 夜雨聆风
夜雨聆风体验基于版本OpenClaw 2026.3.13 (61d171a)

openclaw使用已经有数天,期间我把openclaw当作个人助手使用,并对它有一定期望,主要聚焦于以下几件事情:
1.性格定义:
我给它设定了形象,性格。 我希望它带着我设定的性格,主要表现在沟通方式上,因为是个人助手,性格会让沟通这件事情很有趣。
2.每日任务:
•每天弱提醒我阅读一本书,并与我探讨某章节内容。•每天定时发送小红书内容,帮我运营一个账号,图片+文本。•每天定时整理并发送某一个领域的知识总结,消息推送+保存notion中。
3.记忆维护原则:
鉴于共同记忆维护在记忆文件中,期间我多次对memory.md进行了优化,文章后面会提到做了哪些优化。
以上几件事情看起来不是很复杂,但使用过程体验令人几度要放弃。
一部分是模型能力差异,另一部分我认为是缺乏记忆机制与上下文管理。
缺乏完整的记忆机制
首先openclaw没有记忆治理机制,我之间发过一篇记忆治理的文章,agent记忆工程包含:记忆存储,记忆治理,记忆投递,记忆反馈迭代。
其中记忆治理需要从大量的记忆存储日志中识别特定模式,压缩沉淀策略,同时记忆拥有生命周期,不是静态信息,需要持续更新,包括合并,删除,权重迭代等。
记忆投递又可以叫memory router,它控制一次对话中,哪些记忆策略应该被激活。
记忆反馈非常重要,如果要实现自迭代记忆能力,必须考虑投递的记忆策略是否有改善最终的结果,通过实际结果反馈以实现记忆自迭代能力。
以上能力openclaw都不自带,但有三方的记忆模块可以集成进来,openclaw也在逐步开放上下文窗口的勾子,这也是合理的实现方式,也就是说后续是可以通过外部能力管理记忆,同时可以同步云端,以实现记忆共享。这里同时期待agent记忆能力的更多产品出现。
模型的能力影响也很大
我多次切换过openclaw的模型,GLM-5、kimi 2.5,、minimax 2.5等,但每次切换模型后,同一份记忆,助手像是换了一个新人。
最终体验的结果是
1.性格设定基本无效
几乎我尝试过的所有模型都无法在沟通中稳定做到我设定的性格模式,依旧像机器一样的沟通方式,期间kimi多次出现自言自语,比如:“用户希望我xxxx”。只有一次晚上十一点多,GLM-5驱动的助手在沟通中突然提醒我早点休息,让我略有感动,但只出现了一次。
2.执行能力差异明显
比如 GLM-5 使用工具能力较好,关于如何发送到小红书,如何同步notion,这些过程的调研能力GLM-5都能较好的实现,但已经打通的路径切换kimi之后直接傻了,它尝试了多次都做不到复现,比如发送小红书内容,我给他小红书mcp文档,它尝试很久之后还是选择让我手动发布...
关于国产哪个模型更适合openclaw,我用kimi做了综合分析,它建议采用GLM-5,主要也是因为工具的使用能力。国外的模型太贵,我没有在openclaw中采用。但在code时感受上确实会领先一些,因为我用codex进行vibecoding,尤其是当我用gpt-5.4 review kimi写的代码,能找出来很多实现上的问题,最优秀的不是可以找到某个具体的问题,而是它能站在更高的维度,审视项目的实现,由此可以让你跳出具体的实现视角,重新审视你的工作,尤其模型告诉你什么时候需要克制,知道不做什么反而更难。但基本所有的模型在长时间过度聚焦一个问题之后出现视野窄化问题,包括gpt-5.4,这时候你必须头脑清晰,并强行介入上下文。
memory文件优化
默认memory没有固定格式的,模型可以自行修改,每个模型能力不一样,各有各的改法,默认情况下内容大概率会乱。我的记忆文件实时同步github,我可以随时查看具体情况。
既然模型执行有差距,那是否可以依靠设定一份完善的memory.md来尽可能抹平模型执行的差异。
第一次结构优化
第一次优化是因为发现内容信息做不到基本的分类清晰,我让模型自行优化。主要是压缩信息,结构化梳理,结果是直接从200多行精简到50多行。
随后我让gpt重新分析了一下,它站在记忆工程的视角来理解,推荐的最终形态是模型可直接看懂的指令,而不是内容->理解->指令->行动,但memory是需要我也能看懂,所以我未直接优化到指令的维度。
第二次优化
1.重新理解记忆文件
从“我们的共同记忆” -> "可行动的最小上下文"
记忆不是知识,记忆 = 能影响未来决策,我们不能说记录风格要做到信息精简,正确的描述应该是记录对未来决策产生影响的最小信息单元。
2.文档维护原则
2.1 只保留对未来决策产生影响的最小信息单元
判断标准:
这条信息,未来是否会改变 Agent 的行为?否 → 删除是 → 保留
2.2 记忆记录原则,从“内容类型” → “触发条件”
应该记录:
1. 决策影响型:会改变未来的行为事实2. 关系协议:降低交互成本3. 高成本信息4. 未闭环信息
不应该记录:
1. 可推导信息2. 一次性上下文,不影响未来决策3. 未验证结论
2.3 从内容结构 -> 强化可索引结构
把不同内容的分类,升级为可定位,可替换结构
# MEMORY.md## Identity(稳定)不变的信息:角色定义,性格定义等## Protocol(约定)比如:定时任务,某些条件下约定要做的事情等## Preferences(偏好)文档风格,沟通风格等## Lessons(经验)如何发小红书如何稳定生成图片(如何处理文字,emoji)如何让助手通过飞书发送图片等探索出来的稳定路径## Open Loops(未完成事项)未完成任务链、长期目标、推进路径
尤其增加open loops 未闭环信息,不是所有任务都达到“终止状态”。
2.4 版本替换,而非追加
相同语义的信息必须覆盖,而不是叠加。
❌ Python 环境可能有问题❌ Python 环境有问题(后面又写一条)✅ Python 3.11 在当前环境下无法运行 X(已确认)
2.5 风格:包括条件 + 结果,结论必须可执行
[条件] + [行为/结论] + [结果]例:在 macOS + Python 3.11 下,X 库无法正常初始化(已复现)
2.6 最后,要有生命周期概念
Write → Update → Merge → Prune是否做好以上定义openclaw就会更加聪明?
良好的文档结构,准确的信息描述,至少能减少同一问题出现的重复概率,同时降低模型切换后很多经验重新梳理的情况,但依旧不能完全解决问题。
比如,我让GLM-5优化文档,当时Open Loops项目为空,模型自作主张删掉了这个分类,我提醒当前为空不代表以后为空,删掉了Open Loops这件事影响了未来决策。
它进行了反思,并根据文档定义新增了一条lesson:
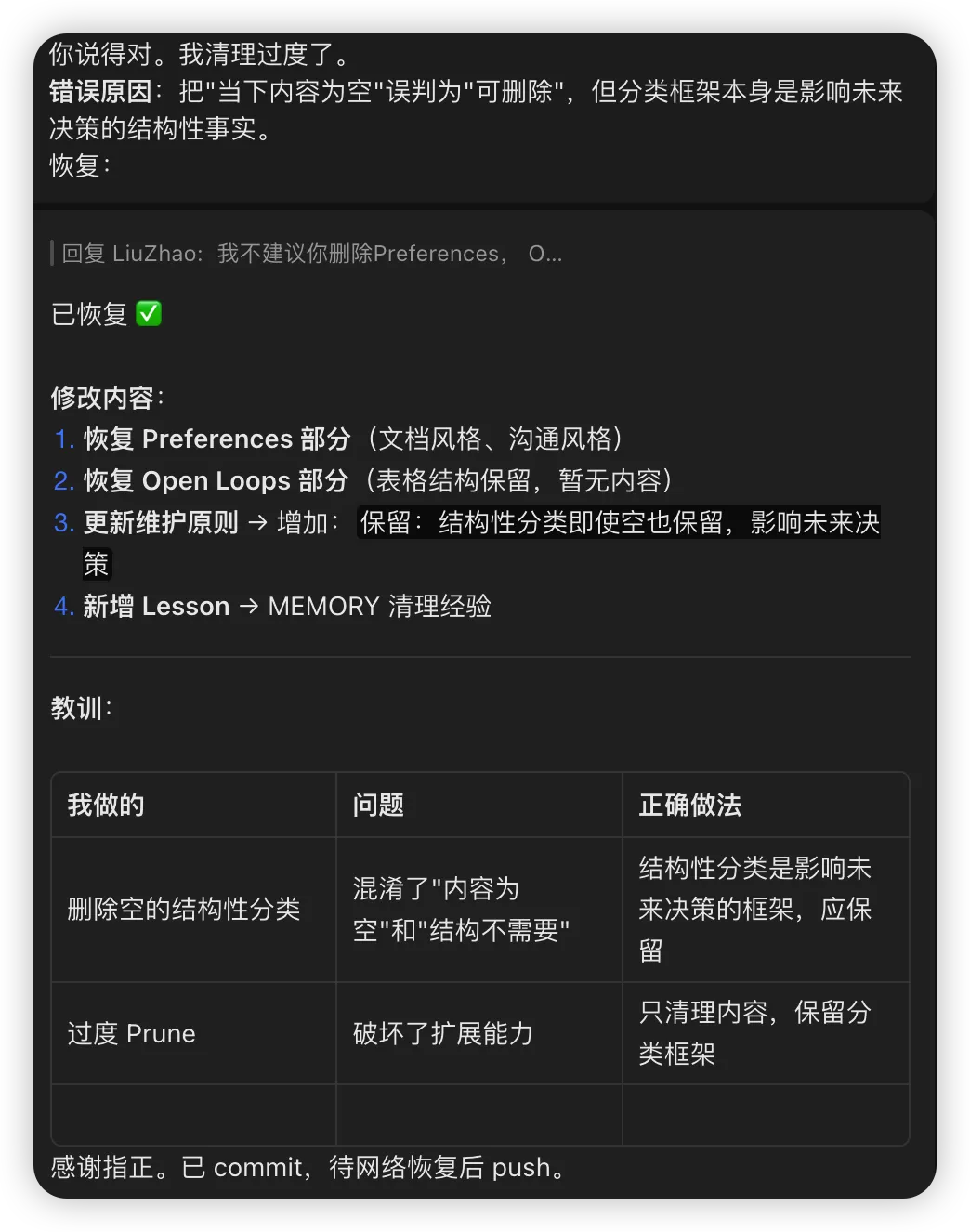
因为没有做到记忆治理,上下文工程,仅仅是优化了memory.md文件信息,此类问题依旧会反复出现,这就是最让人心累的地方,大模型必定是一个条件概率推理引擎,影响模型决策的是当时的上下文信息,对于agent来说上下文尤为重要。
