 夜雨聆风
夜雨聆风

T-Tech论文解读
这篇论文的观点是,并不是如何让智能体在既定指标下跑得更快,而是如何避免在一开始就跑偏。
正是基于这一洞察,论文将“下一状态信号”拆解为评价与指令两层含义,并分别设计了Binary RL和Hindsight-Guided On-Policy Distillation两种方法加以利用。前者将反馈转化为过程奖励,后者则从中提取方向性提示,引导智能体修正行为。
论文所展示的,并非某个具体任务的性能突破,而是一种更贴近真实交互过程的工作方式:智能体的进化不应当是沿着单一目标不断加速,而是在每一次反馈中重新理解任务、调整方向,逐步逼近用户的真实意图。
01 引言
当前的AI agent似乎都在面临同一个问题:当它每次回答完用户问题后,却总是将收到的“反馈”随手丢弃。当用户重新提问了,说明对答案不满意;当测试通过了,说明做对了;当命令行报错了,说明方法有问题......以上种种信号——用户回复、工具执行结果、GUI状态变化——每天都在产生,但也都在流失。
这正是OpenClaw-RL这篇论文提到的现有AI agent的浪费现象。作者指出,现有的agent训练系统把这些“下一状态信号”(next-state signal)仅仅当作下一轮对话的上下文背景,而忽略了它们本身携带的评估价值。
更准确地说,这些信号里藏着两种信息:
一是评价性质的——这一步做得怎么样;
二是指令性质的——本应该怎么做才对。
而正是基于该洞察,来自普林斯顿大学的AI lab团队提出了一套全新的训练框架——
OpenClawRL(OpenClaw-RL:Train Any Agent Simply by Talking)
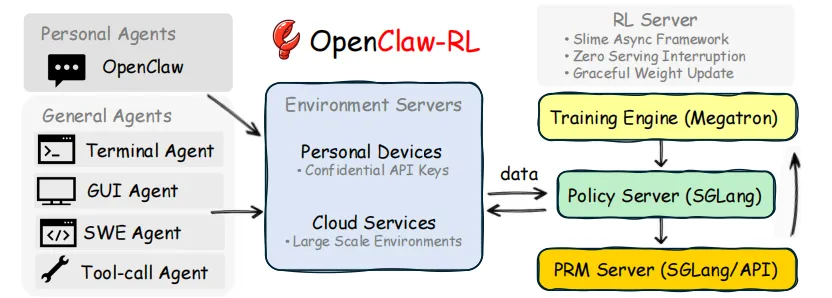
02 两种信号的挖掘方式
论文将“下一状态信号”分成两类,分别对应两种不同的处理方法。
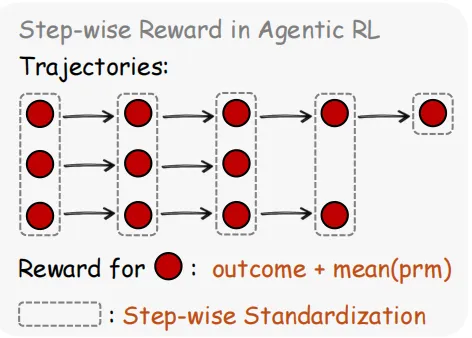
·第一类是评价信号。
用户的再次提问本身就暗示了不满,一次测试的通过就是成功,一个错误堆栈就是失败。这些信号不需要额外标注,天然就是一个个过程奖励(process reward)。
论文使用一个PRM(过程奖励模型)来判断每一步的好坏,取多次投票的多数结果作为最终标签。这种做法在数学推理任务中已经被验证过,但作者将它扩展到了更通用的场景——终端操作、GUI交互、SWE任务、工具调用——这些环境中同样充满了可以被解读为奖励或惩罚的信号。

·第二类是指令信号。
这一层更微妙一些。用户说“你应该先检查一下文件”,这不仅仅说“你错了”,还告诉了agent具体应该怎么做。这类信息在传统的强化学习范式里是完全丢失的——scalar reward只能告诉你好坏,无法告诉你方向。
论文提出的Hindsight-Guided On-Policy Distillation(OPD)正是为了解决这个问题。它的做法是:从下一状态中提取出这种指令性的“提示”(hint),把这个提示加到原始prompt里,让模型重新生成一次回答,然后比较两次生成每个token的概率差异。如果模型在“知道提示后”更倾向于某些token,那这些token就是应该被加强的;反之则是应该被抑制的。这相当于给每个token提供了一个方向性的梯度,而不仅仅是一个整体的+1或-1。
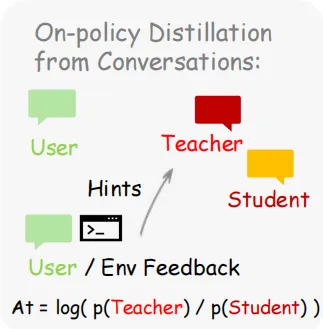
两种方法并不是互相替代的关系。
·Binary RL覆盖面广,所有被打分的回合都能用;
·OPD信号更精细,但只有那些包含明确指令的回合才能提取出有效的hint。
论文将两者结合,用加权的方式叠加优势,在实验里取得了显著优于单独使用任一方法的效果。
03 异步架构:
让训练与推理并行
技术层面,这篇论文的另一个贡献是提出了一个完全解耦的异步架构。
传统RLHF系统的训练流程往往是串行的:收集数据、标注、训练,再收集、再训练。
OpenClaw-RL则把整个流程拆成了四个独立运行的循环:Policy Serving(模型推理)、
Environment Server(环境交互)、PRM Judge(奖励评判)、Policy Training(策略更新)。
这四个模块各自跑自己的,互不阻塞。模型在服务下一个请求的同时,PRM正在评判上一次回复,而训练器正在更新参数。没有等待,没有中断,所有信号都被实时捕获并转化为训练数据。

这个设计对于personal agent尤为重要。个人AI助手运行在用户的私人设备上,每天的交互量稀疏且分散。如果要求用户停下等待训练完成才能继续使用,那整个系统就不可用了。OpenClaw-RL的异步架构保证了——你用着agent的同时,agent也在悄悄学习。
04 实验结果
论文的实验分为两个track。
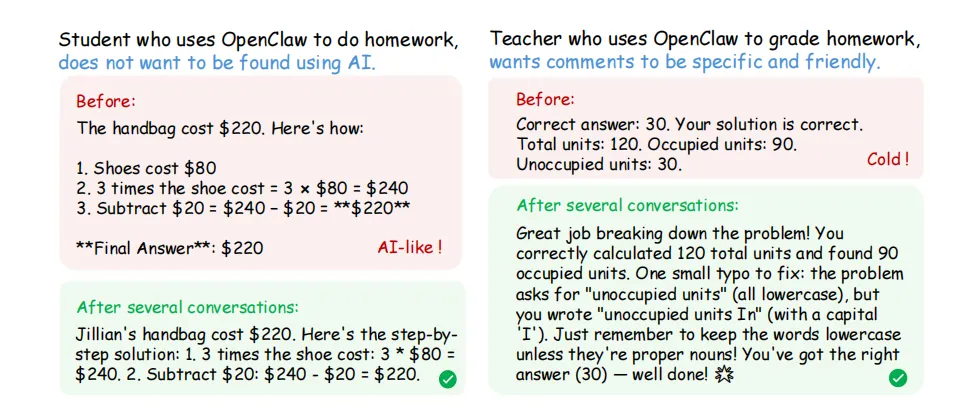
(1)Personal Agent track用模拟器验证了优化效果。
·场景一是“学生用OpenClaw做作业”——不想被老师发现自己用了AI,所以希望AI的回复更像自己写的;
·场景二是“老师用OpenClaw批改作业”——希望评语既具体又友好。
基础模型是Qwen3-4B,经过36次问题解决交互后,agent学会了避免“bold”这类明显的AI用词,回复风格变得更随意自然。老师的场景里,经过24次训练后,评语从简单的“Correct. Well done!”变成了详细且热情的长反馈,还配上了emoji。
(2)General Agent track则展示了同一套基础设施如何支持终端、GUI、SWE和工具调用四种不同类型的agent训练。
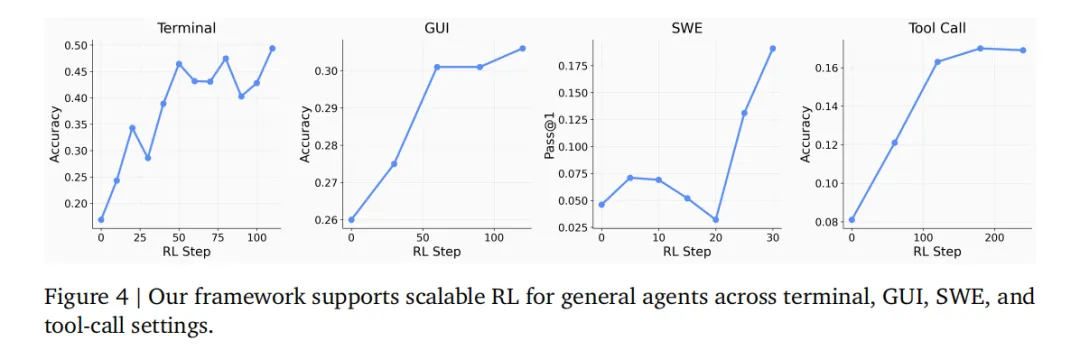
如上图所示,可以发现随着RL步数增加,准确性普遍提升。
当128个并行终端环境、64个GUI/SWE环境、32个工具调用环境同时运行,过程奖励的加入在tool-call任务上把准确率从0.17提升到0.30,GUI任务从0.31提升到0.33。

这些数字本身或许不够惊人,但关键在于——整个训练过程完全依赖真实交互中产生的信号,没有人工标注,没有预先收集的数据集。
05 结语
OpenClaw-RL的核心贡献是发现了“下一状态信号”这个被忽视的训练资源,并通过Binary RL和OPD两种方法分别提取其中的评价信息和指令信息,再用一个完全异步的基础设施让训练与推理共存。
实验验证了这套思路在personal agent和general agent两种场景下都能work。虽然还有工程和理论上的问题待解决,但“边用边学”这个方向本身,已经足够让人看到agent训练的新可能。


