 夜雨聆风
夜雨聆风今年 1 月 27 日,我第一次在鲁班猫 RK3588 上折腾 ClawBot。
那时候图省事,直接走了 Docker 路线,后端挂本地 Ollama,大体上也能跑。但“能跑”和“好用”,中间其实隔着一条很长的线。
尤其是在嵌入式设备上,这种差别会被放大得非常明显。

Docker 的确方便,拉镜像、起服务、看起来一套到位。可一旦把它放到板子上,再叠上本地大模型推理,系统负载、响应速度、调试复杂度,全都开始往上走。你会发现,很多时间不是花在“让智能体更聪明”上,而是花在“为什么它又卡了”上。
所以这次我干脆换了一种思路:
放弃 Docker,直接原生安装 OpenClaw;放弃本地模型硬扛,把算力交给 UniVibe API。
结果很直接。
链路跑通之后,整个系统一下轻了很多。板子继续负责网关、设备管理、会话控制这些本地任务,模型推理交给云端,响应速度和稳定性都比之前顺眼太多。对 RK3588 这类设备来说,这种架构明显更合理。
如果你手里也有鲁班猫、香橙派、树莓派这类板子,或者你也在折腾本地智能体,这条路值得你认真看一眼。
一句话讲清这次改造
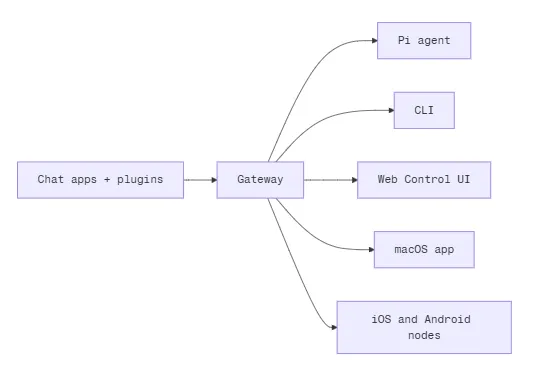
这次我跑通的,不再是“板子上塞满一切”的全家桶方案,而是一套更轻的组合:
鲁班猫负责 OpenClaw Gateway,本地做调度、管理和配对。 UniVibe API 负责模型能力,按需调用,不让板子死扛推理。 控制界面放到局域网里的电脑浏览器上,远程接入。
说白了,就是一句话:
本地设备负责控制,云端服务负责思考。
这个分工一旦理顺,很多之前绕不过去的问题,突然就不再是问题了。
为什么我决定把 Docker 扔掉
这不是说 Docker 不好。
如果你是在服务器、工作站,甚至是性能不错的小主机上部署,Docker 依然是非常省心的方案。但在嵌入式场景里,它的优势有时候会被现实抵消掉。
我这次最大的感受有三个。
第一,资源更紧。
板子的每一点内存、每一点 IO、每一点 CPU 调度,都是实打实要算账的。容器化带来的额外开销,在桌面设备上你可能感觉不到,在板子上往往就会变成“怎么今天又慢了”。
第二,问题更绕。
原生部署出问题,通常就是服务本身、配置本身、网络本身。
容器化之后,你还得多想一层:是不是镜像问题、是不是端口映射问题、是不是卷挂载问题、是不是容器内部环境和宿主机不一致。排障路径一下就长了。
第三,本地跑模型并不划算。
RK3588 不是不能干活,但如果你一边想让它当网关、一边让它扛模型推理、一边还要兼顾设备控制和远程访问,最后多半会进入一种“什么都能做一点,但没有一样特别舒服”的状态。
所以我后来意识到,真正适合这类设备的,不是“把所有东西都塞进去”,而是“把最适合本地做的事留在本地”。
原生安装其实不复杂,复杂的是后面的细节
OpenClaw 原生安装本身并不算折腾,一行命令就能下去:
curl -fsSL https://openclaw.ai/install.sh | bash
真正容易把人卡住的,不是安装,而是装完之后的配置变化。
尤其是如果你看过早期教程,再拿旧经验直接套新版本,大概率会踩坑。表面上看只是“怎么网页打不开”“怎么设备配不上”“怎么浏览器报跨域”,但本质上是 OpenClaw 这套配置逻辑已经变了。
我这里把最关键的三个坑,直接一次说透。
三个最容易踩的坑,我替你们踩过了
1. 别再盯着 0.0.0.0 了,新版看的是 Bind Mode
以前很多人习惯直接搜怎么把服务绑到 0.0.0.0,但新版 OpenClaw 已经不是这个思路了。
如果你想让局域网里的电脑访问控制界面,正确方式是明确告诉它:我要开局域网访问。
openclaw config set gateway.bind lan
openclaw gateway restart
这一步没配对,后面很多问题都会跟着来。你以为是网络不通,实际上是绑定模式根本没开对。
2. 浏览器报 origin not allowed,大概率不是网络问题,是跨域没配好
这个报错我第一次看到的时候,也下意识以为是服务没起来,或者端口没开。
后来才发现,问题很简单,也很隐蔽:allowedOrigins 这里要传的是数组,不是普通字符串。
错误写法像这样:
...allowedOrigins '*'
正确写法应该是:
openclaw config set gateway.controlUi.allowedOrigins '["*"]'
openclaw gateway restart
注意这个中括号。少了它,你看起来像是配了,实际上等于没配。
3. 设备配对时,批的不是 DeviceId,是 RequestId
这是最容易把人带偏的一步。
执行:
openclaw devices list
你会看到一堆 ID。如果这时候你直觉上拿 DeviceId 去 approve,基本就会卡住。真正该批准的,是请求那一列,也就是 RequestId。
openclaw devices approve <你的RequestId>
很多时候系统不是坏了,只是你批错了对象。
这类问题特别典型,看起来像功能故障,实际上只是字段没认清。第一次折腾的时候,非常容易浪费半小时以上。
接入 UniVibe API 之后,整个体验才真正顺起来
我这次最满意的,其实不是“终于装好了”,而是接入 UniVibe 之后,那种明显的轻松感。
OpenClaw 的模型配置本身就比较清晰,走的是 provider/model 这种结构。换成 API 路线后,切模型会比本地部署简单得多。
比如:
openclaw models set univibe-gpt/gpt-5.4
这样做最现实的好处,不是“参数更高级”,而是你终于不用再把大量时间花在量化、显存、推理速度、兼容性这些问题上。
对板子来说,这是一种很务实的减负。
它不用再假装自己是一台模型服务器,而是老老实实做自己最擅长的事情:稳定在线、持续控制、管理设备、承接请求。
至于模型能力,交给更合适的地方去完成。
这才像是一套能长期跑的方案。
这次折腾给我最大的一个判断
如果你做的是嵌入式 AI、边缘智能体,或者任何“本地设备 + 云端模型”的系统,思路真的该变一变了。
过去很多人一上来就追求“全本地”“全离线”“全都塞到设备里”。这种路线不是不酷,但现实是,大多数项目真正需要的不是极限本地化,而是:
一套稳定、清晰、可维护、能长期工作的链路。
从这个角度看,鲁班猫这类板子最有价值的地方,不是充当一个吃力不讨好的模型主机,而是成为一个真正可靠的本地控制中枢。
它离设备近,离传感器近,离执行器近,网络稳定时可以随时借云端算力,网络一般时也能把本地调度维持住。
这才是它最舒服的位置。
折腾的意义,不只是把东西装上
每次把一套链路真正跑通之后,我都会有一个很强烈的感觉:
你对系统的掌控感,和“用没用现成方案”没有直接关系;它取决于你到底知不知道,这套东西为什么这样工作。
当你在终端里敲下:
openclaw logs --follow
然后看着日志一行一行往下走,知道请求从哪里进来、配置在哪一层生效、设备为什么能连上、模型为什么能响应,那种感觉和“拉个镜像跑起来”完全不是一回事。
前者叫搭系统,后者更像是借系统。
如果你手里那块板子现在还在角落里吃灰,不妨给它一次重新上岗的机会。别再让它硬扛所有事情,换一种更轻、更合理的架构,也许它能比你想象中更能打。
技术栈参考
硬件:鲁班猫 RK3588 系列 部署方式:OpenClaw Gateway 原生安装 模型能力:UniVibe API Provider 使用场景:局域网远程控制、设备配对、会话管理
如果后面你们想看,我可以继续把这一套整理成更细的实操版,包括安装步骤、配置文件位置、常见报错对照和局域网访问方案。
可以参考这个公众号来白嫖获取API,内部也有Openclaw安装教程
梓笙黎的小屋,公众号:梓笙黎的小屋国内也能用 Claude Code
