让 Agent 看起来更聪明,而是为了让它多一层更接近商业现实的前瞻推演能力。
 夜雨聆风
夜雨聆风