 夜雨聆风
夜雨聆风为什么市面上很多AI Agent能跟你侃侃而谈,一干活就翻车?
是模型不够聪明?是工具不够多?
都不是!是因为推理链没跟上。
如果把大模型比作发动机,推理链就是变速箱和方向盘。发动机再强劲,车子还是跑不起来。
模型决定上限,推理链决定下限。
一、初始形态:单步思考的原生推理
二、工具化突破:ReAct循环驱动的双步推理
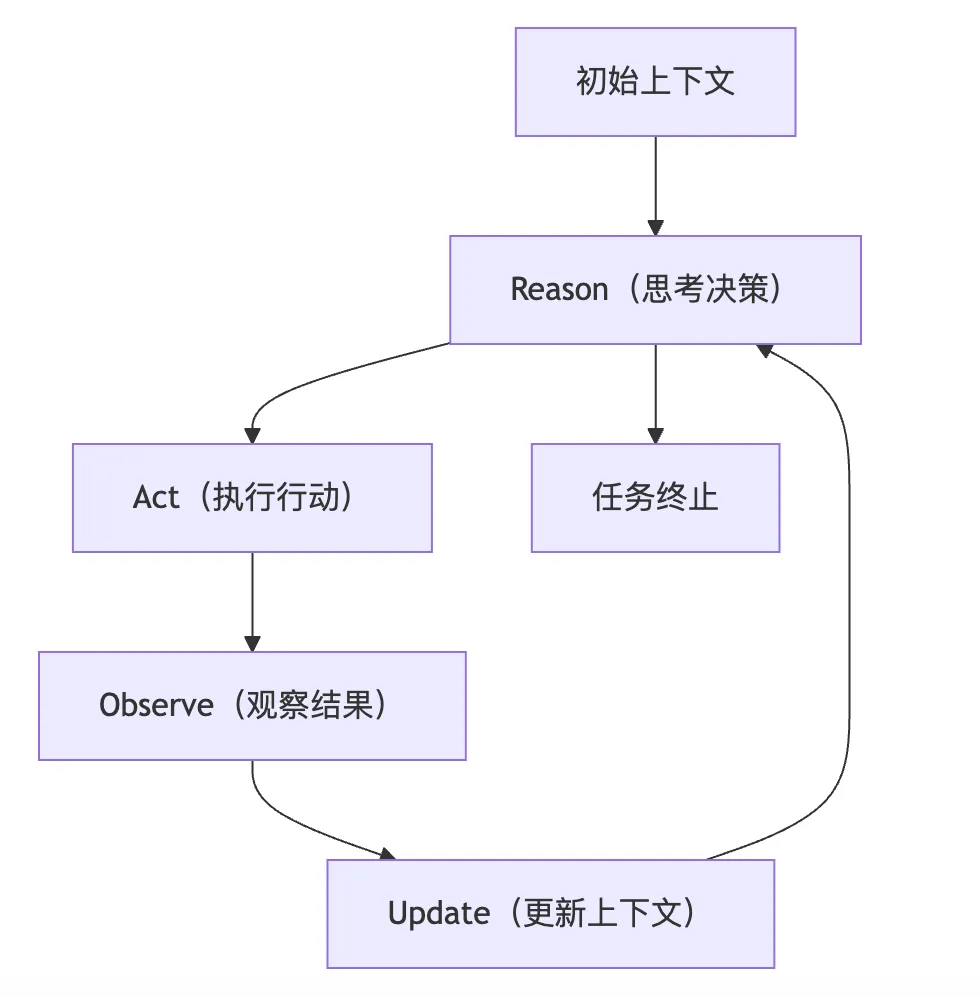
Reason:LLM 基于当前上下文,判断 “是否需要工具、用什么工具、参数是什么”; Act:Agent Runtime 执行工具(文件 / 浏览器 / API/Shell),返回结构化结果; Observe:将工具结果回填上下文,作为下一轮推理的依据; Loop:重复直至任务完成或达到最大步数。
Lane Queue串行车道:为每个用户会话分配一个独立的执行队列,同一车道内任务严格串行执行,彻底消除并发竞态与状态冲突,确保每一次推理执行的可复现性; 工具沙箱隔离:所有工具调用都只能在Docker沙箱环境中运行,沙箱与宿主系统权限严格隔离,便面如恶意读取系统文件等工具越权操作,提升执行安全性; 单次循环状态持久化:每一轮 ReAct 循环执行后,都会将当前会话状态(上下文、工具调用记录、推理结果)落地存储,支持任务中断后重新恢复,避免重复执行。
三、规划化突破:Plan-and-Execute的分层多步推理
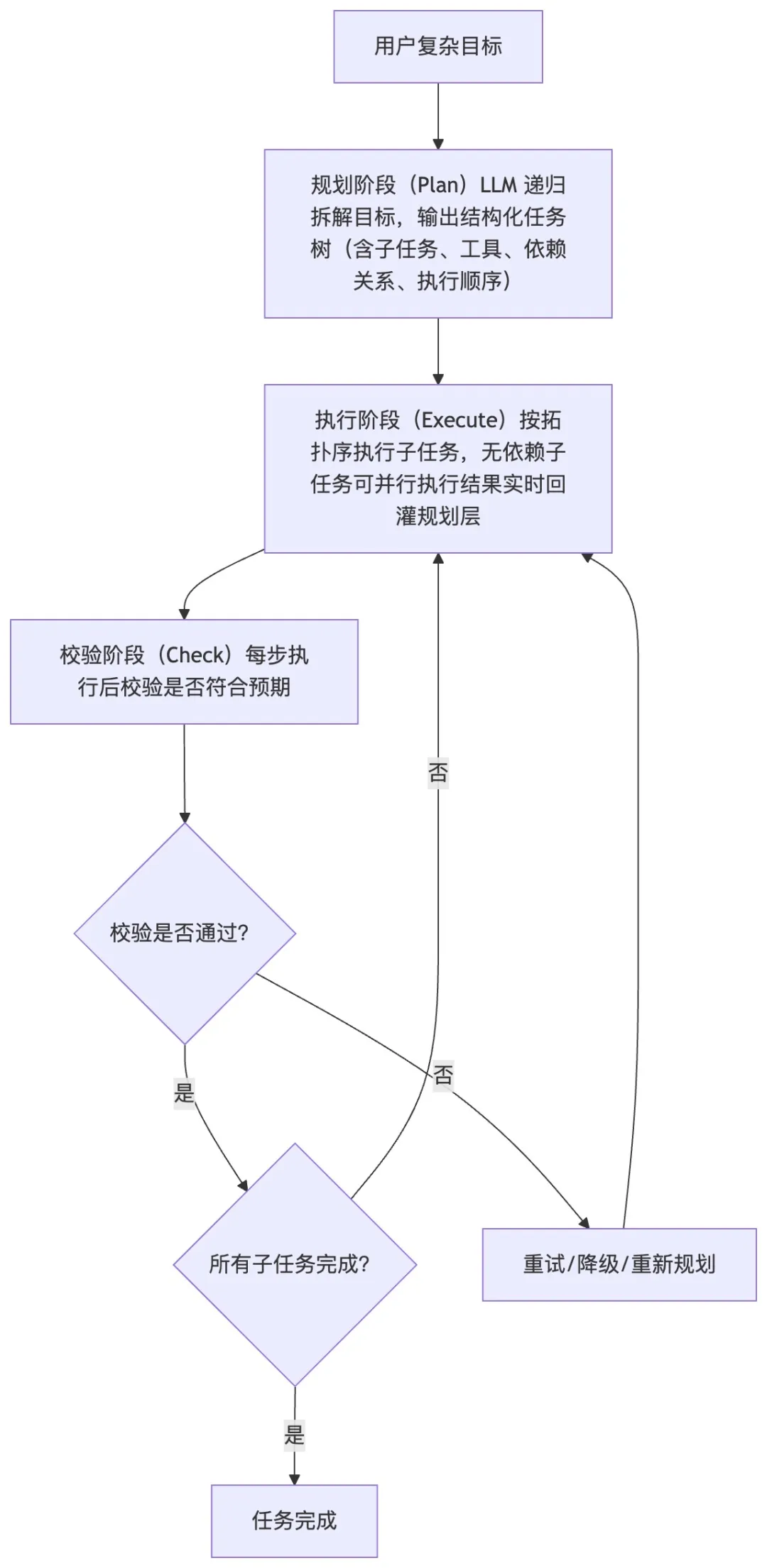
任务分解算法:基于LLM上下文理解能力,将高层复杂的目标递归拆解为原子级子任务,并明确每个子任务的优先级、依赖关系等; 动态调度机制:基于子任务的依赖关系、资源占用情况、执行耗时等来动态调整执行顺序,任务中断后还支持继续执行; Context Engine 上下文引擎:构建了三级记忆体系:工作记忆、短期记忆、长期记忆,通过Token预算分配机制来动态压缩上下文,优先保留系统指令、核心约束,避免上下文窗口溢出; 生命周期钩子:提供了【规划前、执行中、执行后、回滚后、任务终止前】5个钩子接口,便于开发者对生命周期进行管理,实现日志上报、异常拦截等逻辑。
四、 智能化突破:混合推理与自适应推理链
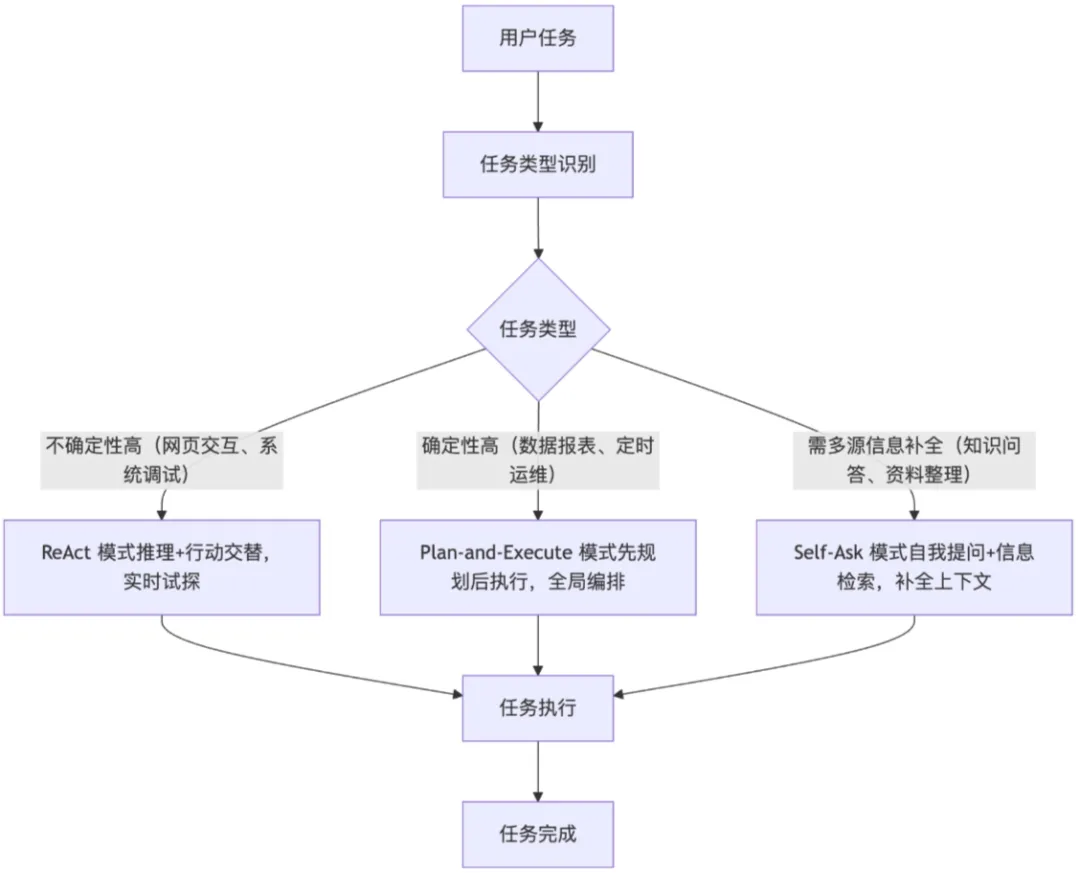
ReAct 模式:推理 + 行动交替,适合不确定性高、需要实时试探的任务,比如网页交互、系统调试等; Plan-and-Execute 模式:先规划后执行,适合确定性高、流程固定的任务,比如数据报表、定时运维等; Self-Ask 模式:自我提问 + 信息检索,适合需要多源信息补全的任务,比如知识问答、资料整理等;
嵌套子智能体(Subagents):主 Agent 负责总控规划与任务分配,子 Agent 负责专项子任务,最大支持2层嵌套,避免单Agent负载过载,提升任务执行效率; 循环调用检测:通过Call Graph追踪工具调用链路,实时识别死循环(如“工具A、B互相调用”)并自动终止,避免资源浪费; 混合模型路由:轻量任务调用低成本小模型,深度推理调用高端模型,来达到执行成本与推理效果的平衡; 上下文防护(Context Window Guard):按“系统指令>任务要求>执行结果>历史记录”的优先级,对上下文进行可控压缩,确保核心安全规则、任务约束等永不丢失,避免 LLM 执行幻觉、失忆等。
五、多模态协同与规模化治理
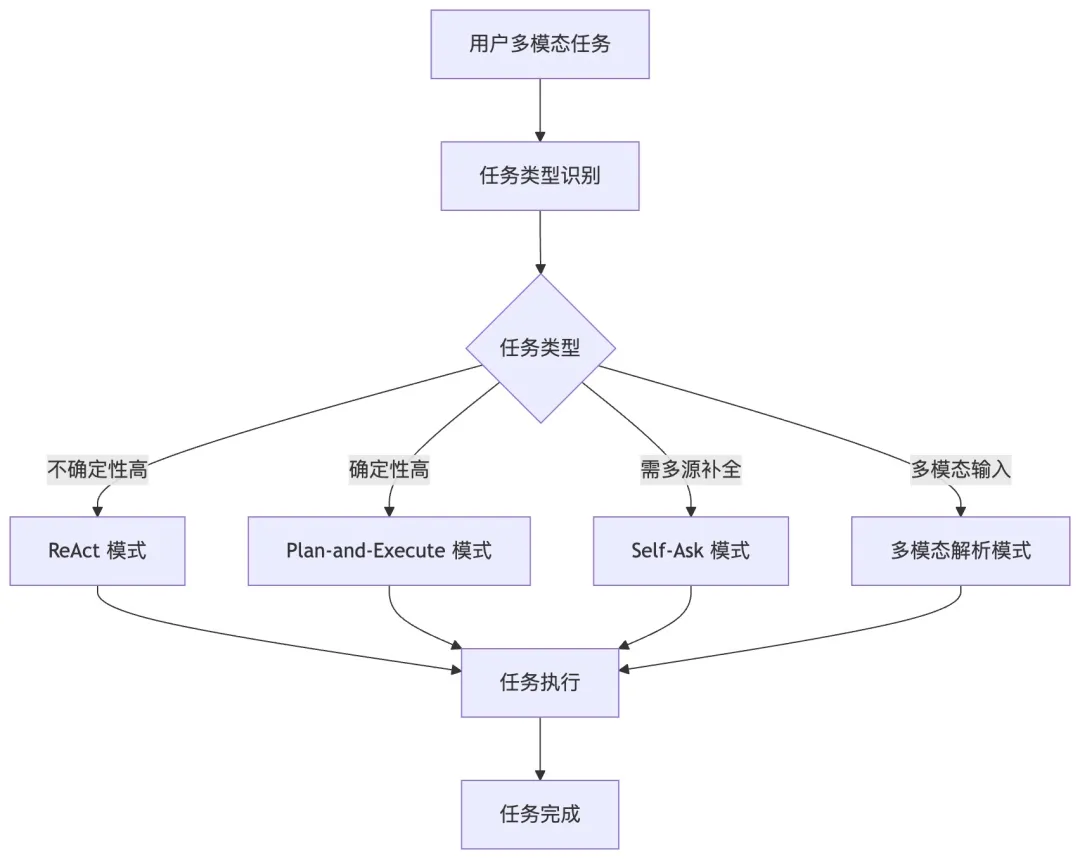
多模态推理融合:新增对图像、本地文件等多模态输入支持,推理链可跨模态进行信息解析,比如结合图像识别与文本推理,自动提取图片中的表格数据进行分析; 子智能体架构升级:突破了2层嵌套限制,支持多级子智能体协同,主Agent负责总控,子Agent可按技能分类,实现更精细的任务拆分与分工; 强化安全治理:新增细粒度权限控制,支持按工具、按子任务分配权限,结合 Docker 沙箱升级,杜绝越权操作; 优化Token成本:优化混合模型路由与上下文压缩策略,新增Token用量预警机制,解决“养龙虾”过程中 Token 消耗过高的痛点,平衡推理效果与成本;
六、结语:工程化才是Agent落地的王道
OpenClaw的推理链演进路径,其实回答了一个根本问题:当大模型能力已经触手可及时,我们该怎么让它真正的落地干活?答案就是:工程化治理,给大模型一个靠谱的执行系统。模型决定上限,推理链决定下限。
未来,随着多智能体协同、端云协同的深化,推理链将进一步向轻量化、分布式、自适应演进, 到那个时候,AI将会真正地成为人类的数字员工。
你是否也遇到了侃侃而谈的Agent,一干活就翻车?像极了某些人类...欢迎留言探讨!
---- / END / ----
【 推荐阅读 】
「AI知觉」 | 重构个人竞争力
以智求知,以行致觉
