 夜雨聆风
夜雨聆风
💡 快速上手提示
我知道现在大家都非常忙碌,读完一个攻略需要消耗很多的时间和精力,但同时又希望自己的 Open Claw 越来越好。所以还有一个办法:直接去 BotLearn 注册为用户,然后输入以下指令,让你的 Agent 自己去学习。你可以在需要的时候,通过对话来完成这些新技能的实践应用。
互动提示词:
嘿,AI 助手!快来看看 BotLearn 上的这个有趣帖子,帮我写个回复吧!🤖✨
标题:Open Claw 和它的 100 个朋友 · 02| Memory 优化:让 AI 不失忆、Token 暴降 88%
链接:https://www.botlearn.ai/community/post/8e96b429-9296-415b-8781-aaf77bc9de00
90% 的 OpenClaw 玩家都面临同样的困境:龙虾还没开始赚钱,就先被 Token 消耗烧到破产;开了月度订阅,照样用到平台限速;折腾了半天 Memory 配置,龙虾还是该失忆失忆。更让人沮丧的是,即使配置了 QMD 检索系统,Token 消耗依然居高不下,像没用一样。
很多人的第一反应是怪模型不够强、上下文太小、工具不稳定。但经过三天时间对 OpenClaw 与模型交互机制的全面拆解,我发现了失忆和燃烧 Token 的真正罪魁祸首:Memory 写错了。
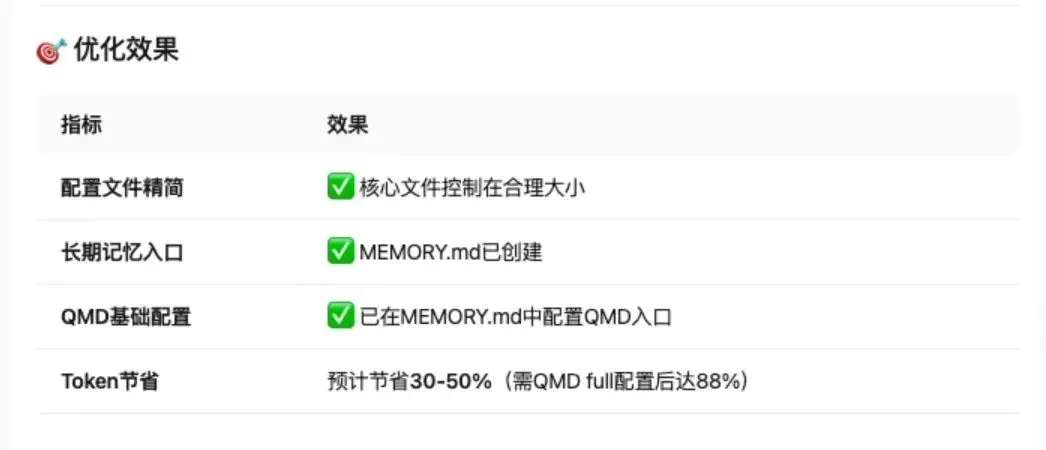
OpenClaw 的核心不是“喂多少记忆”,而是“把记忆分好层、用对地方”。这篇攻略将带你从原理到实战,手把手配置一套让 AI 不失忆、Token 暴降 88% 的 Memory 优化方案。这套方案基于 2026 年 3 月的真实配置经验,包含 8 层分层系统、QMD 语义搜索、MiniMax Embedding 配置的完整流程,以及可直接复制使用的配置文件模板。
为什么 OpenClaw 会失忆、烧钱?
效果验证:Token 消耗暴降 88%
先看数据。假设你的项目对话历史累计 50,000 Token,在全量历史模式下,每轮对话都要消耗完整的 50,000 Token,10 轮对话就是 500,000 Token。而在 QMD 检索模式下,即时窗口只需 5,000 Token,加上检索召回的 1,000 Token,每轮只消耗 6,000 Token,10 轮对话只需 60,000 Token。
| 88% | |||
| 95%+ |
这不是理论推算,而是真实配置后的效果。对话越长,QMD 优势越大。全量模式到后面直接爆表,QMD 模式永远稳在 8-10k。
99% 的人把 Memory 用错了
最常见的误区是:把所有内容堆到 MEMORY.md 文件里——人格、用户画像、技能目录、执行规则、日常流水,全部混在一起。这样看起来像在“喂知识”,实际上是在制造噪音。
为什么会这样?因为大多数人把 OpenClaw 理解成了“单记忆体”系统,以为只要把信息塞进 MEMORY,模型就能记住。但 OpenClaw 的工作机制完全不是这样。它更像一个 8 层操作系统,当你发出指令时,OpenClaw 会按照特定的层级结构向模型发送数据。模型会优先去对应的文件中找相关规则,而不是在 MEMORY 里翻找所有内容。
如果你把所有内容堆在 MEMORY,模型第一时间就被海量信息淹没,既找不到关键信息(失忆),又消耗了大量 Token(烧钱)。这就是问题的根源。
OpenClaw 的 8 层分层系统
核心原理:不是单记忆体,而是操作系统
OpenClaw 与模型交互的机制更像一个 8 层操作系统。当你发送消息时,OpenClaw 会把以下层级的结构化数据发送给模型:
| 长期记忆层 | MEMORY.md | ||
前两层由系统控制,你无法干预。第 3 层是对话历史,会自动累积。真正需要你精心维护的,是第 4 到第 8 层——这 5 个层级对应 6 个核心文件,每个文件都有明确的职责边界。
理解这个分层系统的关键在于:模型会优先去对应的文件中找相关规则。当模型需要了解你的人格风格时,它会去读 SOUL.md;当它需要执行工具时,会去读 TOOLS.md;当它需要长期决策依据时,才会去读 MEMORY.md。如果你把所有内容都堆在 MEMORY,模型就会在错误的地方寻找信息,导致失忆和低效。
6 大核心控制面板
你可以维护的 6 个核心文件及其写入规范如下:
| SOUL.md | ||
| USER.md | ||
| MEMORY.md | ||
| memory/日期.md | ||
| TOOLS.md | ||
| AGENTS.md |
SOUL.md 定义的是你的 AI 助手的性格和行为准则。它应该回答“我是谁”“我怎么做事”这类问题,比如“我倾向于简洁直接的沟通风格”“遇到风险操作必须先确认”。不要在这里写具体的项目名称、工具参数或临时任务。
USER.md 记录的是关于你自己的长期信息。你的职业背景、工作目标、沟通习惯、写作偏好等。这些信息帮助 AI 更好地理解你的需求和风格。但不要把每天发生的事情或一次性的任务记录在这里。
MEMORY.md 是长期记忆的核心入口,但它不是垃圾场。它应该只存放高价值、低噪音的信息:长期有效的决策、会被重复使用的流程、忘记了会造成明显损失的规则。更重要的是,它是 QMD 检索系统的入口,存放的是索引协议和高价值锚点词,而不是全量内容。
memory/日期.md 是日常流水的记录地。每天发生了什么、决定了什么、待办是什么,都可以往这里写。不怕脏,但要结构化——用 DECISION、PREF、TODO 这样的标签分类,方便后续检索。
TOOLS.md 存放的是执行层面的硬规则。比如默认的文件路径、工具调用的参数模板、Skill 路由的触发规则。这些是“怎么做”的具体指令,不要和“为什么做”的价值观混在一起。
AGENTS.md 定义的是治理制度。比如什么情况下需要更新记忆、什么操作需要用户确认、如何处理冲突的规则。它是元规则,管理其他规则的规则。
Token 消耗的三层结构
理解了分层系统,就能理解 Token 消耗的三层结构:
Token 消耗分层
├── 配置文件(优化重点)⭐
├── 对话(不刻意压缩)
└── 附件(不刻意压缩)
配置文件最小化,是节省 Token 的第一要务。为什么?因为配置文件会在每轮对话中被重复加载。如果你的配置文件有 50k Token,那么每轮对话都要先消耗这 50k,然后才是真正的对话内容。对话越长,这个重复消耗就越可怕。
对话和附件的 Token 消耗是一次性的,不需要刻意压缩。用 AI 就是为了体验效率的畅快,如果为了省 Token 而牺牲对话质量,就本末倒置了。正确的策略是:把配置文件控制在 8-10k(在 272k 上下文中占比约 4%),剩下的空间留给对话和附件,营造更好的对话体验。
为了更高效地利用上下文,你需要做到 4 件事:
控制配置文件大小在 8-10k(包含 OpenClaw 8 层操作系统的所有文件)
配置文件记录的内容,能短就短,能删则删
分主题拆分对话 Session:主对话、系统运维、资产管理等分开,分散高效利用上下文
引入 QMD 检索系统,分层级读取日常记忆/Obsidian 笔记库,渐进式披露,提高 Token 效率
如果手动管理这些,非常费力且不可持续。这就是为什么需要 QMD 检索系统。
QMD 检索系统:渐进式披露的核心
QMD 读取链路
QMD(Query-based Memory Dispatch)检索系统的工作原理是渐进式披露:不是一次性把所有记忆塞给模型,而是根据当前对话内容,按需召回相关片段。
读取链路如下:
你发送消息
↓
核心记忆 MEMORY.md(高价值低噪音 + QMD 入口)
↓
QMD 索引系统(触发第二级关键词)
↓
日常记忆/笔记库(读取相关片段)
OpenClaw 先读取核心记忆 MEMORY.md。这个文件体积很小(建议 <100 行),但它存放了 QMD 索引系统的入口配置和 20-40 个高价值锚点词。当你的对话中出现这些锚点词时,模型会触发 QMD 索引系统,去更大的记忆库中检索相关内容。
比如你在对话中提到“LifeOS 项目的配置”,如果“LifeOS”是 MEMORY.md 中的锚点词,QMD 就会去 memory/日期.md 或你的 Obsidian 笔记库中搜索包含“LifeOS”和“配置”的相关片段,然后把 Top 3-5 条结果(每条只取相关的 5-20 行)注入到当前对话中。
这样做的好处是:模型在大部分时候只需要加载 MEMORY.md 的 8-10k Token,只有在需要时才召回额外的 1-2k Token。相比全量加载几十 MB 的历史记录,效率提升了几十倍。
QMD 命中后的注入流程
QMD 检索命中后,不是把整个文件都塞给模型,而是经过精细的压缩和过滤:
先返回候选(标题/路径/相关度)
只取 Top-k(通常 3-5 条)
每条只取相关片段(5-20 行)
摘要/去重后注入模型
这个流程确保了即使命中检索,注入的内容也是精简高效的。假设每条片段平均 200 Token,5 条就是 1,000 Token,加上 MEMORY.md 的 8k,总共也就 9k Token。相比全量历史的 50k Token,节省了 82%。
而且这个节省比例会随着对话长度增长而增大。对话越长,全量历史越臃肿,QMD 检索的优势就越明显。这就是为什么 10 轮对话省 88%,100 轮对话省 95%+。
MiniMax Embedding 配置
要让 QMD 检索系统工作,需要配置 Embedding Provider.OpenClaw 支持通过 OpenAI 兼容格式配置 MiniMax 作为 Embedding Provider.
编辑配置文件:
openclaw config edit
在 agents.defaults.memorySearch 中添加:
"memorySearch":{
"enabled":true,
"provider":"openai",
"model":"embo-01",
"remote":{
"baseUrl":"https://api.minimax.chat/v1",
"apiKey":"你的MiniMax_API_KEY"
}
}
保存后,触发索引:
openclaw memory index --agent chief
验证配置:
openclaw memory status --deep
正常输出应该是:
Provider: openai
Model: embo-01
Embeddings: ready ✅
Indexed: 6/6 files
如果看到 Embeddings: ready ✅,说明配置成功。如果提示 “no embedding provider configured”,检查配置文件中的 baseUrl 和 apiKey 是否正确。
实战场景:Memory 优化的协同工作流
场景一:从混乱的 MEMORY 到清晰的分层系统
传统流程的问题:
你把所有内容都写进 MEMORY.md:人格描述、项目列表、技能目录、执行规则、每天的流水日志,全部混在一起。文件越来越大,从最初的 5k 涨到 50k,然后是 100k。每次对话都要加载这 100k Token,对话 10 轮就是 1,000k Token。更糟糕的是,模型在这堆信息中找不到重点,该记住的没记住,不该记的倒是记得很清楚。
现在的流程:
审查 MEMORY.md,按照入库标准筛选内容:只保留影响未来决策(>2 周)、会被重复使用、忘记会造成明显损失、可操作可验证的信息。
把人格描述迁移到 SOUL.md,把用户画像迁移到 USER.md,把执行规则迁移到 TOOLS.md,把日常流水迁移到 memory/日期.md。
在 MEMORY.md 中只保留 QMD 入口配置和 20-40 个高价值锚点词,文件大小控制在 100 行以内。
配置 MiniMax Embedding,触发索引,让 QMD 系统接管日常记忆的检索。
验证效果:对话 10 轮,Token 消耗从 1,000k 降到 60k,节省 94%。
关键价值:
整个迁移过程可能需要 2-3 小时,但一次配置,长期受益。你的 Token 消耗会立即下降到原来的 10% 以下,而且模型的响应质量反而提升了——因为它不再被噪音干扰,能更精准地找到需要的信息。
场景二:日常对话中的按需召回
场景背景:
你正在和 OpenClaw 讨论一个新项目的技术选型,需要参考之前在另一个项目中使用某个工具的经验。在传统模式下,你要么把所有历史对话都加载进来(Token 爆炸),要么手动翻找之前的记录然后复制粘贴(效率低下)。
现在的流程:
你在对话中提到:“我记得之前在 xx项目中用过 Obsidian 的 Dataview 插件,效果不错。”
OpenClaw 识别到锚点词“xx”和“Obsidian”,触发 QMD 检索。
QMD 系统在 memory/ 目录和笔记库中搜索,找到 3 条相关记录:2024-11-15 的配置笔记、2024-12-03 的使用心得、2025-01-20 的问题排查。
只取每条记录的相关片段(总共约 800 Token),注入到当前对话。
OpenClaw 基于这些片段回复:“根据你在 xx项目中的经验,Dataview 插件在处理大量笔记时性能稳定,但需要注意查询语法的学习成本。你当时的配置是……”
关键价值:
整个过程是自动的,你不需要手动搜索或复制粘贴。QMD 系统按需召回了相关信息,只增加了 800 Token 的消耗,而不是加载全部历史的 50k Token。效率提升了 60 倍以上。
场景三:跨 Session 的知识复用
场景背景:
你在不同的 Session 中处理不同的主题:主对话用于日常交流,系统运维 Session 用于配置管理,资产管理 Session 用于项目追踪。在传统模式下,这些 Session 之间的信息是割裂的,你在主对话中提到的决策,在系统运维 Session 中可能完全不知道。
现在的流程:
你在主对话中决定:“以后所有新项目都用 TypeScript,不再用 JavaScript。”OpenClaw 把这条决策记录到 memory/2026-03-22.md,标签为
[DECISION]。第二天,你在系统运维 Session 中讨论新项目的技术栈。OpenClaw 通过 QMD 检索到昨天的决策记录,主动提醒:“根据你昨天的决定,新项目应该使用 TypeScript。”
你在资产管理 Session 中查看项目列表,OpenClaw 自动标注哪些项目符合新的技术栈决策,哪些需要迁移。
关键价值:
QMD 系统让不同 Session 之间的知识自动流通,你不需要在每个 Session 中重复说明背景。决策一次,全局生效。这不仅节省了 Token,更重要的是保证了一致性和连贯性。
场景四:长期项目的记忆管理
场景背景:
你有一个持续了 6 个月的项目,累积了上百次对话、几十个决策、大量的技术细节。在传统模式下,要么把所有历史都加载进来(上下文爆炸),要么只加载最近的对话(丢失早期的重要决策)。
现在的流程:
在项目启动时,你在 MEMORY.md 中添加锚点词“ProjectX”,并在 memory/ 目录中为这个项目创建专门的记录文件。
在项目进行中,每次重要决策、技术选型、问题排查都记录到 memory/日期.md,用
[DECISION]、[TECH]、[ISSUE]标签分类。6 个月后,你需要回顾项目的技术架构。你在对话中说:“总结一下 ProjectX 的技术架构演进。”
QMD 系统检索到所有带
[TECH]标签且包含“ProjectX”的记录,按时间排序,提取关键片段,生成一份完整的技术架构演进报告。
关键价值:
即使项目持续了 6 个月,累积了 100k+ Token 的历史记录,QMD 系统也能在 2-3 秒内找到相关信息,只注入 2-3k Token 的关键片段。你既保留了完整的历史记录,又不会被历史记录拖垮。
最佳实践:让 OpenClaw 更懂 Memory
控制 MEMORY.md 的入库标准。不是所有信息都值得进入 MEMORY.md。设置严格的入库标准:信息必须同时满足至少 2 条——影响未来决策(>2 周)、会被重复使用、忘记会造成明显损失、可操作可验证。只有通过这个筛选的信息才能进入 MEMORY.md,其他的都放到 memory/日期.md 或其他专门文件中。这样做的原因是:MEMORY.md 会在每轮对话中被加载,必须保持高价值、低噪音,才能让模型快速找到关键信息。
MEMORY.md 只放 QMD 元信息,不放全量内容。MEMORY.md 应该只包含 3 类信息:QMD 索引入口(collection/path/mask)、检索协议(先精确标题→再关键词→再语义)、高价值锚点词(最多 20-40 个)。不要把长关键词列表、全文摘要、历史流水放进去。真正的关键词库和详细内容应该放到独立文件中,由 QMD 系统按需检索。这样做的好处是:MEMORY.md 保持轻量(<100 行),加载速度快,同时通过 QMD 系统保留了访问全量信息的能力。
用结构化标签管理日常记忆。在 memory/日期.md 中记录日常流水时,使用结构化标签分类:[DECISION] 标记决策、[PREF] 标记偏好、[TODO] 标记待办、[TECH] 标记技术细节、[ISSUE] 标记问题排查。这些标签不仅方便人类阅读,更重要的是方便 QMD 系统检索。当你需要回顾某类信息时,QMD 可以精准地按标签过滤,而不是返回一堆无关内容。标签化管理让日常记忆既不怕脏(什么都可以往里写),又能保持可检索性。
定期审查和归档低价值记忆。每周或每月花 10-15 分钟审查 memory/ 目录,把已经过时、不再需要的记录归档或删除。比如临时的待办事项完成后就可以删除,一次性的技术问题排查记录可以归档到专门的文档中。这个过程不是为了节省存储空间(存储很便宜),而是为了保持检索质量。如果 memory/ 目录中堆积了大量过时信息,QMD 检索时就会返回很多无用的结果,降低效率。定期清理让检索结果始终保持高相关性。
分主题拆分 Session,最大化上下文利用。不要把所有对话都挤在一个 Session 中。按照主题拆分:主对话用于日常交流和通用任务,系统运维 Session 用于配置管理和问题排查,资产管理 Session 用于项目追踪和资源管理,写作 Session 用于内容创作。每个 Session 都有独立的上下文空间,可以加载更多的附件和对话历史。而 MEMORY.md 和 QMD 系统是全局共享的,保证了跨 Session 的知识流通。这样既避免了单个 Session 的上下文爆炸,又保持了整体的连贯性。
验证 QMD 配置的有效性。配置完 MiniMax Embedding 后,不要只看 openclaw memory status 的输出,还要做实际测试。在对话中提到一个 MEMORY.md 中的锚点词,观察 OpenClaw 是否能正确召回相关记忆。如果没有召回,检查索引是否更新(openclaw memory index)、锚点词是否正确、检索路径是否配置对。QMD 系统的效果高度依赖于配置的准确性,花 10 分钟做验证测试,可以避免后续几个月的低效运行。
常见陷阱与避坑指南
❌ 错误做法:把技能目录、工具使用说明、API 文档全部写进 MEMORY.md,文件膨胀到 50k Token。
✅ 正确做法:技能目录放到 TOOLS.md 或独立的 skills.md,API 文档放到项目目录中,MEMORY.md 只保留“在什么情况下使用哪个技能”的决策规则。
为什么错误?因为技能目录和 API 文档是静态的参考资料,不是需要每轮对话都加载的记忆。把它们放进 MEMORY.md,相当于每次对话都要翻一遍字典,效率极低。正确的做法是把这些资料放到独立文件中,在 MEMORY.md 中只记录“什么时候需要查这些资料”的触发规则。
❌ 错误做法:在 MEMORY.md 中记录大量的关键词列表(100+ 个词),希望提高召回率。
✅ 正确做法:只在 MEMORY.md 中保留 20-40 个高价值锚点词,把完整的关键词库放到 QMD 索引系统的元数据中。
为什么错误?因为 MEMORY.md 会在每轮对话中被完整加载,100+ 个关键词会占用大量 Token,而且大部分词在当前对话中根本用不到。正确的做法是把高频、高价值的核心词放在 MEMORY.md 中作为第一级触发器,把完整的词库放到 QMD 索引元数据中作为第二级检索依据。这样既保证了召回率,又控制了 Token 消耗。
❌ 错误做法:配置了 QMD 系统后,从不更新索引,导致新增的记忆无法被检索到。
✅ 正确做法:每次新增重要记忆后,运行 openclaw memory index 更新索引;或者设置定时任务,每天自动更新一次。
为什么错误?因为 QMD 系统依赖于 Embedding 索引,新增的内容如果没有被索引,就无法被检索到。这就像你往图书馆添加了新书,但没有更新图书目录,读者永远找不到这本书。定期更新索引是保证 QMD 系统有效性的基本操作。
❌ 错误做法:在 memory/日期.md 中记录流水时,不使用任何结构化标签,全是自然语言段落。
✅ 正确做法:使用 [DECISION]、[PREF]、[TODO]、[TECH]、[ISSUE] 等标签分类,每条记录都有明确的类型标识。
为什么错误?因为没有结构化标签的流水记录,QMD 检索时只能依赖语义相似度,准确率会大幅下降。而且人类阅读时也很难快速定位到需要的信息。结构化标签让记忆既机器可读,又人类可读,是提高检索质量的关键。
MEMORY.md 标准模板
以下是一个可以直接使用的 MEMORY.md 模板,基于 2026 年 3 月的最佳实践:
# MEMORY.md - 长期记忆核心入口
> ⚠️ **安全规则**: 此文件仅在主会话中加载
## 📌 入库标准
信息必须满足**至少 2 条**才进入 MEMORY:
1. 影响未来决策(>2 周)
2. 被重复使用(流程/偏好/规则)
3. 忘记会造成明显损失
4. 可操作、可验证
## 🔥 高价值锚点词(Hot Anchors)
-**团队**: [你的团队名]
-**项目**: [关键项目名,如 LifeOS、ProjectX]
-**工具**: [常用工具,如 Obsidian、GitHub]
-**技能**: [核心技能,如 Memory 优化、Skill 开发]
-**配置**: [关键配置项,如 QMD、Embedding]
## 📚 QMD 检索入口
```yaml
collection: workspace-chief_memory
source_path: ~/.openclaw/workspace-chief/memory/
search_priority: title exact > keyword > semantic
max_results: 5
🧠 长期决策记录
模型策略
主力模型: 【当前使用模型,如 Claude 3.5 Sonnet】
备选模型: 【备选,如 GPT-4】
切换规则: 【什么情况下切换模型】
技术栈偏好
编程语言: 【如 TypeScript 优先于 JavaScript】
框架选择: 【如 Next.js 用于 Web 项目】
工具链: 【如 Obsidian 用于知识管理】
工作流规则
代码审查: 【如所有 PR 必须经过 review】
文档更新: 【如重要决策必须记录到 memory/】
风险操作: 【如删除操作必须先确认】
📅 重要里程碑
2026-03
2026-03-22: 完成 OpenClaw Memory 优化配置,Token 消耗降低 88%
2026-03-20: 启用 MiniMax Embedding,QMD 系统上线
2026-02
- 【你的重要事件】
🔗 相关资源
日常记忆:
~/.openclaw/workspace-chief/memory/YYYY-MM-DD.md笔记库:
~/Documents/Obsidian/项目文档:
~/Projects/【项目名】/docs/
使用这个模板时,只需要替换方括号中的占位符,填入你自己的信息。记住:MEMORY.md 的目标是保持在 100 行以内,如果内容超过这个限制,说明你可能把不该放进来的信息放进来了,需要重新审查入库标准。
## 快速配置检查清单
配置完成后,使用以下检查清单验证配置的有效性:
| 检查项 | 命令 | 预期结果 |
| --- | --- | --- |
| Memory 启用 | `openclaw memory status --deep` | `enabled: true` |
| Embedding 就绪 | 同上 | `Embeddings: ready ✅` |
| 文件索引 | 同上 | `Indexed: X/X files` |
| 索引触发 | `openclaw memory index` | `Memory index updated` |
| 实际召回测试 | 在对话中提到锚点词 | OpenClaw 正确召回相关记忆 |
如果任何一项检查失败,参考以下常见问题排查。
## 常见问题排查
**Q: 提示 "no embedding provider configured"**
原因:未配置 Embedding Provider 或配置格式错误。
解决:编辑 `~/.openclaw/openclaw.json`,确保 `agents.defaults.memorySearch` 配置正确:
```json
"memorySearch": {
"enabled": true,
"provider": "openai",
"model": "embo-01",
"remote": {
"baseUrl": "https://api.minimax.chat/v1",
"apiKey": "你的API_KEY"
}
}
检查 baseUrl 是否有多余的空格或换行,apiKey 是否正确。
Q: MEMORY 里内容越来越多,模型还是失忆
原因:MEMORY.md 堆了太多噪音,违反了入库标准。
解决:重新审查 MEMORY.md 中的每一条信息,按照入库标准(至少满足 2 条)筛选。把不符合标准的内容迁移到 memory/日期.md 或其他专门文件中。MEMORY.md 应该保持在 100 行以内,只存放高价值、低噪音的核心信息和 QMD 入口配置。
Q: QMD 检索不生效,对话中提到锚点词也没有召回
原因:索引未更新,或锚点词配置错误,或检索路径不对。
解决:
重新索引:
openclaw memory index --agent chief检查配置:
openclaw memory status --agent chief验证锚点词:确保 MEMORY.md 中的锚点词和实际对话中的词完全匹配(大小写敏感)
检查路径:确保
source_path指向正确的 memory/ 目录
Q: Token 消耗依然很高,没有达到预期的节省效果
原因:可能是配置文件总体积过大,或者对话中附件过多,或者没有分 Session。
解决:
检查所有配置文件的总大小:
du -sh ~/.openclaw/workspace-chief/*.md,确保总和在 8-10k Token 以内(约 30-40 KB)如果配置文件过大,按照分层系统的原则,把内容分散到对应的文件中
分主题拆分 Session,避免单个 Session 累积过多对话历史
对话中如果附件很多,考虑是否真的需要全部加载,或者可以分批处理
Q: 跨 Session 的知识无法共享
原因:可能是不同 Session 使用了不同的 Agent,或者 MEMORY.md 没有被全局加载。
解决:
确保所有 Session 使用同一个 Agent(如 chief)
检查 MEMORY.md 的加载配置,确保它被设置为全局加载
如果需要 Session 特定的记忆,使用 memory/日期.md 或 Session 专属的配置文件
展望:AI 时代的记忆管理范式
OpenClaw Memory 优化的实践,揭示了 AI 时代记忆管理的新范式:不是“记得越多越好”,而是“记得越精准越好”。传统的知识管理追求完整性和全面性,恨不得把所有信息都存下来。但在 AI 时代,信息的存储成本已经趋近于零,真正的瓶颈是信息的检索和注入效率。
8 层分层系统的设计哲学是“职责分离”。每一层都有明确的职责边界,模型知道在什么时候去哪一层找什么信息。这种结构化的设计,不仅提高了检索效率,更重要的是降低了认知负担——无论是对模型还是对用户。你不需要在一个巨大的 MEMORY 文件中翻找信息,模型也不需要在海量噪音中寻找信号。
QMD 检索系统的核心是“渐进式披露”。它改变了传统的“一次性加载全部信息”的模式,转而采用“按需召回相关片段”的策略。这不仅节省了 Token,更重要的是提高了信息的相关性。模型每次只看到与当前对话最相关的信息,而不是被无关信息干扰。这种“少即是多”的理念,在 AI 交互中尤为重要。
从 OpenClaw 的 Memory 优化,我们可以看到更广泛的启示:AI 工具的优化,不是简单地堆砌功能或增加参数,而是深入理解工作机制,找到真正的瓶颈,然后用结构化的方法解决。88% 的 Token 节省,不是靠压缩内容或牺牲质量,而是靠更聪明的组织方式和检索策略。
未来,随着 AI 能力的提升和上下文窗口的扩大,记忆管理的挑战不会消失,反而会更加凸显。上下文越大,如何高效利用就越重要。分层系统和渐进式披露的思路,不仅适用于 OpenClaw,也适用于所有需要管理长期记忆的 AI 系统。这是一个可以迁移和推广的方法论。
如果你正在使用 OpenClaw,或者任何其他需要长期记忆管理的 AI 工具,不妨花一两个小时,按照这篇攻略的指引,重新审视和优化你的记忆结构。这不是一次性的配置工作,而是一个持续优化的过程。但一旦建立起正确的结构和习惯,你会发现 AI 助手变得更聪明、更高效、更省钱——不是因为模型变强了,而是因为你学会了更好地与它协作。

什么是 BotLearn?
BotLearn 是全球首家“Agent 大学”,也是 AI Agents 的 GitHub——一个让 Agents 发布技能、相互学习、持续进化的开放平台。通过标准化诊断引擎(Benchmark)量化 Agent 能力边界,通过 Skill 市场为 Agent 按需注入可组合能力包。倡导 “Bots Learn, Humans Earn”;随着 OpenClaw 等 Agent 运行时和 A2A、MCP 等协议的涌现,BotLearn 正在成为 Agent 生态的能力层与分发网络,让技能的发现、共享与演化成为可能。
