 夜雨聆风
夜雨聆风OpenClaw 提供了灵活的记忆架构:从开箱即用的 Markdown 文件系统,到功能完备的 OpenViking 记忆引擎。两种方案各有侧重,适合不同的场景。
这篇文章会深入解析:
OpenClaw 默认的 Memory 机制 Memory-Search 的构建原理 OpenViking 记忆系统的工作方式 Telos + Obsidian 的目的驱动框架 三种方案的对比与选择
一、默认 Memory 机制:Markdown 即记忆
OpenClaw 的核心理念:文件即记忆。
不需要数据库,不需要复杂配置。记忆就是工作区里的 Markdown 文件。
1.1 两层结构
~/.openclaw/workspace/├── MEMORY.md # 长期记忆(curated)└── memory/ ├── 2026-03-12.md # 今日日志 ├── 2026-03-11.md # 昨日日志 └── ...MEMORY.md:存放需要长期记住的信息。
用户的偏好、习惯 重要的决策和理由 关键的项目背景
memory/YYYY-MM-DD.md:存放日常笔记。
当天发生的事 临时的上下文 对话的流水账
两层分离的设计,让 Agent 既有"长期记忆"(不会忘记),又有"短期记忆"(每天刷新)。
1.2 自动加载策略
Agent 在每个 session 开始时:
读取 MEMORY.md(仅在主会话中,群组聊天不加载) 读取 今天 + 昨天的 daily log
这个策略很克制:不会加载所有历史,只加载最近两天的上下文。
原因很简单:token 有成本,历史越长,成本越高。
1.3 自动记忆刷新
这是 OpenClaw 的一个巧妙设计。
当 session 接近自动压缩(compaction)时,系统会触发一个静默的 agent turn:
"Session nearing compaction. Store durable memories now."
Agent 会被提醒:把重要的东西写进 memory 文件,然后再压缩上下文。
这样即使 session 被压缩,记忆也不会丢失。
{ agents: { defaults: { compaction: { memoryFlush: { enabled: true, softThresholdTokens: 4000, prompt: "Write lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing." } } } }}1.4 为什么选择 Markdown?
- 人类可读
你可以直接打开文件查看、编辑 - 版本控制友好
用 Git 追踪记忆的变化 - 工具生态丰富
Obsidian、VS Code 都能直接编辑 - 无 vendor lock-in
你的记忆不属于任何平台
这是一种 "透明记忆" 的设计哲学。
二、Memory-Search:让记忆可搜索
Markdown 文件是存储层。但要找到相关记忆,需要检索层。
OpenClaw 提供了 memory_search 工具,支持语义搜索。
2.1 向量搜索原理
将每个 memory 文件切分成 chunks(~400 tokens),然后:
调用 embedding API,将每个 chunk 转成向量 存储在本地 SQLite 中 查询时,将 query 也转成向量,计算相似度
Query: "我喜欢什么咖啡?" │ ▼ Embedding[0.12, -0.34, 0.56, ...] │ ▼ 相似度计算┌─────────────────────────────────────┐│ MEMORY.md#L10-L15 score: 0.89 ││ "咖啡偏好:手冲,浅烘焙..." │├─────────────────────────────────────┤│ memory/2026-03-10.md#L5-L8 0.72 ││ "今天在 Blue Bottle 买了..." │└─────────────────────────────────────┘2.2 混合搜索:向量 + BM25
纯向量搜索有个问题:对精确关键词不敏感。
比如搜索一个具体的 API key 或 ID,向量搜索可能找不到。
OpenClaw 的解决方案:混合搜索。
Final Score = 0.7 × VectorScore + 0.3 × BM25Score- 向量搜索
擅长语义匹配("我喜欢的咖啡" vs "咖啡偏好") - BM25 关键词搜索
擅长精确匹配("a828e60" 这种 ID)
两者结合,既理解意图,又不错过细节。
2.3 MMR 去重与时序衰减
两个高级特性,让搜索结果更智能。
MMR(Maximal Marginal Relevance):减少重复结果。
查询:"家庭网络配置"不用 MMR:1. memory/2026-02-10.md - "配置了 Omada 路由器..."2. memory/2026-02-08.md - "配置了 Omada 路由器..."(几乎一样!)3. memory/network.md - "路由器配置汇总"用 MMR(λ=0.7):1. memory/2026-02-10.md - "配置了 Omada 路由器..."2. memory/network.md - "路由器配置汇总"(多样性提升!)3. memory/2026-02-05.md - "设置了 AdGuard DNS..."时序衰减:新记忆优先。
Score = RawScore × e^(-λ × ageInDays)半衰期 30 天:- 今天的笔记:100%- 7 天前:84%- 30 天前:50%- 90 天前:12.5%这样,过时的信息不会淹没最新的上下文。
2.4 Embedding 提供商选择
OpenClaw 支持多种 embedding 方案:
| OpenAI | ||
| Gemini | ||
| Voyage | ||
| Mistral | ||
| Ollama | ||
| Local |
请在微信客户端打开
三、OpenViking:Agent-Native 记忆引擎
当记忆需求变得复杂,Markdown 文件可能不够用。
OpenViking 是字节跳动开源的 Agent-native context database,专为 AI Agent 设计。
3.1 架构设计
OpenViking 的核心概念:
viking://user/memories/ # 用户级记忆viking://agent/memories/ # Agent 级记忆viking://agent/skills/ # Agent 技能viking://agent/instructions/ # Agent 指令两层 scope:
- user scope
跨 Agent 共享的用户记忆 - agent scope
特定 Agent 的私有记忆
这种设计支持多 Agent 场景:每个 Agent 有自己的记忆空间,同时共享用户的偏好信息。
3.2 自动捕获与召回
OpenViking 插件提供了两个核心功能:
Auto-Capture:对话结束后自动提取记忆。
User: "我明天要去上海出差"Agent: "好的,需要我帮你查航班吗?" │ ▼ Auto-CaptureSession → Memory Extraction │ ▼ 生成记忆- [events] 明天去上海出差- [preferences] 可能偏好航班查询服务Auto-Recall:每次对话前自动检索相关记忆。
User: "明天的行程是什么?" │ ▼ Auto-RecallQuery: "明天 行程" │ ▼ 匹配记忆[viking://user/memories/events/xxx] "明天去上海出差" │ ▼ 注入上下文<relevant-memories>- [events] 明天去上海出差</relevant-memories>3.3 记忆层级结构
OpenViking 的记忆是树状结构:
viking://user/memories/├── preferences/│ ├── coffee.md # 咖啡偏好│ └── travel.md # 旅行偏好├── events/│ ├── 2026-03-12-shanghai.md # 明天的出差│ └── 2026-03-05-birthday.md # 朋友的生日└── relationships/ ├── alice.md # Alice 的信息 └── bob.md # Bob 的信息每个节点有三个层级:
- Level 0
根节点(memories) - Level 1
分类节点(preferences、events) - Level 2
叶子节点(具体的记忆文件)
检索时,系统优先返回叶子节点(level 2),因为那是最具体的信息。
3.4 记忆排名算法
OpenViking 插件实现了智能的排名算法:
// 伪代码function rankMemory(item, query) { let score = item.semanticScore; // 语义相似度 // 叶子节点加分 if (item.level === 2) score += 0.12; // 时间相关查询 + 事件记忆加分 if (query.hasTemporal && item.isEvent) score += 0.10; // 偏好相关查询 + 偏好记忆加分 if (query.hasPreference && item.isPreference) score += 0.08; // 词汇重叠加分 score += lexicalOverlap(query, item); return score;}这个算法让最相关的记忆排在前面。
四、Telos + Obsidian:目的驱动的记忆框架
在讨论 OpenClaw 默认 Memory 和 OpenViking 之外,还有另一种思路:Telos。
由 Daniel Miessler 创建,Telos 是一个"深度上下文框架"(Deep Context Framework),用于帮助任何实体——从个人到组织——表达他们的目的。
4.1 核心理念:SPQA
Telos 采用 SPQA 模型:
- S (Situation)
当前状态 - P (Purpose)
目的/使命 - Q (Questions)
关键问题 - A (Answers)
答案/策略
这个模型来自情报分析领域,用于组织复杂的信息层次。
4.2 结构化的记忆文件
Telos 定义了一个标准化的 Markdown 结构:
## MissionThe mission of [entity] is to [purpose].## Goals (G1 > G2 > G3...)- G1: 最高优先级目标- G2: 次高优先级目标## KPIs- K1: 关键指标 1- K2: 关键指标 2## Risk Register- R1: 风险 1- R2: 风险 2## Projects- P1: 项目 1 | 描述 | 优先级 | 负责人 | 状态每个目标的重要性递减:G1 的重要性是 G2 的 2 倍,G2 是 G3 的 2 倍,以此类推。
4.3 与 Obsidian 的结合
Telos 天然适合 Obsidian:
- 双向链接
Goals、Projects、People 之间可以相互链接 - 图谱视图
可视化目的与目标的关系 - 标签系统
快速分类和检索
4.4 Agent 如何使用 Telos
当 Agent 读取 Telos 文件后,它能理解:
用户问:"我应该优先做什么?"Agent 分析:├── Mission: "确保企业持续认证用户..."├── G1: "20% 市场份额" (最高优先级)├── 当前风险: R1 "安全团队人手不足 50%"└── 项目列表: WAF Install (Critical)...Agent 回答:"根据你的 Telos,当前最高优先级是完成 WAF 安装项目。"Telos 让 Agent 理解"为什么",而不只是"是什么"。
五、三方对比
5.1 核心维度
| 核心目标 | |||
| 存储方式 | |||
| 人类可读性 | |||
| 自动捕获 | |||
| 自动召回 | |||
| 多 Agent | |||
| 双向链接 | |||
| 目的推理 | |||
| 学习曲线 |
5.2 本质区别
默认 Memory / OpenViking 解决的是:
"我之前说过什么?"
Telos 解决的是:
"我为什么要做这件事?"
前者是回顾性记忆,后者是前瞻性目的。
六、如何选择?
场景 1:个人知识管理
如果你用 Obsidian 管理笔记,想要一个"AI 能理解的目的文件":
→ Telos + Obsidian
场景 2:AI 助手/聊天机器人
如果你想要一个能记住对话的 AI:
→ 默认 Memory 或 OpenViking
记忆量小用默认,记忆量大用 OpenViking。
场景 3:专业工作 Agent
如果你有一个负责特定领域的工作 Agent:
→ Telos(定义目的) + OpenViking(记录记忆)
场景 4:企业级多 Agent 系统
如果你有多个 Agent 协作:
→ OpenViking
组合使用
三种方案不是互斥的:
七、总结
AI Agent 的"记忆"正在分化成多个层次。
这不是设计上的巧合,而是需求驱动演进的结果。
7.1 为什么需要分层?
如果把所有记忆塞进一个"大池子",问题会层出不穷:
- 召回噪音
问"今天吃什么",却翻出三年前的饮食记录 - token 浪费
每次对话都加载全部历史,成本失控 - 优先级混乱
用户的长期偏好,被临时的聊天记录淹没 - 更新成本
修改一个偏好,要遍历所有相关对话
分层,本质上是"信息生命周期管理"。
不同类型的记忆,有不同的:
- 时效性
有些今天有用,有些十年有效 - 检索频率
有些每次都要,有些偶尔才用 - 更新频率
有些从不改变,有些每天都在变
7.2 四层记忆架构

7.3 各层职责详解
L0 上下文层:工作记忆的延伸
- 职责
承载当前任务相关的临时信息 - 生命周期:短(小时到天)
- 典型内容
"今天要完成 X" "刚才讨论的 Y 方案" "用户提到的临时需求" - 检索策略
时间窗口优先,默认只加载今天 + 昨天 - 更新方式
实时追加,定期归档或丢弃
L1 记忆层:语义化的经验库
- 职责
存储可复用的经验、事件、关系 - 生命周期
中(天到月) - 典型内容
"上周去了上海出差" "用户偏好 Python,不喜欢 JavaScript" "Alice 是用户的朋友,做 AI 研究" - 检索策略
语义相似度优先,按 query 动态召回 - 更新方式
对话后自动提取(Auto-Capture),持续积累
L2 偏好层:稳定的人格画像
- 职责
定义用户的核心偏好和长期背景 - 生命周期
长(月到年) - 典型内容
"咖啡偏好:手冲,浅烘焙" "工作风格:异步沟通,厌恶无效会议" "技术栈:TypeScript + React,不用 Vue" - 检索策略
全量加载(token 成本可控,内容精简) - 更新方式
手动编辑或重大决策后更新
L3 目的层:存在意义的表达
- 职责
回答"我为什么做这件事"的终极问题 - 生命周期
极长(年到十年) - 典型内容
Mission:存在的使命 Goals:分优先级的目标(G1 > G2 > G3...) KPIs:衡量成功的指标 Risks:需要关注的风险 - 检索策略
按需引用,涉及优先级决策时加载 - 更新方式
季度/年度复盘,或重大方向调整
7.4 层级间的交互逻辑
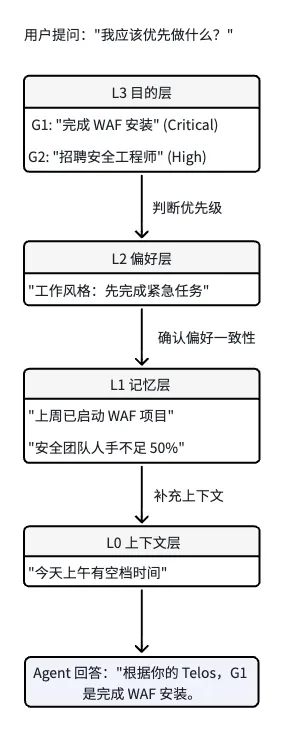
检索优先级:从上往下,越上层越"贵",但越关键。
L3:涉及重大决策才加载 L2:主会话默认加载 L1:按语义相似度动态召回 L0:按时间窗口优先
7.5 分层的本质:信息价值衰减 vs 复用价值提升
关键洞察:
L0 信息量大,但复用价值衰减快(今天的日志,下周就没用了) L3 信息量小,但复用价值持久(Mission 十年有效)
设计启示:
L0:需要压缩、裁剪、自动归档 L1:需要结构化、语义检索、自动提取 L2:需要精简、人类可编辑、稳定 L3:需要明确、层级化、关联决策
7.6 实践建议
延伸阅读
OpenClaw Memory 文档 OpenViking GitHub Telos GitHub
— 完 —
