 夜雨聆风
夜雨聆风很多人刚上手 OpenClaw,第一反应都是:
• 先接飞书、Telegram、微信这些渠道
• 再配模型
• 再研究 browser、exec、memory、subagent 这些工具
这些当然都重要。
但如果你真的开始把 OpenClaw 当成“长期搭档”来用,很快就会发现一个更关键的问题:
为什么同样一个模型,有的人调出来像得力助理,有的人调出来却像一个时灵时不灵的聊天机器人?
答案往往不在模型,而在工作区里那几份看起来不起眼、其实决定人格、边界、工作方式和记忆结构的 Markdown 文件。
我更愿意把它们统称为:OpenClaw 的灵魂套件。
它不是官方单独命名的产品模块,但从实战角度看,它就是把“通用大模型”调成“你的 AI 助手”的关键配置层。
今天这篇,我想把这件事彻底讲透:
• OpenClaw 的“灵魂套件”到底是什么
• 为什么它比你想象中更重要
• SOUL.md、AGENTS.md、IDENTITY.md、USER.md 分别该怎么理解
• 如果你想做一个真正稳定、能长期协作的 AI 助手,应该怎么配
一、为什么我说,OpenClaw 真正的门槛不在安装,而在“调魂”
会安装 OpenClaw,不难。
现在教程已经很多了,装环境、配渠道、接模型、起网关,愿意折腾的人基本都能搞定。
真正难的是另一件事:
你怎么让这个 AI 助手,越来越像“你想要的那个人”?
比如你希望它:
• 说话风格稳定,不要忽冷忽热
• 知道你是谁,不要每次都从零认识你
• 遇到敏感动作会先确认,不要自作主张
• 技术任务像技术合伙人,内容任务像主编,不要一股脑全都答成客服话术
• 长期使用后,不是越聊越乱,而是越用越顺手
这些都不是单靠换一个更贵的模型就能解决的。
你真正要做的,是给这个 Agent 一套稳定的“人格底座”和“工作机制”。
而 OpenClaw 最厉害的地方,就是它把这件事做成了文件层、工作区层,而不是只能靠你每次临时 prompt 去提醒。
二、所谓“灵魂套件”,核心到底是哪几份文件?
如果只看最核心的部分,我认为就是 4 件套:
• SOUL.md
• AGENTS.md
• IDENTITY.md
• USER.md
这四份文件,分别解决四个完全不同的问题。
1. SOUL.md:定义“你是谁,怎么说话,遇事怎么判断”
这是最像“灵魂核心”的一份文件。
官方文档里对 SOUL.md 的定位很直接:它管的是 persona、boundaries、tone,也就是人格、边界、语气。
说白了,它解决的是这些问题:
• 你这个助手说话是硬核直接,还是温和陪伴
• 你优先给结论,还是先铺背景
• 你在不确定的时候,是老老实实说不确定,还是容易脑补
• 你面对风险操作,是谨慎确认,还是容易越界
• 你看问题,是只从技术出发,还是会兼顾产品、传播、商业化
如果 SOUL.md 写得太空,比如只有一句“你是一个乐于助人的 AI”,那它几乎不会真正改变模型行为。
但如果它写得足够具体,模型每一轮都会被这份人格底板持续拉回正确方向。
所以很多时候,一个助手“有没有人味”“有没有判断力”,核心就看这份文件写得怎么样。
2. AGENTS.md:定义“你怎么工作,不是想怎么做就怎么做”
如果说 SOUL.md 决定气质,AGENTS.md 决定工作方式。
这份文件通常负责:
• 角色分工
• 任务路由
• 工作目录
• 安全规则
• 协作机制
• 哪类任务由哪个 Agent 处理
这在单 Agent 场景下,作用是“让它按规则做事”;在多 Agent 场景下,作用就更大了——它决定的是一整个 AI 团队如何分工。
比如你可以明确规定:
• Main 负责统筹
• Code 负责代码和部署
• Content 负责选题和文案
• 白名单目录内可直接操作
• 白名单外必须先确认
• 删除动作一律先确认
这种约束一旦写进 AGENTS.md,AI 的执行逻辑就会稳定很多。

它不再像一个“即兴发挥”的机器人,而更像一个遵守 SOP 的同事。
3. IDENTITY.md:定义“你叫什么,看起来像谁”
很多人会低估 IDENTITY.md。
但它其实很有用。
这份文件主要决定:
• 名字
• creature / 角色设定
• vibe / 整体气质
• emoji / 识别风格
别小看这个轻量文件。
当你的 Agent 长期出现在飞书、Telegram、Discord 等多个场景时,一个统一的身份外观,能显著减少“这个助手今天像 CTO,明天像实习生,后天又像客服”的割裂感。
它解决的是“外显一致性”。
不是最深层的逻辑,但对长期体验非常重要。
4. USER.md:定义“它服务的是谁”
很多人把 AI 调不顺,最大的问题不是没写人格,而是没写用户画像。
AI 知道自己是谁很重要,但更重要的是:它要知道自己在帮谁。
USER.md 的作用,就是把这些信息固定下来:
• 用户叫什么
• 希望如何称呼
• 时区
• 职业背景
• 技术栈
• 当前目标
• 长期方向
• 家庭情况
• 内容矩阵
• 做决策时优先考虑什么
比如同样一句“帮我写一篇文章”,如果它知道你是一个 AI 自媒体创业者,且有技术背景、又在做多账号矩阵,那它给出的就不会是普通的泛用文章,而会更偏向“能发、能转化、能联动账号矩阵”的版本。
所以 USER.md 的本质,不是介绍用户,而是减少误判。
三、除了核心 4 件套,还有哪些“配套灵魂器官”?
如果你真想把 OpenClaw 调顺,光有上面四个文件还不够。
完整一点的工作区,一般还会有这些配套文件:
1. TOOLS.md:工具使用约定,不是工具开关
这个文件最容易被误解。
它不是“工具权限控制器”,官方文档也明确说了:TOOLS.md 不控制工具是否存在。
它更像是你自己维护的一份“工具使用备注”:
• 哪些目录属于白名单
• 哪些操作需要额外谨慎
• 某些常用工具的特殊约定
• 团队内部的默认习惯
所以它更像工具层的“本地规则说明书”。
2. MEMORY.md 和 memory/*.md:长期记忆和每日记忆分层
这部分是 OpenClaw 非常聪明的一层设计。
官方文档里,记忆不是一锅炖,而是分成两层:
• MEMORY.md:长期、稳定、可复用的信息
• memory/YYYY-MM-DD.md:日常过程记录、运行上下文、阶段性笔记
这套分层非常关键。
如果你把所有东西都塞进一个长期文件里,上下文只会越来越臃肿。
OpenClaw 的思路是:
• 稳定事实放长期记忆
• 日常流水放 daily memory
• daily memory 不自动注入,而是通过 memory_search / memory_get 按需调用
这就既保住了记忆能力,又控制住了 token 开销。
3. HEARTBEAT.md:给助手定期巡检任务
如果你希望你的助手不是“你问一句它答一句”,而是能定期检查某些事情,HEARTBEAT.md 就很好用。
比如:
• 今天有没有没处理完的待办
• 某个内容项目是否拖延太久
• 某个服务有没有异常
• 某个固定流程该不该提醒你
没需求的时候,保持空文件就行。
4. BOOTSTRAP.md:新工作区的开机仪式
BOOTSTRAP.md 只在 brand-new workspace 场景里特别有意义。
它更像一个 onboarding 脚本:
• 先确认自己是谁
• 再确认服务对象是谁
• 再补身份、人格、偏好
• 最后完成初始化
这个设计很像你在给新员工做入职培训。
四、这些文件为什么真的有用?因为它们不是“存档”,而是会进上下文
这里是最容易被忽略的关键点。
很多人会以为,这些文件只是“放在那里,给自己做备忘”。
其实不是。
根据 OpenClaw 官方文档,工作区的 bootstrap files 会在每轮对话里作为 Project Context 被注入。核心包括:
• AGENTS.md
• SOUL.md
• TOOLS.md
• IDENTITY.md
• USER.md
• HEARTBEAT.md
• brand-new workspace 时的 BOOTSTRAP.md
• 如果存在,也会包括 MEMORY.md
这意味着什么?
意味着这些文件不是“放着好看”,而是模型每轮都会看到、会受它们影响。
这就是为什么同一个模型,换一套工作区文件,呈现出来就像换了一个人。
这也是为什么官方会提醒:这些文件要尽量精炼,因为它们会直接消耗上下文窗口。
一句话总结就是:
灵魂套件真正的威力,不在于你写了文件,而在于 OpenClaw 让这些文件持续参与每轮决策。
五、多 Agent 场景下,为什么这套东西会更值钱?
如果你只用一个 Agent,这套文件的价值已经很大。
如果你开始用多 Agent,它的价值会直接放大。
因为 OpenClaw 的多 Agent 设计,本质上是:每个 Agent 都有自己独立的工作区、状态目录和会话存储。
也就是说,每个 Agent 都可以拥有自己的一整套灵魂文件。
这会带来非常强的效果:
• Code Agent 更理性、更结果导向
• Content Agent 更重表达、更重传播和结构
• Home Agent 更柔和、更重陪伴和提醒
• Main Agent 更像总调度中心,负责统筹与分发
这不是简单换个 system prompt,而是从工作区层就把角色分开了。
从工程视角看,这才是多 Agent 真正好用的地方:
不是“同时开很多 AI”,而是“让每个 AI 长成不同的专业同事”。
六、如果你也想把 OpenClaw 调顺,应该怎么开始?
我的建议很简单:
不要一上来就追求大而全。
先把最常用的那个 Agent 调顺。
第一步:先只写 4 份文件
最小闭环就是:
• SOUL.md
• AGENTS.md
• IDENTITY.md
• USER.md
先解决三个问题:
• 它说话像不像你要的人
• 它做事有没有边界
• 它知不知道自己在帮谁
第二步:再补工具规则和记忆规则
当你开始长期用、开始做复杂任务,再补:
• TOOLS.md
• MEMORY.md
• memory/*.md
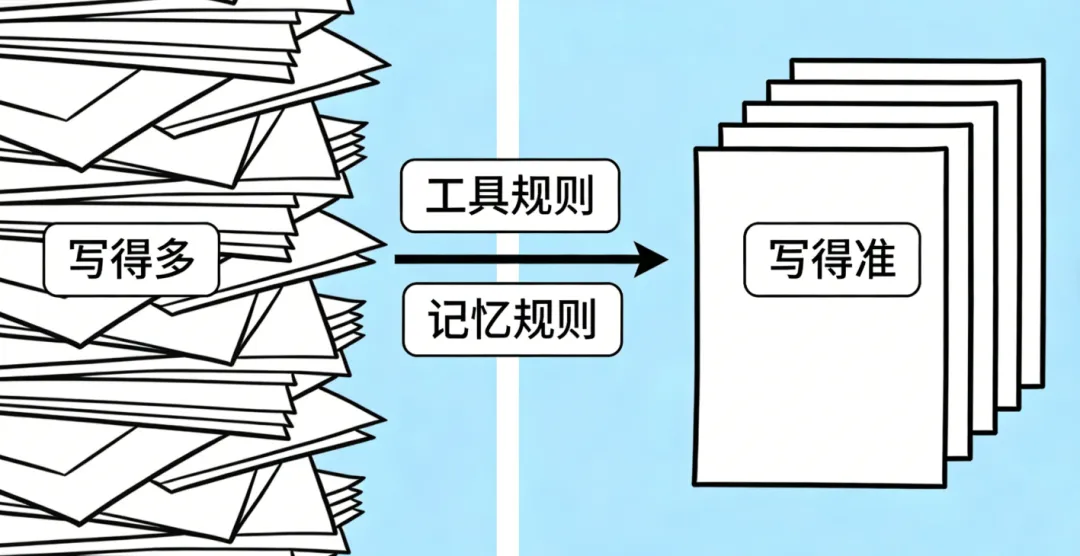
不要在最初就把所有东西塞满。
因为灵魂套件不是比谁写得多,而是比谁写得准。
第三步:最后再复制到其他 Agent
当主 Agent 已经调得比较顺了,再把这套方法复制给:
• code
• content
• home
• 其他专项 Agent
这样你的整个 AI 团队才会越来越稳定。
七、一个判断标准:你的 OpenClaw 到底有没有“灵魂”?
你可以用这个标准快速判断。
如果你的助手在长期使用中经常出现这些问题:
• 说话风格每次都不一样
• 每次都像第一次认识你
• 总要你重复背景信息
• 不知道什么时候该确认、什么时候该执行
• 一会儿像顾问,一会儿像客服,一会儿像搜索引擎
那说明它大概率不是模型不够强,而是灵魂套件还没立住。
反过来,如果你的助手已经开始具备这些表现:
• 始终知道自己扮演什么角色
• 清楚你是谁、你在做什么
• 面对任务时有固定工作逻辑
• 遇到高风险动作会先确认
• 长期使用后越来越顺手,而不是越来越散
那说明你已经从“在用一个 AI 工具”,走到了“在训练一个长期搭档”。
而这一步,恰恰就是 OpenClaw 真正有意思的地方。
八、最后:OpenClaw 拼到最后,拼的不只模型,还有你有没有把它“调成自己人”
模型很重要。
工具很重要。
渠道接入也很重要。
但如果你真的想把 OpenClaw 用成一个长期系统,而不是一个新鲜几天的玩具,那你迟早会回到同一个问题:
你有没有把它调成“自己人”?
而这背后真正的答案,不是再换一个模型,而是把那几份决定人格、规则、用户画像和记忆结构的文件写好。
这套我称之为“灵魂套件”的东西,恰恰就是 OpenClaw 从“能跑”走向“好用”的分水岭。
如果你也在折腾 OpenClaw,我的建议是:
别急着追求最强模型,先把灵魂装进去。
你会明显感觉到,它开始不像一个工具,而像一个真正能长期协作的数字同事。
好了,是不是很简单,今天的分享就到此结束,咱们下回见;

加我微信,探索和成长的路上,你并不孤单!



分享、在看与点赞

