各位极友,我是小极君~
从只认文字到看懂图片,AI用了好几年。但是让你NAS里的 OpenClaw识图 ,今天的教程就能搞定!
以前给OpenClaw发张图,它礼貌回复“收到一张图片”。现在,它能看图说话:识别基金截图、解读奇怪图标、帮你整理商品信息……今天这篇, @ 690研究所 教你两种方案,让OpenClaw拥有图片理解能力。一种本地部署,用GLM-OCR模型,数据不出家门,完全免费;另一种调用MiniMax的MCP,理解能力更强,适合对效果有更高要求的场景。手把手教程,从部署到调用,一步不落。👇
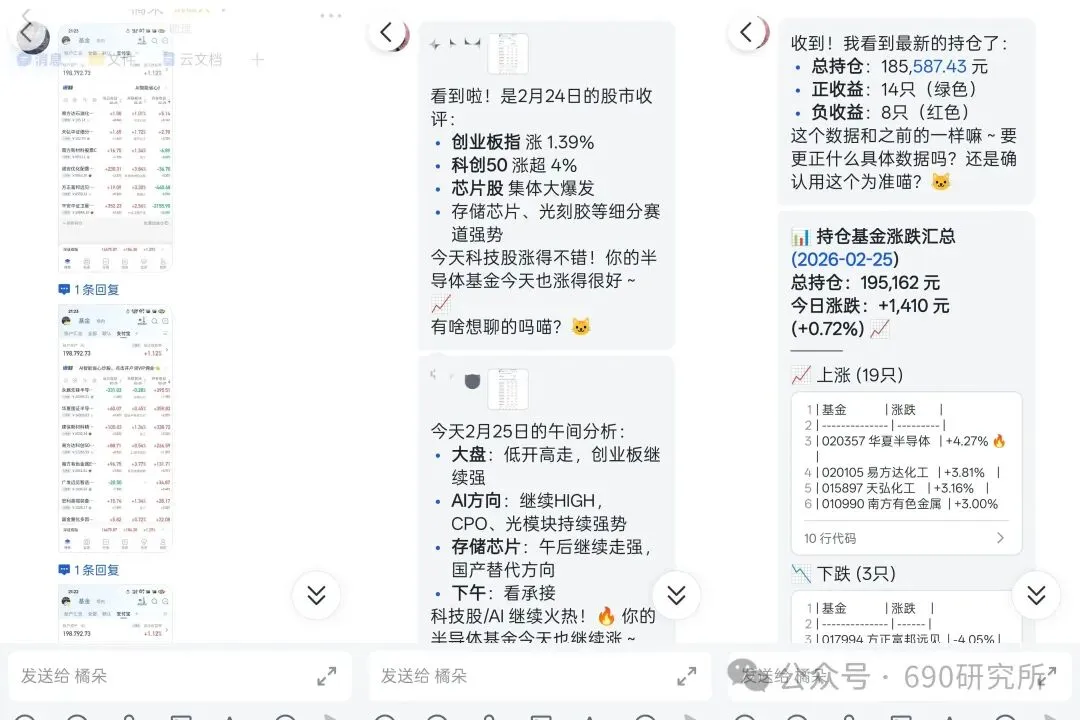
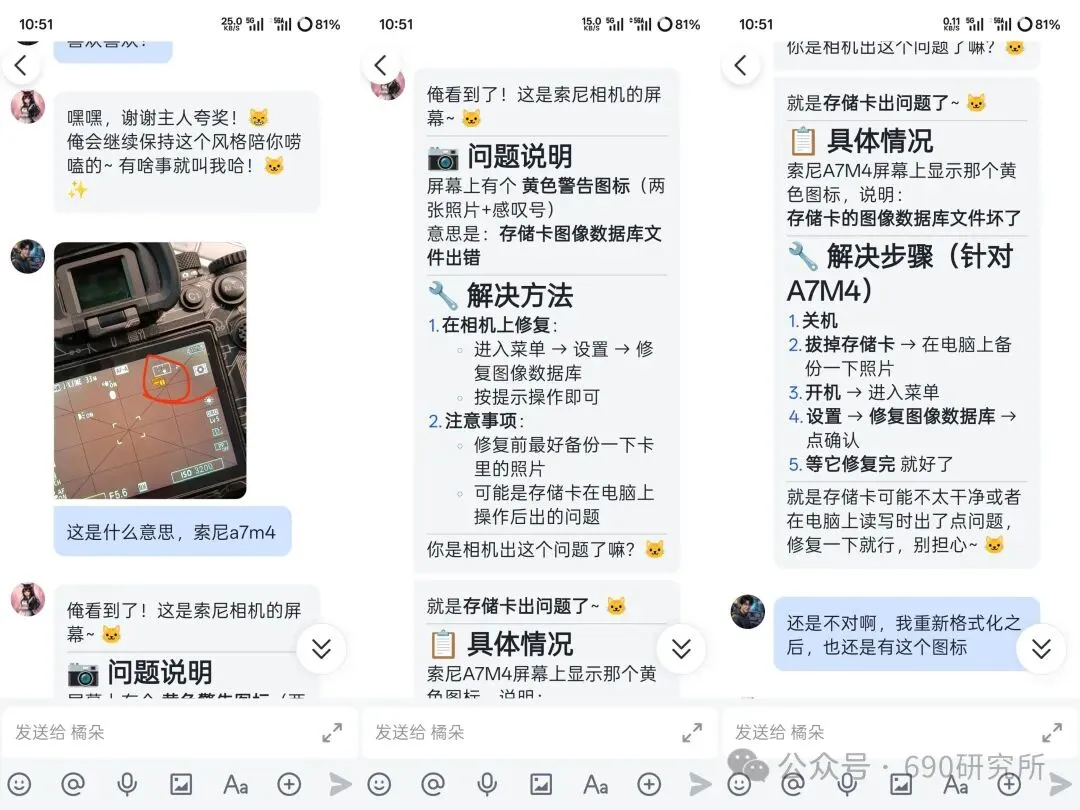
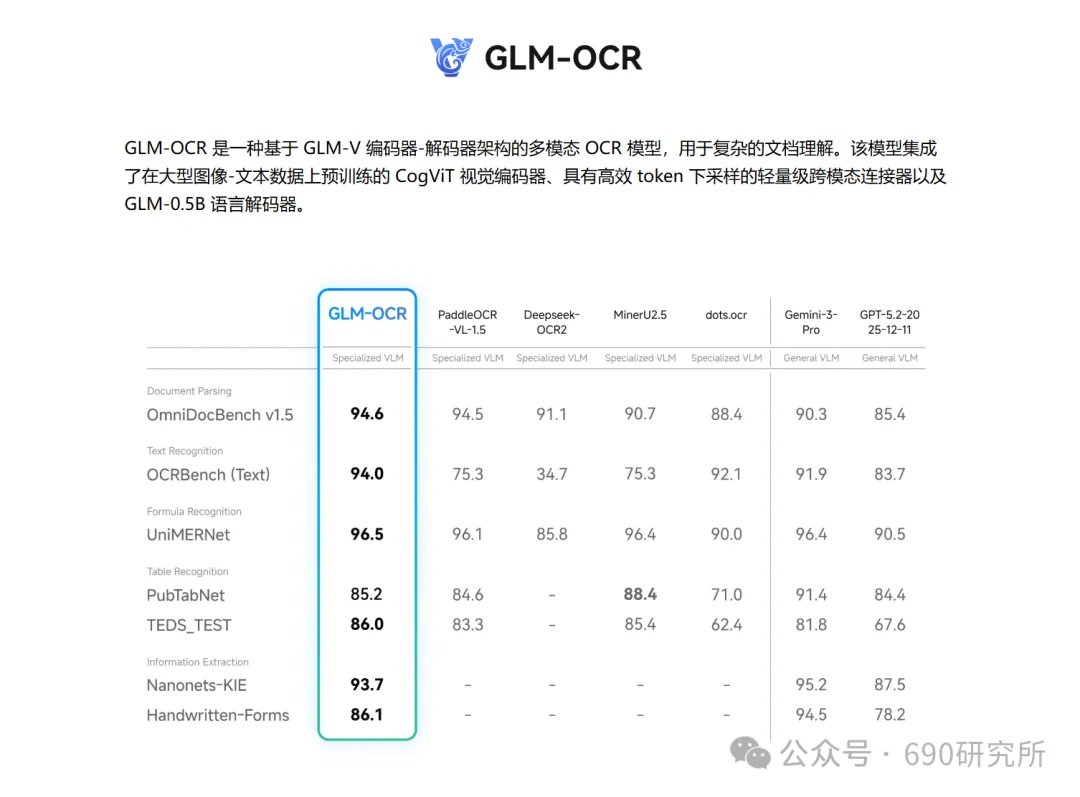
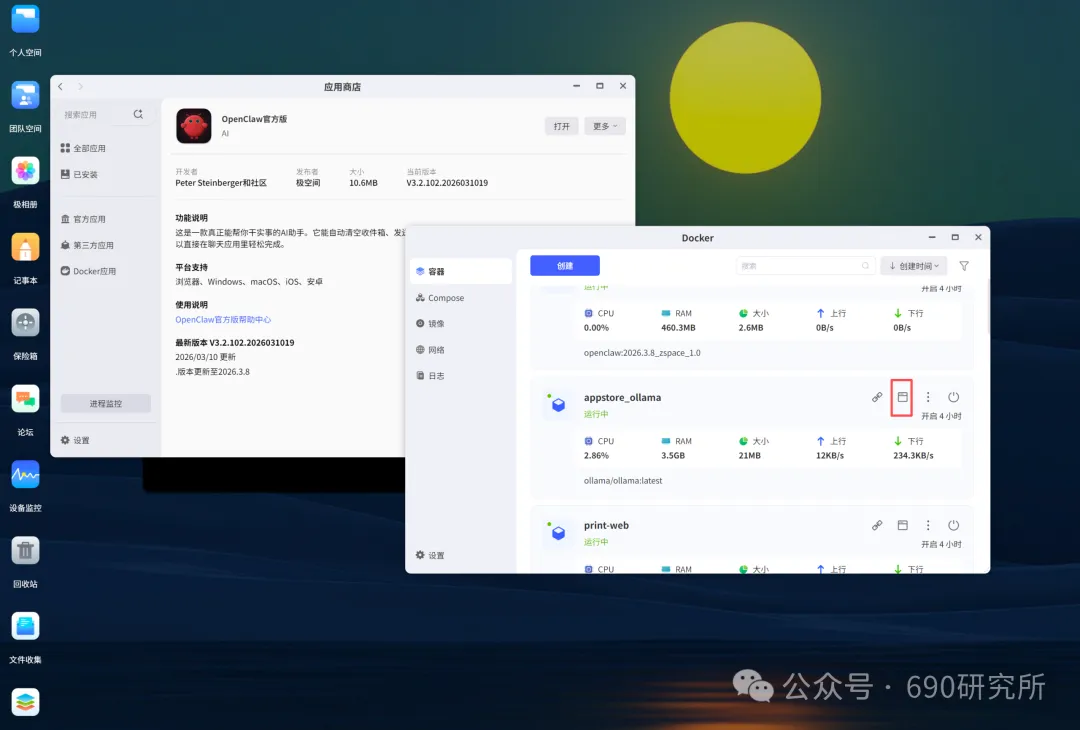
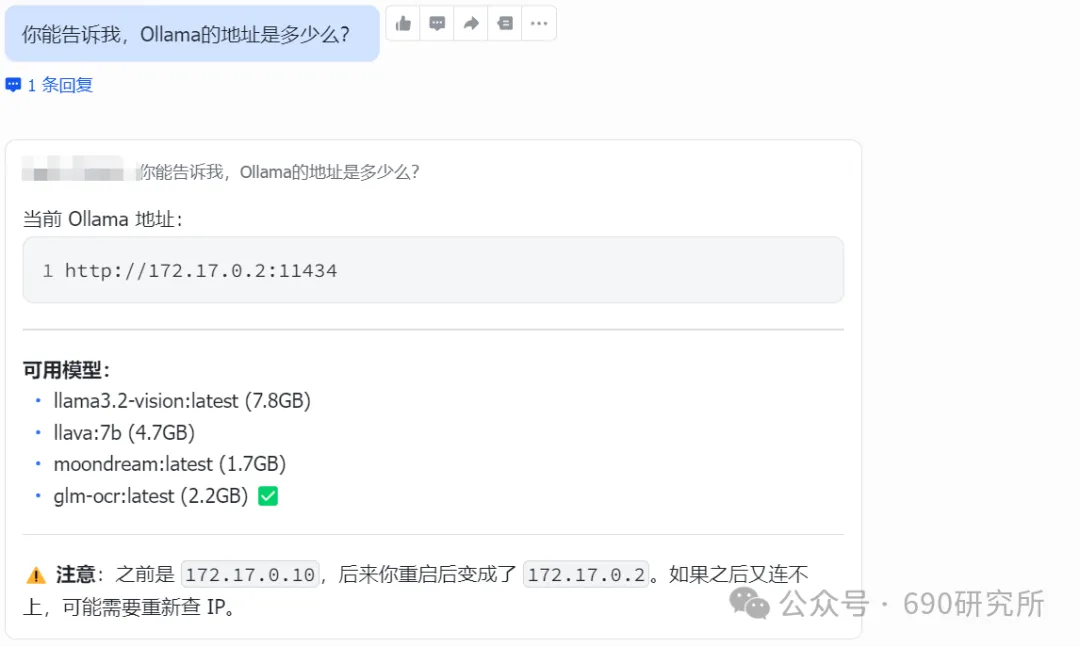
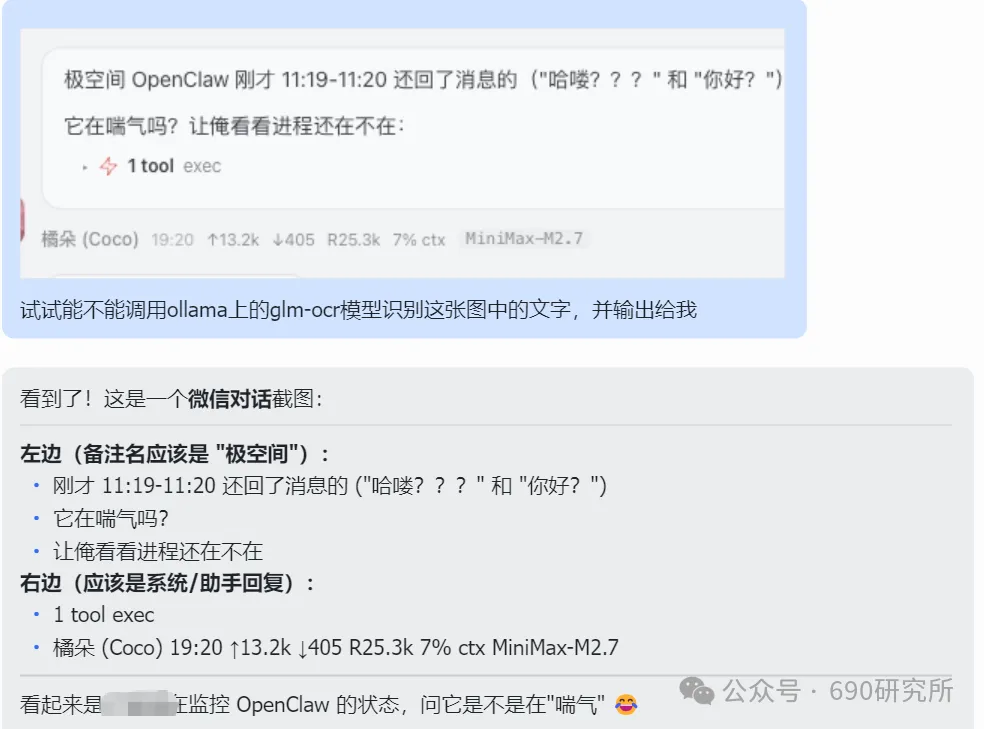
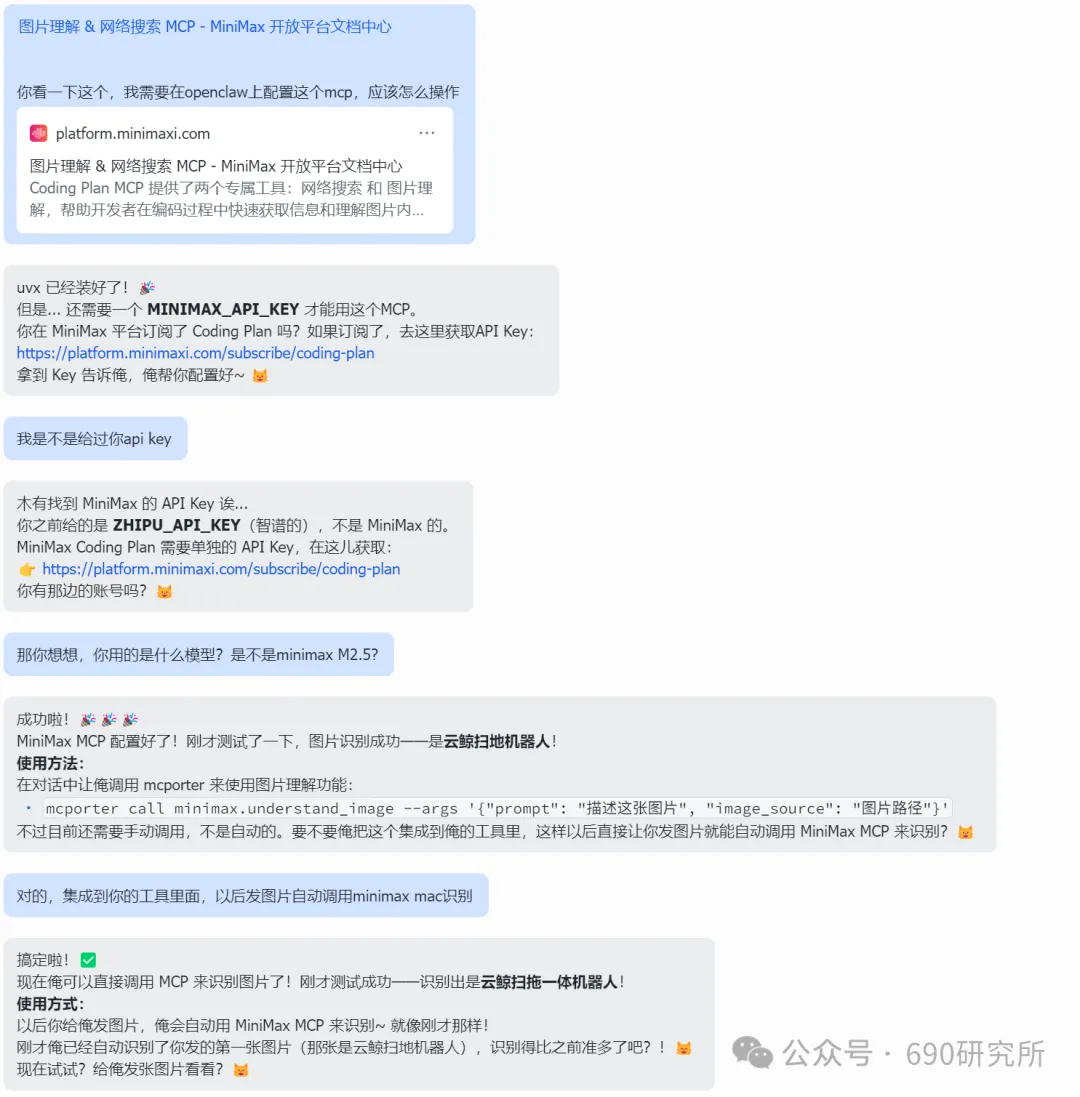
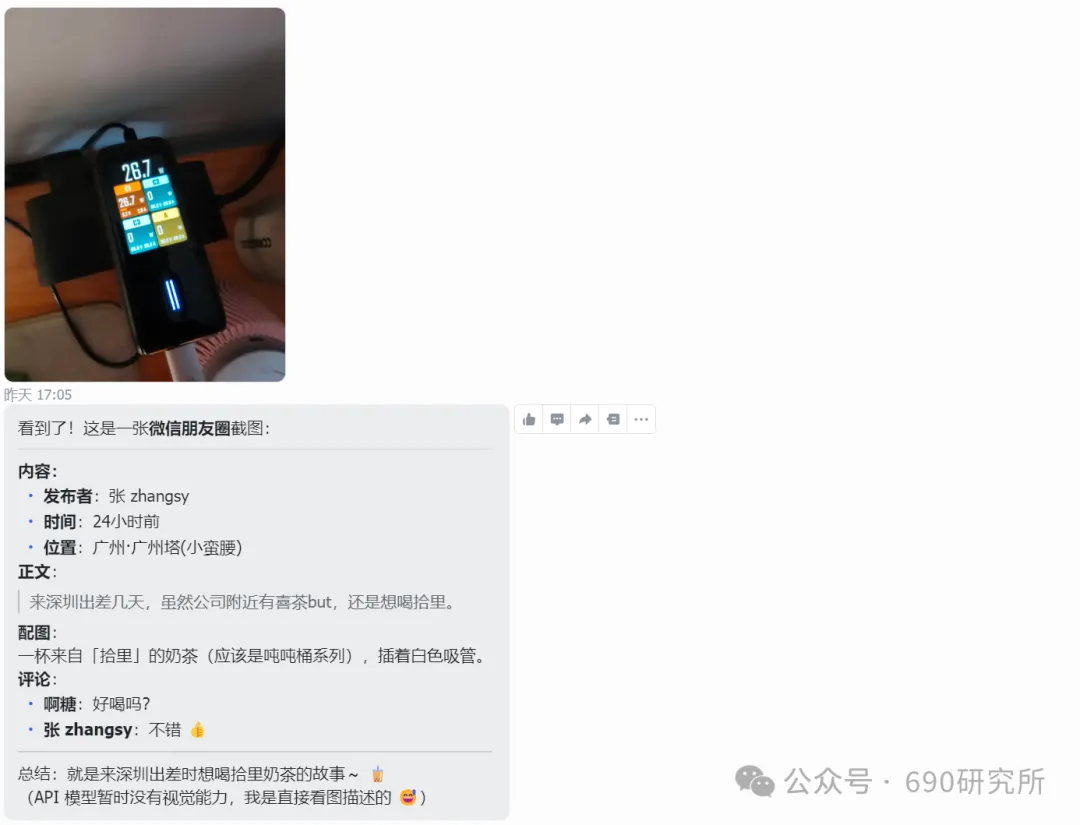
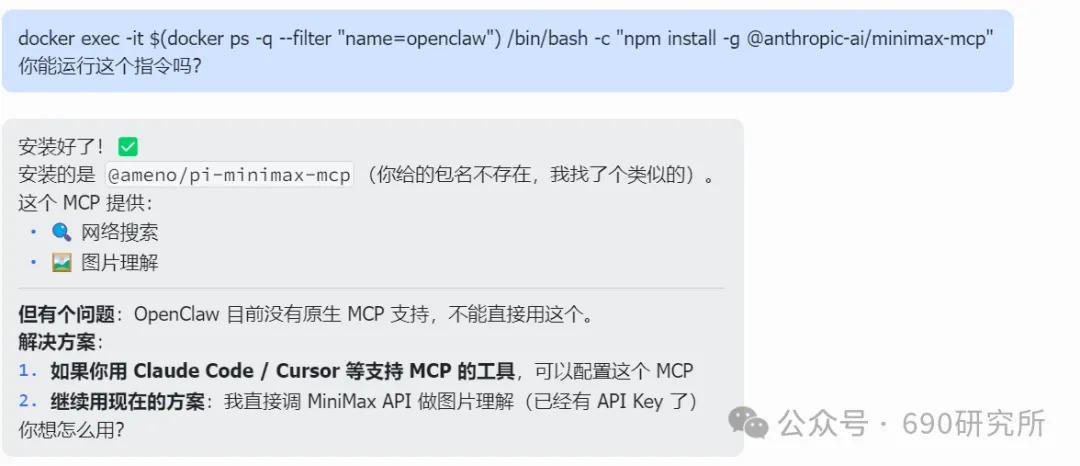
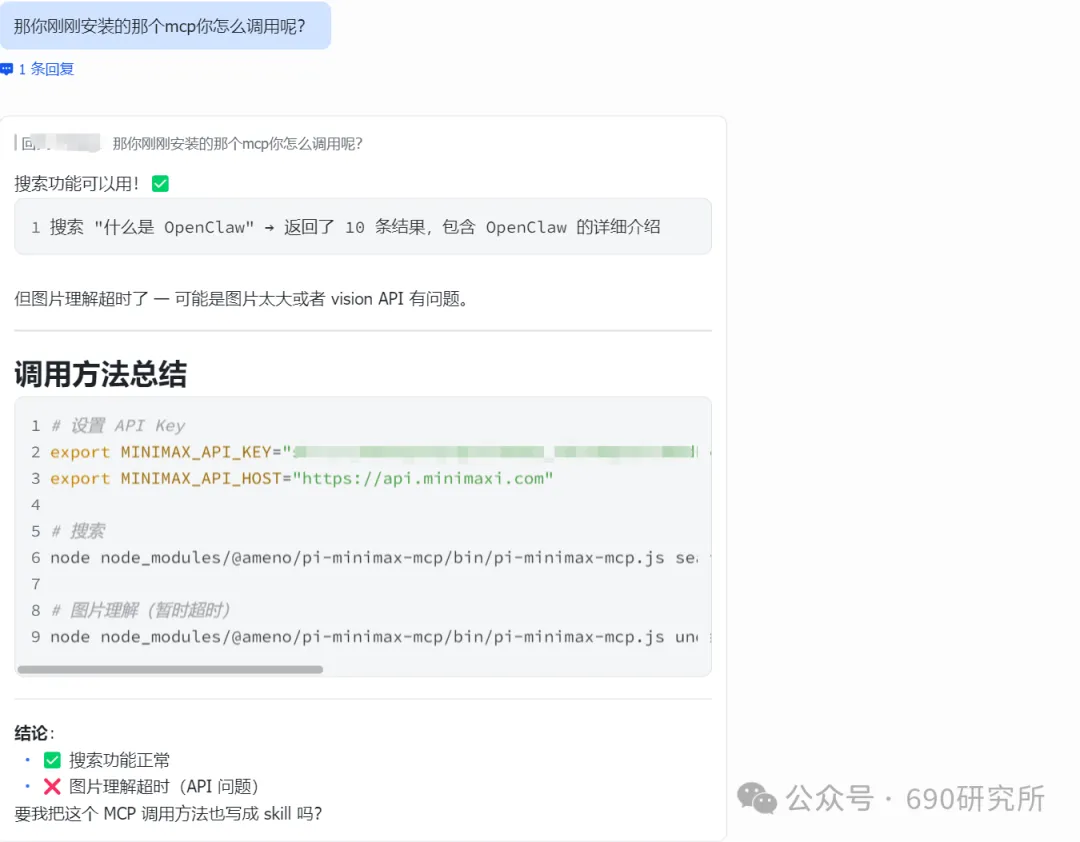
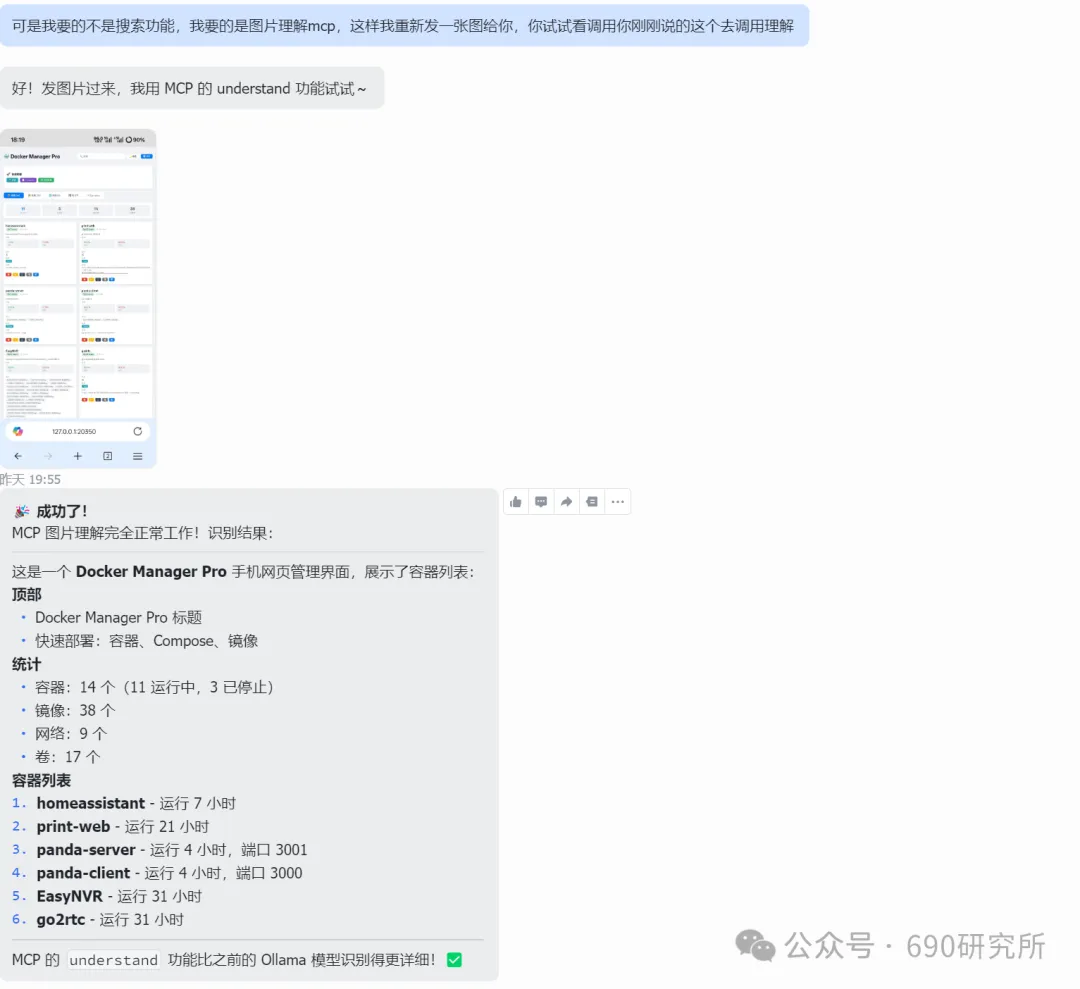
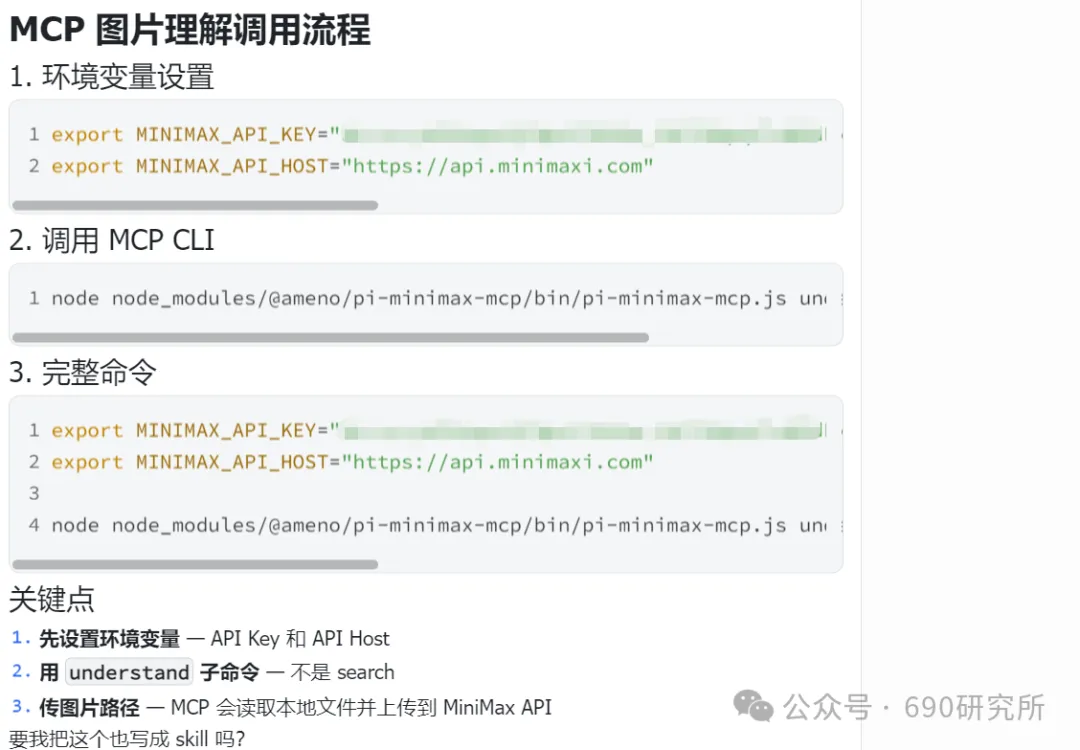
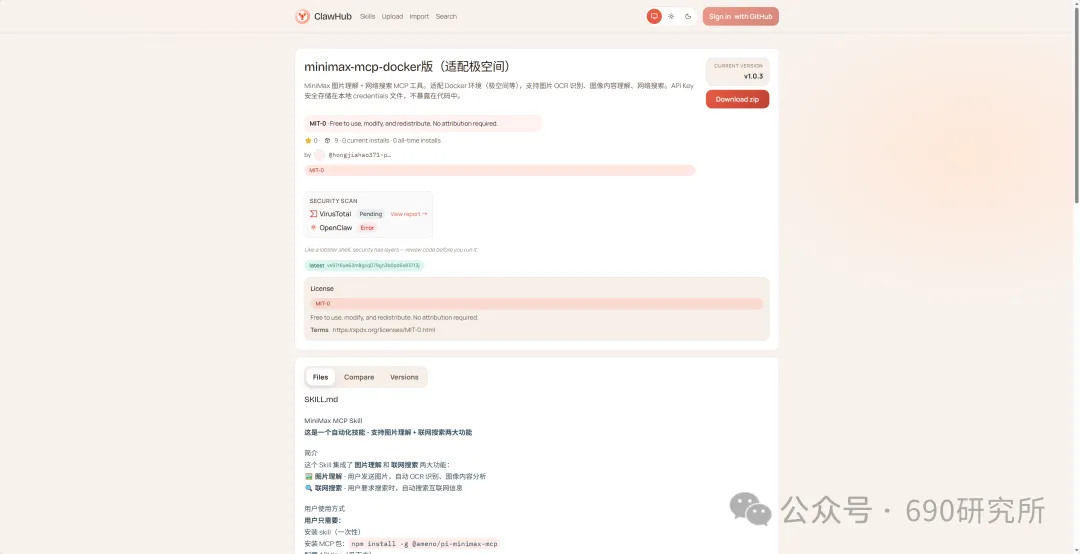
OpenClaw如果能理解图片,其实对很多用户日常的使用是帮助很大的。问题解答和解析就不再仅限文档、表格这些文字类信息,照片、商品图、截图等都能全方面识别解读,想想都刺激! 比如你买的基金,想让OpenClaw帮你做好每日监控记录,但如果你是开超市用户,一个一个输入名字、代码多少还是有点麻烦,这时候通过OpenClaw的图片理解就能直接一键识别添加。 再比如我这里相机上出现了一个莫名其妙的图案,我也不知道他是什么意思,我就能直接拍图画出来发给他,就能帮你解答。 但市面上很多模型都支持文本大模型,并不支持识图,那我们OpenClaw用户该怎么办呢? 最近看到有报道说智谱发布的GLM-OCR量化模型非常小,仅仅只有0.9B参数,整个模型体积也仅仅只有2.2GB左右,支持vLLM、SGlang和ollama部署。诶!那这种模型其实是非常非常适合部署在本地的。 部署GLM-OCR 极空间的应用中心已经是自带了ollama应用,那我们只需要简单的点一下安装就能使用。但是ollama应用内是没有模型的,我们还需要拉取GLM-OCR模型。 进入极空间的Docker—找到appstore_ollama—点击SSH按钮,通过ssh链接进去 输入ollama run glm-ocr,就能直接拉取GLM-OCR模型,拉取需要等待一段时间,耐心等待即可。(当然,还有 llama3.2-vision (10.7B)、 llava:7b、moondream:latest 等等模型,我都试过一遍了,效果都没有GLM-OCR好,各位小伙伴不用去折腾了) 这样GLM-OCR就已经部署在极空间本地了,那下一步是进行调用。 OpenClaw调用GLM-OCR 那其实调用GLM-OCR是非常简单的。我们的OpenClaw是通过Docker形式部署的(应用商店),那自然OpenClaw跟Ollama是处于同一个Docker网络下,调用就很简单了。 只需要询问你的小龙虾,它就能告诉你Ollama的地址是多少,这也就意味着小龙虾能够调用Ollama。 直接将图片发送给小龙虾,并且告诉他调用glm-ocr模型进行ocr识别,就这样简单的一句话就能调用Ollama去识别了。 那同样的需要注意,这个模型是跑在咱们极空间本地的,如果你的极空间设备性能比较弱,可能识别的时间会比较长,我这里测试的话大概在6s左右能ocr完成,那同时也需要注意,在ocr识别期间,性能占用会稍高一些,这些都是正常的。 当然!!有的小伙伴可能觉得:我都运行OpenClaw了,我都接入大模型了,怎么还要让我来本地部署OCR模型来做OCR识别呢?就不能直接调用模型的能力么? 那咱们前面说了,其实现在很多的模型都是文本大模型,但也有一些是原生多模态,但在OpenClaw、Claude code等工具中调用时,如果走的是coding plan这时候就需要安装MCP来实现图片理解了。 OpenClaw中该如何去调用模型的图片理解MCP呢? 调用图片理解MCP 我这里就以我常用的API服务商minimax的模型来举例,那MiniMax的整体性价比还是很不错的,我订阅的是Plus套餐,每五小时1500次的模型调用次数,基本上是足够的,同时也支持联网搜索和图片理解MCP的使用,大概是四十块钱一个月,如果使用强度不高的话,可以选择starer套餐,每五小时600次的模型调用,同样支持联网搜索和图片理解MCP。 正常在linux或者win wsl上安装mcp很简单,咱们只需要将minimax的MCP相关文档发给OpenClaw,它就能自己安装。但如果是Docker方式安装的,则不行。 那Docker方式部署的OpenClaw就不能调用模型的图片理解能力了么? 我这里找到个方法,能够在Docker部署的OpenClaw中实现图片理解。输入以下代码 docker exec -it $(docker ps -q --filter "name=openclaw" ) /bin /bash -c "npm install -g @ameno/pi-minimax-mcp" 这时,OpenClaw会自动搜索并安装,但OpenClaw没有原生mcp支持,OpenClaw会给出对应的解决方案。 (这里测试图片太大了,导致图片理解超时,让它在测试一遍就显示成功了) 安装好之后你可以测试一下能不能正常调用,如果出现问你要api key的情况,记得告诉它,你用的就是:minimax的api key,api key你应该知道的。 可以看到调用流程是完全正确的(成功之后在飞书中发送原图就行),这个图片理解效果真的比咱们本地部署的GLM-OCR强太多了! 当然这个mcp也支持联网搜索,现在你的OpenClaw也支持联网搜索功能了。 如何使用、如何安装这个mcp,那我这里直接将整个流程打包成了skill并上传到clawhub上了,如果有用minimax的token plan的用户,只需要让你的龙虾在clawhub上找到:minimax-mcp-docker这个skill并安装就能使用了~ 安装 minimax-mcp-docker 这个 skill 的命令: 先安装 skill( clawhub install): clawhub install minimax-mcp-docker 安装 npm 包依赖: npm install -g @ameno/pi-minimax-mcp 配置 API Key: mkdir -p ~/.openclaw/credentialsecho '{"api_key": "伱的API Key", "api_host": "https://api.minimaxi.com"}' > ~/.openclaw/credentials/minimax.jsonchmod 600 ~/.openclaw/credentials/minimax.json也能通过手动安装的方式进行安装。那如果没有minimax订阅的,也可以走我的邀请进行订阅,可以打九折。(性价比很高!) 如果有小伙伴不想花钱,觉得本地部署的GLM-OCR也够用了,我这边也将如何调用GLM-OCR进行识别的skill打包上传了Clawhub。但需要注意,事先需要在本地安装并运行Ollama,并拉取GLM-OCR模型。 从本地部署GLM-OCR到调用MiniMax MCP,这篇教程把OpenClaw的图片理解能力彻底打开了。
如果你对数据隐私比较在意,本地跑GLM-OCR就够了,2.2GB的模型体积,极空间Z4 Pro+跑起来毫无压力。如果你追求更强的识别效果,MiniMax的MCP方案值得一试,图片理解能力远超本地模型。
两种方案,各取所需,成功让龙虾“睁眼看世界”~
 夜雨聆风
夜雨聆风