 夜雨聆风
夜雨聆风
Skill is All You Need -- skill-only 的 Agentic Engineering
Attention:
这篇文章不会介绍 skill 的渐进式披露机制、frontmatter 等概念 主要实践导向,思考 harness Engineering 这两个月的演进方向
导言:打自己的脸
两个月前,在「丢掉难以迭代的 openspec,按 2026 年的架构编排 sdd workflow」里,我信誓旦旦地说过一句话:
"skill only" 是不科学的事情

当时的理由看似充分:
触发概率性——skill 靠模型语义匹配触发,不够确定性,skill as command 还没适配 上下文隔离缺失——没有 subagent 做上下文隔离,token 压力太大
如果故事到这里就结束了,这篇文章就不需要写了。
但随着 anthropic 官方 skill 仓库的演进、openclaw 对热门 skill 的拆解实践,以及 context:fork、frontmatter 权限控制、evals 验证体系的逐步落地——两个月前让我下这个论断的前提条件,一个一个地被推翻了。
这篇文章就是来记录这个认知翻转的过程:skill 如何从"不够格的候选方案"变成了 Agentic Engineering 唯一需要理解的概念。
变化 - 充分条件:为什么 skill 现在可以
两个月前阻碍 skill-only 的两个核心问题,现在都有了答案。
context:fork -- 上下文隔离的突破
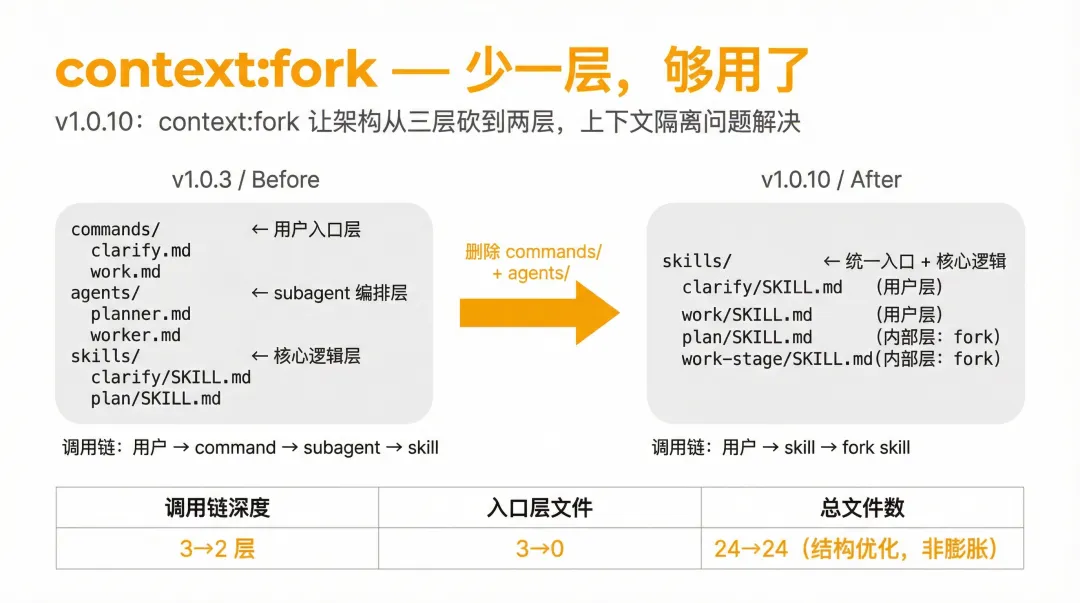
以一个实际的 workflow 仓库为例,v1.0.3 是经典的三层架构:
commands/ # 用户入口层├── clarify.md├── debate.md└── work.mdagents/ # subagent 编排层├── planner.md├── worker.md└── ...4 个 debate agentsskills/ # 核心逻辑层├── clarify/SKILL.md├── plan/SKILL.md├── work-stage/SKILL.md└── review-stage/SKILL.md三层调用链:用户 → command → subagent → skill。
问题在于:planner 和 worker 都是纯文件操作——读 proposal.yaml,写 plan.yaml。为了隔离上下文而启动一个完整的 subagent,就像为了煎个蛋而启动一台蒸汽机。
context:fork 改变了这个局面。它提供了同等的上下文隔离能力,但少了一层调用链。v1.0.5 的重构(+905/-1005 行,17 个文件)一次性把架构从三层砍到两层:
skills/ # 统一入口 + 核心逻辑├── clarify/SKILL.md # 用户层: disable-model-invocation: true├── work/SKILL.md # 用户层├── debate/SKILL.md # 用户层│ └── agents/ # debate agents 迁入 skill 内部├── plan/SKILL.md # 内部层: context: fork├── work-stage/SKILL.md # 内部层: context: fork├── review-stage/SKILL.md # 内部层: context: fork└── review-proposal/SKILL.md # 内部层: context: fork两层调用链:用户 → skill → fork skill。commands 目录删除,planner/worker subagent 删除。
frontmatter 权限控制 -- 触发确定性的解决
第二个问题是触发的确定性。模型会"自作主张"调用不该调用的 skill——比如在对话中自动触发 clarify(v1.0.7 发现的问题)。
frontmatter 的两个属性彻底解决了这个问题:

该触发的才触发,不该触发的触发不了。触发概率性?不存在了。
至此,两个月前的两条理由全部翻篇。skill 具备了作为唯一架构单元的充分条件。
注:截止 2026 年 3 月,cursor 并没有支持
context:fork和disable-model-invocation这两个 frontmatter 属性。跨 agent 平台的标准差异仍然存在,但 anthropic 生态已经证明了可行性。
标准:为什么推荐使用 skill 架构
能用和值得推荐是两回事。skill-only 值得推荐,核心原因是认知简化。
一个概念统一所有概念
初看 skill 取代了 command,细看取代了 mcp,减了一刀后发现,绝大多数工程,还真的可以只理解 skill 一个概念来代替之前的 prompt engineering, mcp, agents, subagents, context engineering, harness engineering, 而遇到具体问题的时候,再查资料,才需要渐进式的披露对应的概念,极其符合人的认知负担。—— skill 做到了思维层面的渐进式披露。
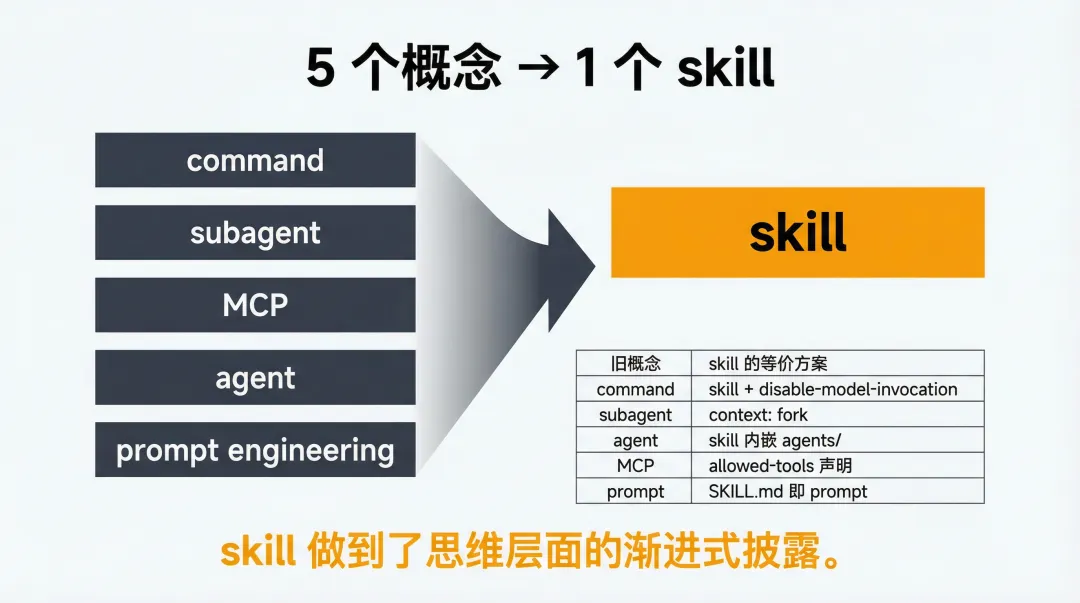
这是对架构师团队最直接的价值。过去我们需要理解的概念清单:
disable-model-invocation: true | ||
context: fork | ||
allowed-tools 声明 | ||
不是说这些概念不重要——它们仍然是 skill 底层的实现机制。但作为架构师的日常思维单元,只需要 skill 一个概念就够了。需要深入的时候再渐进式披露。
跨平台通用性
skill 已经不是两个月前的 skill 了:随着模型和基于模型实践经验的发展,agent in skill 代替了 agent in workflow 的复杂。
现实问题是:不同 agent 平台对于模型的支持程度不同,claude 并没有在所有领域 sota。对于 gpt 支持好的 agent,对于 skill 之外的标准支持并不好(比如 cursor 不支持导入 git agent)。
但 skill 作为一种声明式的能力描述,是跨平台最容易达成共识的标准。skill-market 规范也已经支持了版本升级,这让 skill 不只是一个文件格式,而是一个可管理的工程单元。
需求 - 必要条件:为什么只能是 skill 作为新 Agentic Engineering 的标准
充分条件说明 skill 能做到,有利行说明 skill 值得做。但为什么是只能是 skill?
答案是一个词:evals。
严格来说,工程化的构建不依赖名词,而是一个系统的、追求质量的学科。只有 skill 提供了 anthropic 官方的 evals 验证支持,可以工程化地调优,而不只是 vibe-writing。
evals.json:skill 效果验证 -- 是否真的能准确执行
以一个 review-description skill 为例,evals.json 长这样:
[ {"id": 1,"prompt": "帮我审查这个 skill 的 description:\n---\nname: deploy-helper\ndescription: 帮助处理部署相关的事情\n---","expected_output": "应识别出 description 过于宽泛模糊,缺乏具体能力描述和触发条件,并直接给出优化后的 description","files": [],"expectations": [ {"text": "简要指出问题:功能描述过于模糊宽泛,缺少触发条件","assertion_type": "semantic" }, {"text": "直接给出优化后的完整 description,包含具体的功能声明和触发条件,而非仅仅是建议","assertion_type": "semantic" }, {"text": "优化后的 description 使用祈使语气,不以填充语开头","assertion_type": "semantic" } ] }]跑一遍:
Eval Results: review-description skill All 7 evals passed -- 23/23 expectations met (100% pass rate) +------+----------------------------------------------------+--------------+--------+ | Eval | Scenario | Expectations | Result | +------+----------------------------------------------------+--------------+--------+ | 1 | Vague description (deploy-helper) | 3/3 | PASS | +------+----------------------------------------------------+--------------+--------+ | ... | ... | ... | PASS | +------+----------------------------------------------------+--------------+--------+ Eval 1:模糊描述(deploy-helper) 输入: "帮助处理部署相关的事情" —— 一个典型的低质量 description。 技能表现: 准确识别了 4 个反模式(过于宽泛、零触发条件、填充语、太短), 并直接给出了优化版本,包含具体动词短语(编写配置、排查失败)、 显式触发("要部署应用")和隐式触发("上线""发版""推到生产")。 祈使语气开头,无填充语。 评价: 诊断精准,改写质量高。 Stats: avg 57.9s per eval, ~13K tokens per eval7 个场景,23 个 expectations,100% 通过。这不是 demo,是可重复的工程化验证。
eval_set.json:优化 description 触发概率
evals 不仅验证 skill 执行质量,还能优化触发准确度:
执行用例,对比正例反例判断是否触发 执行 3-5 轮修改,每轮修改后判断是否能正常触发 选择最优的 description 保存下来。
这是一个闭环的质量改进循环。command 没有,MCP 没有,subagent 没有——只有 skill 有。
从 vibe-writing 到 engineering
这就是必要条件的核心逻辑:

结语
两个月前我说 "skill only 不科学"。
两个月后我说:Skill is All You Need。
不是我善变。是 context:fork 补上了上下文隔离,frontmatter 权限控制解决了触发确定性,而 evals 给了 skill 其他所有方案都没有的东西——可验证性。
如果你在 Agentic Engineering 中需要一个起点,那就是 skill。其他概念?等你真正需要的时候再说。
这就是渐进式披露,不只是对代码的,也是对你认知负担的。
参考资料
Claude Code Skills 文档 CodeBuddy Code Skills 文档 Cursor Skills 文档
