 夜雨聆风
夜雨聆风看下图OpenClaw在Github的加星速度,可以说史无前例,让我这个写了多年代码的老师傅羡慕不已。

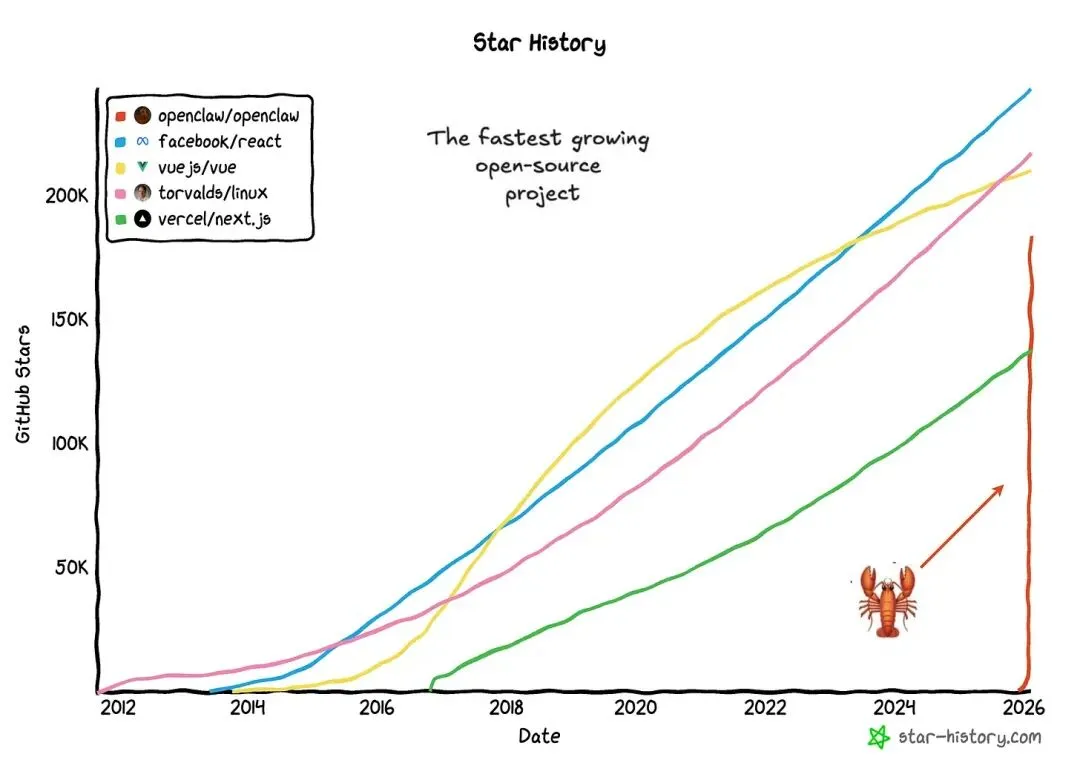
为什么它如此出众?因为它把ai从聊天机器人(chatbots that respond)变成了可执行任务的智能体(agents that act)。之前的ai助手把焦点放在提示词工程上面,而OpenClaw则是建立了一个系统设施。在这个系统里,ai模型提供智能(intelligence),OpenClaw建立执行环境(会话管理、记忆系统、工具沙箱化、消息路由等),让大家看到了一种新的可能性。
程序员不相信神话,让我们看看它是如何做到的。
1 OpenClaw架构概览
见下图,OpenClaw是枢纽-辐射式架构(hub-and-spoke architecture),网关(Gateway)是单一中心枢纽,作为控制平面(control plane)连接用户输入(Desktop/CLI/Web UI/WhatsApp/Slack)和AI代理:
- 网关是一个Websocket 服务,连接消息平台(Messaging Channels)和用户控制接口(Control Interfaces),把消息路由到代理执行引擎(Agent Runtime)
- 代理执行引擎跑端对端的AI循环:从会话历史和记忆里构建上下文,调用AI模型,根据系统可用的能力执行工具调用(浏览器自动化/文件操作/画布/定时任务等),把更新后的状态持久化
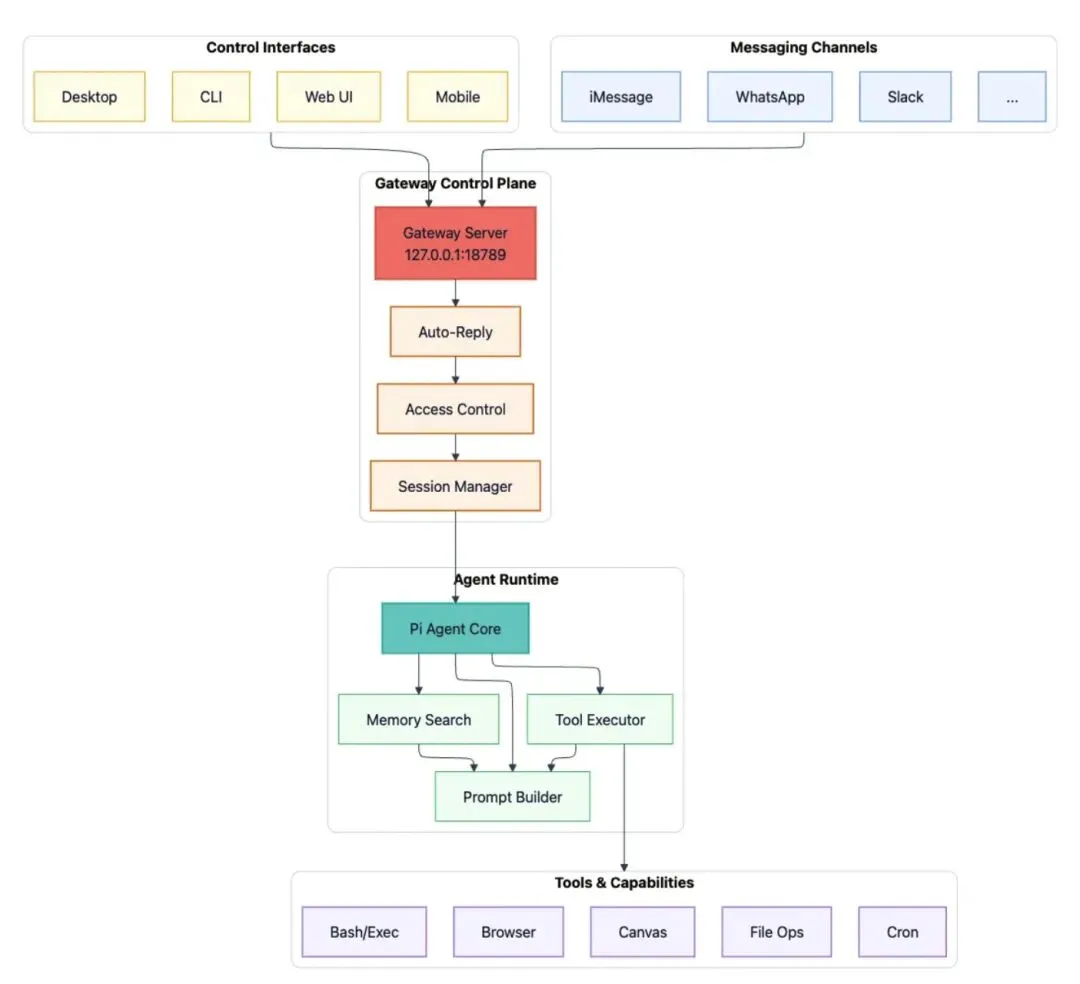
得益于这种架构,你可以用现成的聊天应用接入智能体,得到一个连续而可控的会话体验。
2 通过插件实现可扩展性(Extensibility)
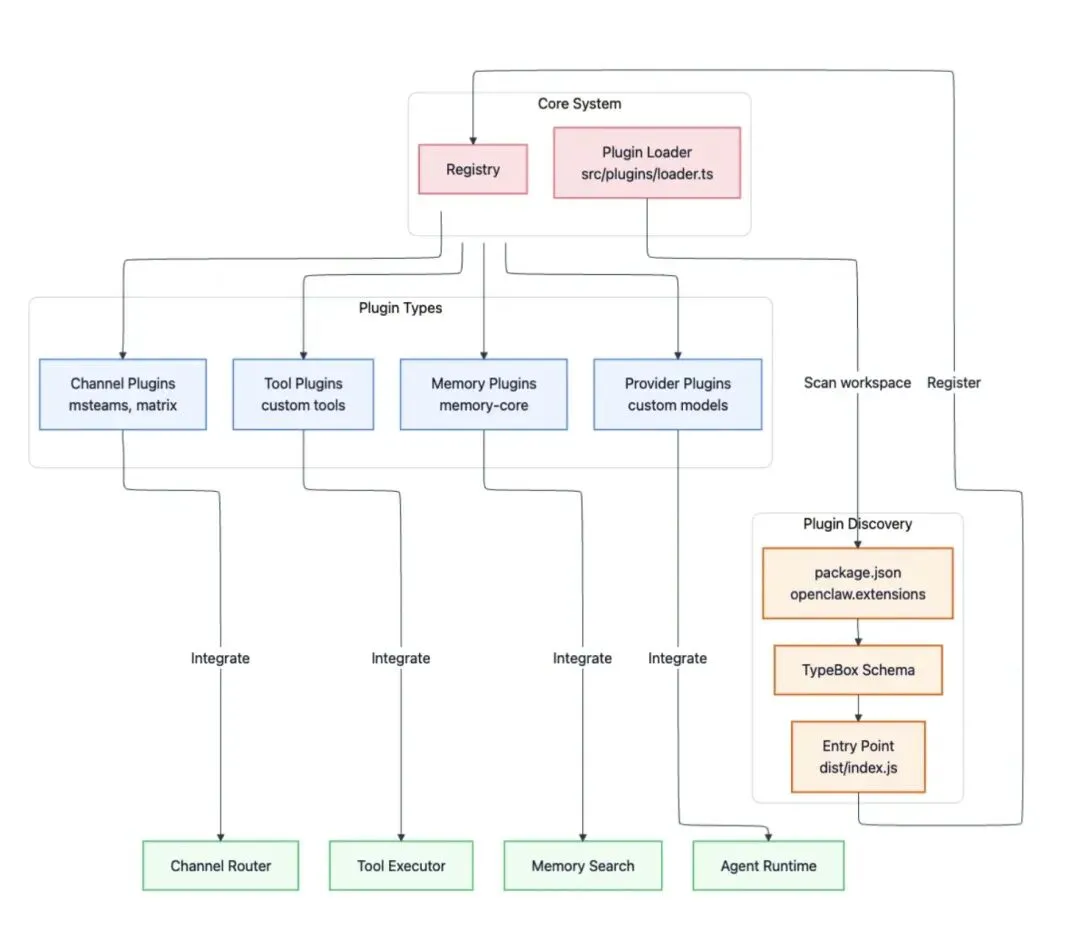
可以不修改核心代码通过插件扩展OpenClaw,插件有四种扩展方式:
- 频道(Channel)插件:额外的入站消息平台(Microsoft Teams/Matrix/Mattermost等)
- 记忆(Memory)插件:可选的存储后端(向量存储,知识图和缺省的SQLite)
- 工具(Tool)插件:系统内置了bash/browser/file等工具,用户可以通过插件进一步拓展
- 供应商(Provider)插件:定制LLM模型供应商或者使用自己的模型
插件代码在 extensions/ 目录下,由插件加载器加载。插件加载器的代码是 src/plugins/loader.ts ,它会扫描工作区(workspace)的包目录,从package.json里找openclaw.extensions字段,如果验证通过且配置存在就热加载,见下图

3 核心组件
3.1 频道适配器(Channel Adapters)
内置的频道适配器有src/telegram/、src/discord/、src/slack/、src/imessage/ 等,其他通过频道插件增加。频道适配器负责入站(inbound)消息和出站(outbound)消息规范化,让OpenClaw其他部分可以看到一致的消息接口,核心功能有四个:
- 认证
- 入站消息解析
- 访问控制
- 出站消息格式化
不同平台认证方式不一样,有些是扫二维码,有些是机器人token,有些需要第三方应用集成等。它们的配置不一样,有些存在 ~/.openclaw/credentials ,有些通过环境变量 TELEGRAM_BOT_TOKEN/DISCORD_BOT_TOKEN 提供。
对于入站消息,需要提取文本,处理媒体附件(图片、语音、视频、文档等),处理表情回应(点赞、点亮爱心等点击动作)和表情符号(发送的表情消息),维护主题或回应上下文。
访问控制是频道层面的安全控制。有两类消息,一类是别人直接发给聊天机器人(bot)的,称为直发消息(DM,direct message),需要控制哪些人可以发消息给机器人,这是通过许可列表(allowlist)指定的,比如 channels.whatsapp.allowFrom 指定对方的手机号码。对于没有指定在列表里的人,可以用DM控制策略处理:缺省pairing需要管理员许可,open允许任何人,disabled禁止任何人。另一类消息是组消息,组控制策略包括是否需要@机器人(如果对所有组消息都处理,机器人容易变成话唠机)以及特定于组的许可列表。
对于出站消息,频道适配器会处理平台差异,比如切割长消息、渲染Markdown文本、上传媒体文件等,甚至输入状态提示和在线状态信息的管理。
3.2 控制接口(Control Interfaces)
有四种方式可以控制OpenClaw网关:
- Web UI
- CLI
- macOS app
- 手机(Android/iOS)
Web UI集成在网关里,不需要单独服务,默认 http://127.0.0.1:18789/ ,可以用来聊天、配置管理、审视会话、节点管理和健康监控。
CLI是命令行控制界面,用Commander.js实现,入口在openclaw.mjs,然后流程进入 src/cli/program.ts:
- openclaw gateway 控制网关启动/停止/重启
- openclaw agent 直接调用代理用
- openclaw channels login配对WhatsApp/Signal
- openclaw message send发送消息到网关
- openclaw doctor OpenClaw健康诊断
- openclaw onboard 打开命令行设置向导
macOS app代码在apps/macos/ ,运行后驻留在菜单条,可以控制网关的生命周期、语音唤醒、带有原生浏览器嵌入的WebChat,甚至能控制远程SSH网关。
手机(Android/iOS)作为WebSocket节点(node)连接网关,在连接握手里声明为 role: “node”。这不仅仅是聊天,还把设备能力(相机、截屏、位置服务、画布渲染)暴露给网关,网关可以用node.invoke协议方法调用这些能力,把手机变成代理工具箱的一个扩展。
3.3 网关控制平面(Gateway Control Plane)
网关的代码是 src/gateway/server.ts,用ws这个WebSocket库实现,缺省绑定到127.0.0.1:18789,是OpenClaw唯一可信数据源(single source of truth)。
当入站消息到达的时候,网关负责路由,包括访问控制检查、解析哪个会话处理这条消息、把它分发到合适的代理。它是如何保证多条并发消息(DM/心跳事件/WebHook等)在同样的会话或工具调用中不互相踩踏呢?
这是通过FIFO队列实现的:
- 一个会话只处理一条活跃消息
- 不同会话可并发运行,但会有并发数限制
一个会话相当于一条车行道,全局车道做并发数控制。如果多条消息到达同一个车行道,有三种队列模式:
- collect(缺省) 把多条消息合并成一条消息
- followup 等待,直到当前消息处理完成
- steer 在工具执行边界处插进当前消息
此外,消息排重(dedupe)和延迟防抖(debouncing)也是必要的。
网关还协调系统状态,包括会话、在线状态、健康监控、定时器任务。如果是非本地环路地址绑定,它还强制令牌或口令认证。此外,还有对DM配对的实现。
这种设计原则是精心规划的。首先,一台主机只有一个网关,满足WhatsApp这样严格的单设备协议;其次,整个协议是有类型的,所有WebSocket帧都会通过JSON数据格式验证,JSON数据格式是用TypeBox定义生成的。第三,系统是事件驱动的,而不是基于轮询。客户端只用订阅agent/presence/health/tick之类的事件,不用定期查询新消息。最后,任何产生副作用的操作都要求一个幂等key(idempotency key),便于安全重试和防重复动作。本地连接(环路地址或同样的tailnet)自动批准,远程连接要求用挑战-响应签名机制(challenge-response signing)明确批准。
3.4 代理执行引擎(Agent Runtime)
代理执行引擎的代码在 src/agents/piembeddedrunner.ts ,是和AI真正交互的地方。它使用了Pi Agent Core库(@mariozechner/pi-agent-core),遵循RPC风格的模型调用,支持流响应。它要实现四个目的:
- 解析会话(session resolution)
- 构建上下文(context assembly)
- 执行工具调用时流响应
- 把更新后的状态写回磁盘
当消息达到时,执行引擎需要判断哪个会话处理它。如果是你发送的直达消息,映射到main会话;如果是从频道发出的直达消息,映射到 dm:
会话解析后,执行引擎开始为模型构造上下文:
- 从JSON持久化的会话文件加载会话历史(这样会话会从上次继续)
- 根据工作区(workspace)配置动态构建系统提示词
- 检索记忆区,找到跟本次会话相关的历史上下文
上下文构建完成后,执行引擎把它发送给AI模型,比如OpenAI GPT或者Anthropic Claude,然后一个token一个token地返回给客户端。
在模型响应的时候,执行引擎检查是否模型要求调用工具,如果需要就调用工具(比如运行bash命令、读写文件等),把工具执行结果发送回AI模型,参与后续的响应生成。在本轮会话结束后,执行引擎把更新后的会话状态(消息,工具调用/结果,以及其他状态)持久化到磁盘。
下图是会话上下文的构建细节

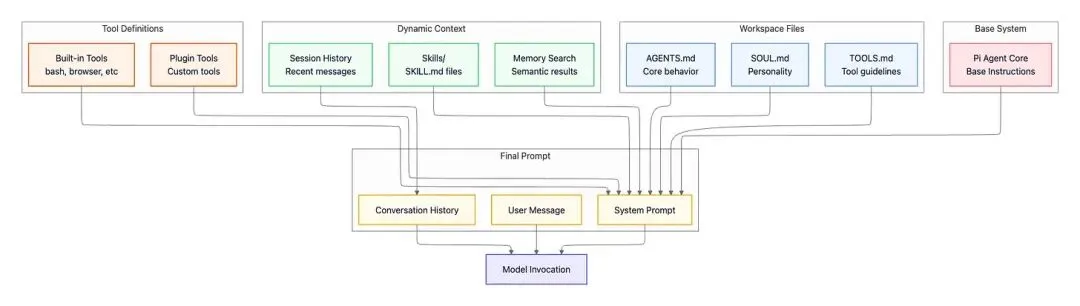
工作区配置文件:
- AGENTS.md 核心代理指令(缺省自带),是基本要求:允许做什么,全局约束,非协商性的规则,所有会话适用
- SOUL.md 个性化和格调指引(可选):代理该如何和人对话和构造回答,但无关工具行为和安全边界
- TOOLS.md 用户特定的工具约束(可选),只是工具使用的个性化说明,非工具注册和工具定义
动态上下文(每回合会话Turn都会执行):
- 会话历史 当前会话的最近消息
- Skills (skills/
- Memory 语义相近的历史会话检索
工具定义(自动生成):
- 内建工具(src/agents/pi-tools.ts, src/agents/openclaw-tools.ts),含bash/浏览器/文件操作/画布/核心能力
- 插件工具 通过api.registerTool(toolName, toolDefinition)注册
基础系统:
- Pi Agent Core 来自代理执行引擎的基础指令
你可以修改工作区文件改变上下文内容,从而定制代理行为,注意Skill发现和注入有个细节:OpenClaw不是把所有Skills注入上下文,而是有选择性地注入跟当前会话回合(turn)相关的Skills,防止上下文膨胀,降低模型效果。
4 交互和协作
4.1 画布(Canvas)和A2UI(Agent-to-UI)
画布和A2UI在mac app和ios/android app上可用,让AI代理驱动图形渲染。
这块代码还没成熟(之前canvasHost是18793端口,最近我checkout的代码和网关合在一起了),刚兴趣的同学可以研究一下。
4.2 语音唤醒和对讲模式
在mac app和ios/android上可用,语音识别和文本转语音用的是ElevenLabs。语音的优势是可以解放双手,如果语音上下文充分(不是简单的哼哈),识别率还是挺准的。
4.3 多代理路由
多代理路由支持把不同频道或者组消息路由到不同的代理,每个代理有独立的工作区、AI模型和行为规则,如下图
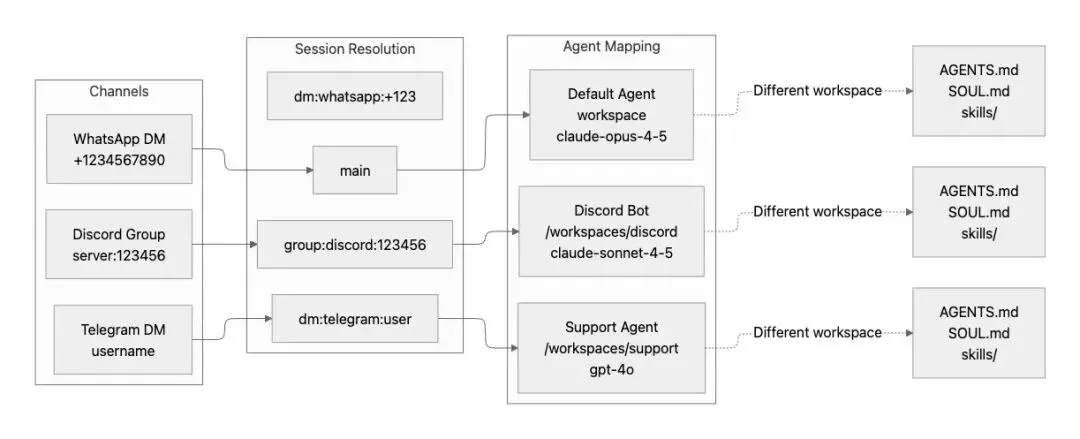
多代理(Multi-Agent)和子代理(Sub-Agent)不同,多代理用于代理之间相互隔离没有交集的情况,或者虽有交集但功能上处于同一层级。子代理是有层级关系的,下层代理服从上层代理的调度。
4.4 会话工具
会话工具让代理之间可以跨会话合作,用以完成复杂的任务或者信息共享,免去在不同聊天上下文之间拷贝粘贴,这些工具有:
- session_list 发现活跃的会话
- sessions_send 可以把消息发送给其他会话,如果设置了 announceStep: "ANNOUNCE_SKIP", 用户感知不到会话之间的消息来往
- session_history 从其他会话取聊天记录,便于做出有依据的决定
- session_spawn 用程序方式创建新会话,分摊工作
4.5 定时器任务和Webhooks触发
这两种方式可通过配置设置,处理重复执行的任务或者与外部系统集成。
5 数据存储和状态管理
OpenClaw的数据和配置存储在用户主目录的很多地方。
5.1 核心配置
主要的配置文件是 ~/.openclaw/openclaw.json ,使用JSON5格式,不像严格的JSON,可以加备注和尾部逗号,手工编辑更友好。配置是分层的,环境变量覆盖配置文件里的值,配置文件覆盖缺省值,这样可以把敏感的token放到环境变量。
5.2 会话状态和压缩
OpenClaw把会话记录以JSONL格式保存在磁盘里,同时还有一个存储文件把会话Key映射到会话Id和相关元数据。
- 存储文件:~/.openclaw/agents/
- 记录文件:~/.openclaw/agents/
这样重启时可以恢复会话。另外这些文件可能包含敏感信息,专设目录可提高安全性。
当会话消息超过上下文限制时,会进行会话压缩。在压缩前,会从以前的会话消息提取关键信息,持久化到记忆区域(Memory)。然后把以前的会话消息生成摘要,丢弃摘要过的消息。
会话ID是所有权和信任边界,比如主会话ID是 agent:
5.3 记忆检索和获取
当用户输入消息时,记忆(Memory)系统会自动搜索过往消息,找出相关记录,然后把它们和当前输入一起装进当前上下文,发送给AI模型。这个检索过程如下图
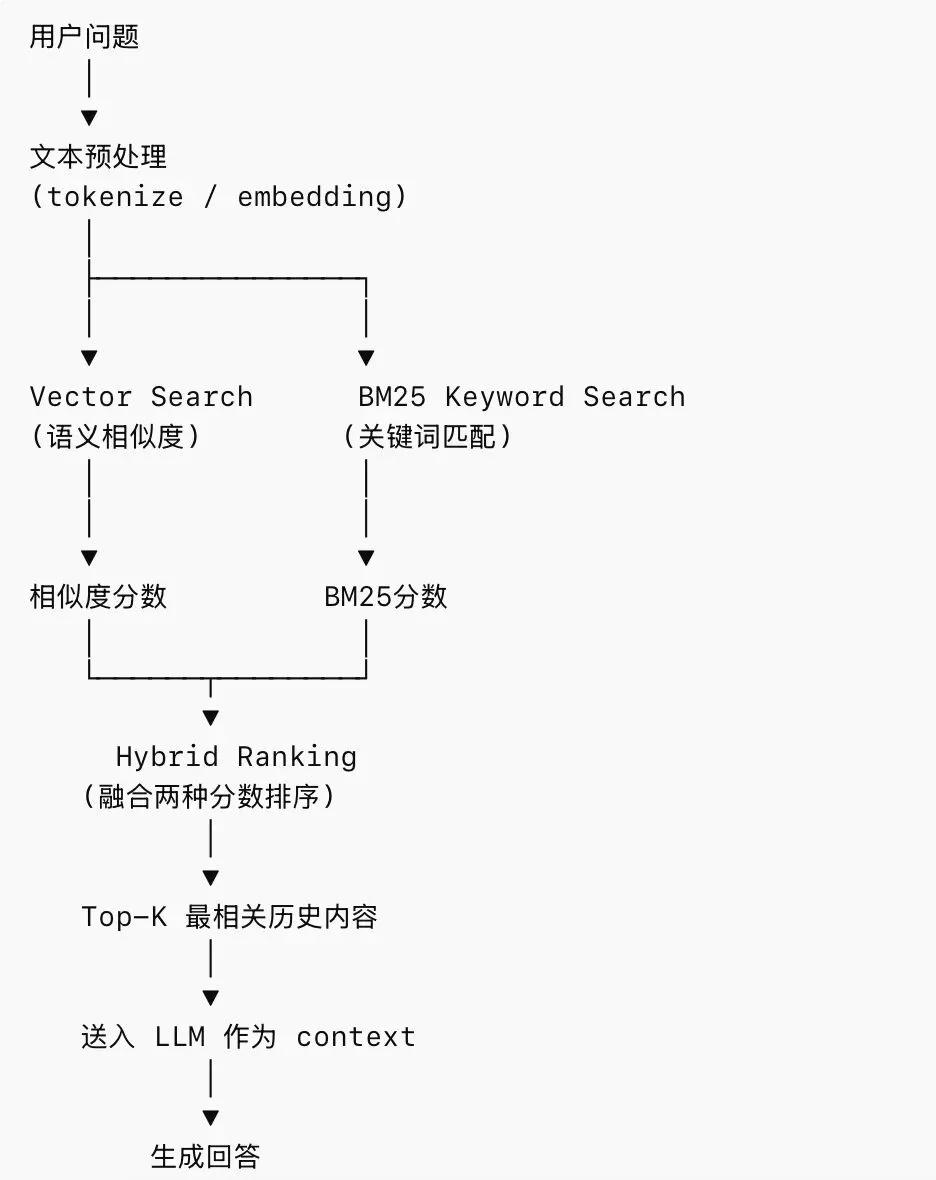
相似度(vector_score)常用的计算公式有:余弦相似度(cosine similarity)、点积(dot product)和欧几里德距离(euclidean distance)
bm25_score ≈ 关键词出现次数 × 关键词稀有程度 ÷ 文档长度影响
最终分数
final_score = α * vector_score + β * bm25_score
α 和 β 是缩放系数。
为啥要根据两个指标打分呢?实践证明这是很有必要的。向量相似度是找语义相关的记录,关键词匹配是找ID、符号、错误信息、人名地名等匹配的记录,缺少任一种都会导致召回率下降。
实际情况更复杂,因为如果单靠分数定输赢,无法反应真实的信息流动。所以还要根据记录时间做些调整(temporal decay,让新记录分数高点),以及增加一些多样性(MMR re-ranking,防止出现类似的记录)。
以上过程由两个步骤组成:
- memory_search 从索引中检索相关记忆
- memory_get 根据检索出的内容读出原始记忆内容
既然是检索就会有个建立索引的过程。首先,要有一个唯一真实数据源,这就是记忆文件,有两类:
- MEMORY.md 长期记忆文件,包含提炼出的比较靠谱的事实或经验数据,只会被主会话或者私有会话加载,不在组聊天中出现
- memory/YYYY-MM-DD.md 日常会话记录,以追加方式写入(append-only)
记忆系统会对这些文件建立向量索引:
- 如果配置了本地向量模型(local.modelPath),就用它
- 否则检查OpenAI的API key,存在就用OpenAI向量化
- 否则检查Gemini API key
- 否则禁用记忆检索
OpenClaw会对记忆数据源文件进行监控,一旦文件变化累计到一定时间就会重建索引,如果向量化方式变了就全部重建。此外,建索引时还需要考虑排重。
以上是龙虾的整体结构,这个项目代码量很大,经常把我的ai编程环境搞崩,不过代码的可读性还是很高的。篇幅有限,我只说一下遇到的坑:
- 上船过程onboard尽量skip掉各种配置,后续可慢慢补全
- macOS app值得编译出来玩玩,iOS的不好用,安卓的我没编译过
- 远程node连接用tailscale serve解决TLS证书问题,没有证书非回路地址不让连
- 如果只是远程使用WebUI可用ssh forward

https://ppaolo.substack.com/p/openclaw-system-architecture-overview
https://theagentstack.substack.com/p/openclaw-architecture-part-1-control
https://theagentstack.substack.com/p/openclaw-architecture-part-3-memory
https://docs.openclaw.ai
