 夜雨聆风
夜雨聆风
说实话,最近我用 OpenClaw,用着用着是有点后背发凉的。
不是因为它不行,恰恰是因为它太“像一个能干活的人”了。
你给它一个目标,它不是回你一段答案,而是开始拆任务、调工具、写文件、执行流程,甚至在你没继续说话的时候,它还在往下推进,这种感觉一开始是爽,但用久了你会有点不安。
因为你很快会遇到一个问题:
👉 它不是不会做,而是——有时候会“做偏”。
前一轮它还严格按照你的要求来,下一轮突然就变了风格,甚至直接跳过你刚刚说的限制条件,开始自己行动,如脱缰的野马,失去了控制。
我一开始其实是有点不服的,我觉得这不就是模型不够强、上下文不够大吗?换个更大的模型是不是就好了。
但后来我才慢慢反应过来,其实问题根本不在模型。
👉 真正的问题,是我没有搞懂它的“上下文工程”。

01
———
不识泰山:我一开始真的把它想简单了
一开始我以为所谓“记忆系统”,无非就是:
记录聊天 再喂回去
说白了就是个加强版聊天记录。
但你真自己去翻一圈 OpenClaw 的目录,再对照官方文档看一遍流程,你会发现这东西完全不是这么回事。
它其实在做一件更像“工程”的事情:
👉 不是让AI记住,而是决定“每一轮到底让AI看到什么”。
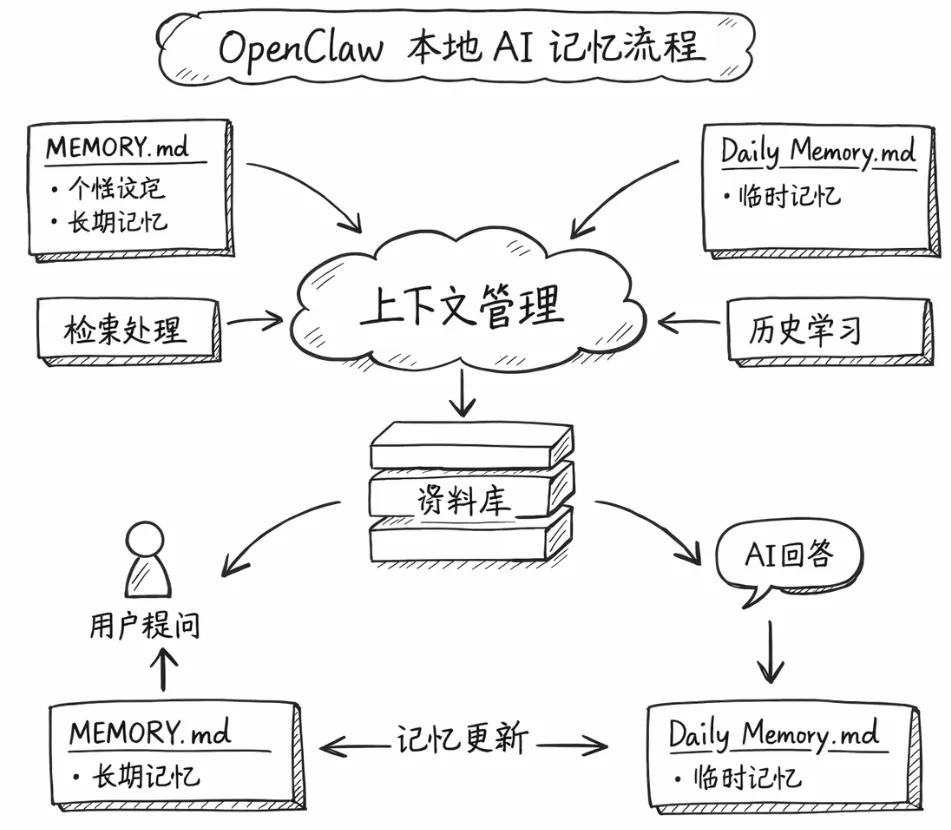
官方文档⬆️其实说得很直白,上下文并不只是提示词,而是所有被塞进模型的输入总和,包括系统提示词、用户输入、历史对话、工具结果、检索内容以及长期记忆,它们一起组成了模型真正的“认知范围”。
你可以把它理解成一个输入系统,而不是一个记忆模块。
02
———
痛的领悟:那一次让我彻底改观的“翻车现场”
我有一次给它下了个非常明确的指令:
👉 “这次先不要执行,只给我方案。”
前面几步都挺正常的,它会分析、拆解、给出结构。
但过了一段时间,它直接开始执行了。
而且不是那种“误操作”,而是很自然地进入执行流程,仿佛从来没听过我那句话一样。
我当时第一反应是:
这东西不靠谱。
但后来我去看了它的上下文状态和记忆文件,才发现一个很关键的细节:
👉 那句“不要执行”,只存在于对话里,没有进入它的长期上下文结构。
再加上那一轮对话比较长,触发了上下文压缩,这条约束在压缩过程中被“合理地忽略”了。
不是它叛变了,而是——
👉 它根本没把这条规则当成“必须长期保留的信息”。
03
———
深刻理解:上下文工程到底是干嘛的
很多人会把“提示词工程”和“上下文工程”混在一起,但你一旦真的跑过 OpenClaw,就会发现它们完全不是一个层级的东西。
提示词工程,是:你怎么问。
而上下文工程,是——
👉 你到底把什么信息喂给模型。
而且不是一次,而是持续、多轮、动态地喂。
OpenClaw 的做法其实很工程化,它把整个过程做成了一条流水线,这一点我觉得是它最值钱的地方。
它的“脑子”,其实是三层加工出来的
我后来自己总结了一下(结合官方流程和源码逻辑),它大概分成三层:
第一层:资源选择(决定什么能进来)
这一层会收集所有可能进入上下文的东西:
工作区文件(AGENTS.md、TOOLS.md、MEMORY.md 等) 历史对话 工具结果 用户输入
但关键不在收集,而在——筛选。
👉 哪些必须留,哪些可以丢,这一步就已经开始影响结果了。
第二层:组装(把信息拼成模型能理解的结构)
这一步其实挺容易被忽略,但很关键。
因为模型不是人,你把一堆杂乱信息塞进去,它是读不懂的。
所以系统会做一堆事情:
清理无效消息 修复工具调用顺序 控制 token 使用 按顺序重新排列
这一层,说白了就是:
👉 把“乱七八糟的信息”,整理成“模型能看懂的输入”。
第三层:保护(防止系统崩掉)
这一层是很多人没意识到的。
因为模型有上下文窗口限制(比如 32K、200K tokens),一旦超了,要么报错,要么乱。
所以 OpenClaw 会做几件事:
监控 token 使用 到阈值自动触发压缩 防止溢出
这一步,其实决定了一个很关键的问题:
👉 长任务能不能稳定跑下去。
真正让我服气的,是它的“压缩机制”
这个东西,我一开始是完全低估的。
你以为压缩就是“删一点历史”。
但实际上,它有三种策略:
摘要压缩(用模型总结历史) 截断(直接丢掉最早的) 混合(总结 + 删除)
而且它不是等你爆了才处理,而是会在接近阈值(比如 90%)的时候主动触发。
这就带来一个很现实的问题:
👉 你没明确标记的重要信息,很容易在压缩中被吞掉。
这就像你写会议纪要,如果没有强调重点,最后总结的人未必会写进去。
04
———
像人一样:它的记忆不是“全记”,而是“按需取”
很多人会误以为:
👉 有 memory,它就会一直记住
其实不是。
OpenClaw 的记忆是两层:
Markdown 文件(真实存储) 向量索引(用于搜索)
它的工作方式是:
👉 先用 memory_search 找相关内容
👉 再用 memory_get 精确读取
而不是每次都把所有记忆塞进去。
这个设计我后来越用越觉得像人。
因为我们自己也是这样:
👉 不是一直记,而是需要的时候去想。
05
———
养成好习惯:更深入对配置的理解
这块我说点实在的,不讲概念。
我现在用 OpenClaw,有几个习惯是被“逼出来”的:
✔️ 一定写 MEMORY.md
以前我只是“说”,就像是随风而过,没留下什么。
现在我会写:
执行规则 禁止行为 输出要求
因为你不写,它就不一定保留。
✔️ Bootstrap 文件当“系统设定”
这些文件我现在都会认真写一下,设定好“人设”是关键:
AGENTS.md(行为规则) USER.md(个人偏好) SOUL.md(语气风格)
你可以理解为:
👉 给它一个“初始人格 + 行为边界”。
✔️ 控制上下文预算
我会刻意调整token参数,使其在可控范围内:
contextTokensbootstrapMaxChars
因为你一旦不控,token 爆掉之后,它就开始“丢记忆”。
✔️ 学会看上下文
我基本每天会用的命令:
/context list/context detail
这两个命令很重要。
因为很多时候不是它错了,而是你根本不知道它“现在脑子里有什么”。
07
———
踩坑实录:简单就是原罪(附完整示例)
说实话,我一开始也写过 MEMORY.md。
但写得很随意。
比如这样:
# MEMORY用户喜欢中文尽量简洁不要乱执行
当时我还觉得挺合理的。
结果用着用着发现:
👉 完全没用。
它还是会跑偏,该执行还是执行,该啰嗦还是啰嗦。
我后来才意识到一个问题:
👉 不是它不记,而是你写得根本不像“规则”。
后来我改了一版,效果直接不一样了。
我现在的 MEMORY.md,会刻意写成这种结构👇
# MEMORY## 用户偏好- 用户偏好中文回答- 更喜欢“像人聊天”的表达,而不是说明书风格- 文章风格:公众号长文,带情绪、有转折、有观点## 行为约束- 默认不要直接执行任务(除非用户明确要求执行)- 在执行前,必须先给出方案或思路- 对高风险操作(删除、覆盖、批量修改)必须二次确认## 输出规范- 避免使用“首先、其次、最后”等明显AI表达- 内容需要有真实感受、过程描述、认知转折- 不要写成条目总结,要像在讲经历## 当前工作模式- 当前主要用于:AI工具分析、公众号写作、知识库搭建- 输出优先级:真实体验 > 功能介绍 > 原理说明
你可以自己试一下。
👉 同样一个问题,用这个 MEMORY.md 和不用,出来的东西完全不一样。
为什么这样写才有效(这个很多人没意识到)
后来我才慢慢反应过来,其实问题不在“写不写”。
而在:
👉 你写的是“提示”,还是“规则”。
大模型其实更吃结构化信息。
你如果写:
👉 “尽量简洁一点”
它会当建议。
但你写:
👉 “默认不要执行,必须先给方案”
它更容易当成“约束条件”。
这就像什么?
就像你跟员工说:
“你尽量别犯错”(没用) “上线前必须走审批流程”(有效)
再进阶一点:我开始把 MEMORY.md 当“操作系统配置”来写
这一步是我后来才想明白的。
👉 MEMORY.md 本质上不是笔记,是“行为系统”。
所以我后来会加一类内容,很多人没写,但特别关键:
✔️ 加“决策记录”(这个很值钱)
## 历史决策- 已确认:所有文章必须采用“老朋友聊天”风格- 已确认:优先写真实体验,而不是功能介绍- 已废弃:纯工具介绍型文章(阅读效果差)
👉 这个会让它“越来越像你”
✔️ 加“踩坑记录”(这个非常好用)
## 常见问题- 上下文过长会导致行为约束丢失 → 重要规则必须写在 MEMORY.md- 自动执行容易跑偏 → 必须加“执行前确认”规则
👉 这其实是在给AI“复盘能力”
✔️ 加“任务套路”(这个很多人没用好)
## 写作流程1. 先从个人感受切入2. 再讲为什么关注这个东西3. 写具体使用过程(必须有细节)4. 给出认知反转5. 最后总结判断
👉 这相当于“内置 SOP”
再说一个很多人忽略的点:daily memory 该怎么用
除了 MEMORY.md,还有一个很多人没用好的:
👉 memory/YYYY-MM-DD.md
这个其实更像:
👉 临时记忆 + 工作日志
我现在一般会这样用:
# 2026-03-24## 今天做了什么- 测试 OpenClaw 上下文工程- 优化 MEMORY.md 结构## 关键发现- MEMORY.md 比对话更重要- 上下文压缩会丢约束## 未完成事项- 测试 memory_search 精度
这个东西的价值在于:
👉 它能被检索(memory_search)
也就是说:
👉 它不是记给你看的,是记给AI用的
如果你是第一次用,我建议你直接用这个完整版👇
# MEMORY## 用户信息- 偏好中文- 喜欢口语化表达- 写作偏公众号风格## 行为规则- 默认不自动执行- 必须先给方案- 高风险操作需确认## 输出风格- 避免AI味表达- 多用转折和情绪- 要有真实使用过程## 当前任务方向- AI工具分析- 知识库搭建- 自动化流程## 历史决策- 强调“真实体验优先”- 弱化功能罗列## 常见问题- 上下文压缩会丢信息- 重要规则必须写入 MEMORY.md
06
———
再回头看,它真正解决的是什么问题
我现在反而不太关心 OpenClaw“会不会执行”。
我更在意一件事:
👉 它能不能在长流程里不跑偏。
因为一旦 AI 从“回答问题”变成“持续执行任务”,问题就变了。
以前是:
👉 它聪不聪明
现在是:
👉 它稳不稳定
而上下文工程,本质上就是在解决三件事:
防止胡说八道 控制信息长度 让模型读得懂
这些在你附件那篇文章里其实讲得很清楚,只不过很多人第一次看会觉得有点抽象,但你一旦用起来,就会发现这些问题一个都躲不掉。
最后一句话
我现在再看 OpenClaw,有一个特别强烈的感受:
👉 它最厉害的,不是它能干活
而是:
👉 它开始让“干活这件事”变得可控了
但前提是——
你得愿意花时间,给它搭一套“不会走偏的脑子”。
否则的话:
它不是帮你,而是替你做决定。


