 夜雨聆风
夜雨聆风OpenClaw 上手指南:环境搭建与第一个灵巧手任务
纸上得来终觉浅,绝知此事要躁干。前面聊了那么多具身智能的理论和架构,今天我们正式进入实战模式——手把手带你把 OpenClaw 跑起来,完成你的第一个灵巧手仿真任务。从零到一,踩坑我替你踩了,你只管跟着敲。
一、硬件要求:你的机器能跑吗?
 先别急着 clone 仓库,看看你的硬件配置够不够格。具身智能仿真对算力的要求不低,OpenClaw 底层依赖 MuJoCo / Isaac Sim 等物理引擎,GPU 渲染是刚需。最低配置:
先别急着 clone 仓库,看看你的硬件配置够不够格。具身智能仿真对算力的要求不低,OpenClaw 底层依赖 MuJoCo / Isaac Sim 等物理引擎,GPU 渲染是刚需。最低配置:
几个关键点:
- macOS 用户
:MuJoCo 支持 macOS 做可视化预览,但训练建议还是 Linux。Isaac Sim 目前仅支持 Linux。 - Windows 用户
:WSL2 + Ubuntu 22.04 是可行方案,但 GPU 直通配置容易翻车,建议直接装双系统。 - 云服务器
:AutoDL、阿里云 GPU 实例都可以,选 RTX 3090 或 A100 实例,记得开启 X11 转发或者用 VNC 做可视化。
检查你的 GPU 和 CUDA 版本:
# 检查 NVIDIA 驱动和 GPU 信息nvidia-smi# 检查 CUDA 版本nvcc --version# 如果没装 CUDA,参考 NVIDIA 官方文档安装# https://developer.nvidia.com/cuda-toolkit-archive二、环境安装:一步步来,别跳步
2.1 创建 Conda 环境
强烈建议用 Conda 隔离环境,避免依赖地狱。
# 创建 Python 3.10 环境(OpenClaw 推荐版本)conda create -n openclaw python=3.10 -yconda activate openclaw# 安装 PyTorch(根据你的 CUDA 版本选择)# CUDA 12.1 版本pip install torch==2.2.0 torchvision==0.17.0 --index-url https://download.pytorch.org/whl/cu121# CUDA 11.8 版本# pip install torch==2.2.0 torchvision==0.17.0 --index-url https://download.pytorch.org/whl/cu1182.2 安装 MuJoCo
OpenClaw 默认使用 MuJoCo 作为物理仿真后端,DeepMind 已经将其开源并整合进了 mujoco Python 包。
# 安装 MuJoCo Python 绑定pip install mujoco>=3.1.0# 验证安装python -c "import mujoco; print(f'MuJoCo version: {mujoco.__version__}')"# 安装可视化依赖pip install mujoco-python-viewersudo apt-get install -y libgl1-mesa-glx libglew-dev2.3 克隆并安装 OpenClaw
# 克隆仓库git clone https://github.com/OpenClaw/openclaw.gitcd openclaw# 安装核心包和依赖pip install -e ".[all]"# 如果只需要最小安装# pip install -e ".[core]"# 验证安装python -c "import openclaw; print(f'OpenClaw version: {openclaw.__version__}')"2.4 安装额外依赖
# 强化学习框架pip install stable-baselines3>=2.2.0pip install gymnasium>=0.29.0# 数据处理和可视化pip install h5py pandas matplotlib tensorboard# 可选:Isaac Sim 支持(需要额外配置)# pip install -e ".[isaac]"三、项目结构:先建立全局观
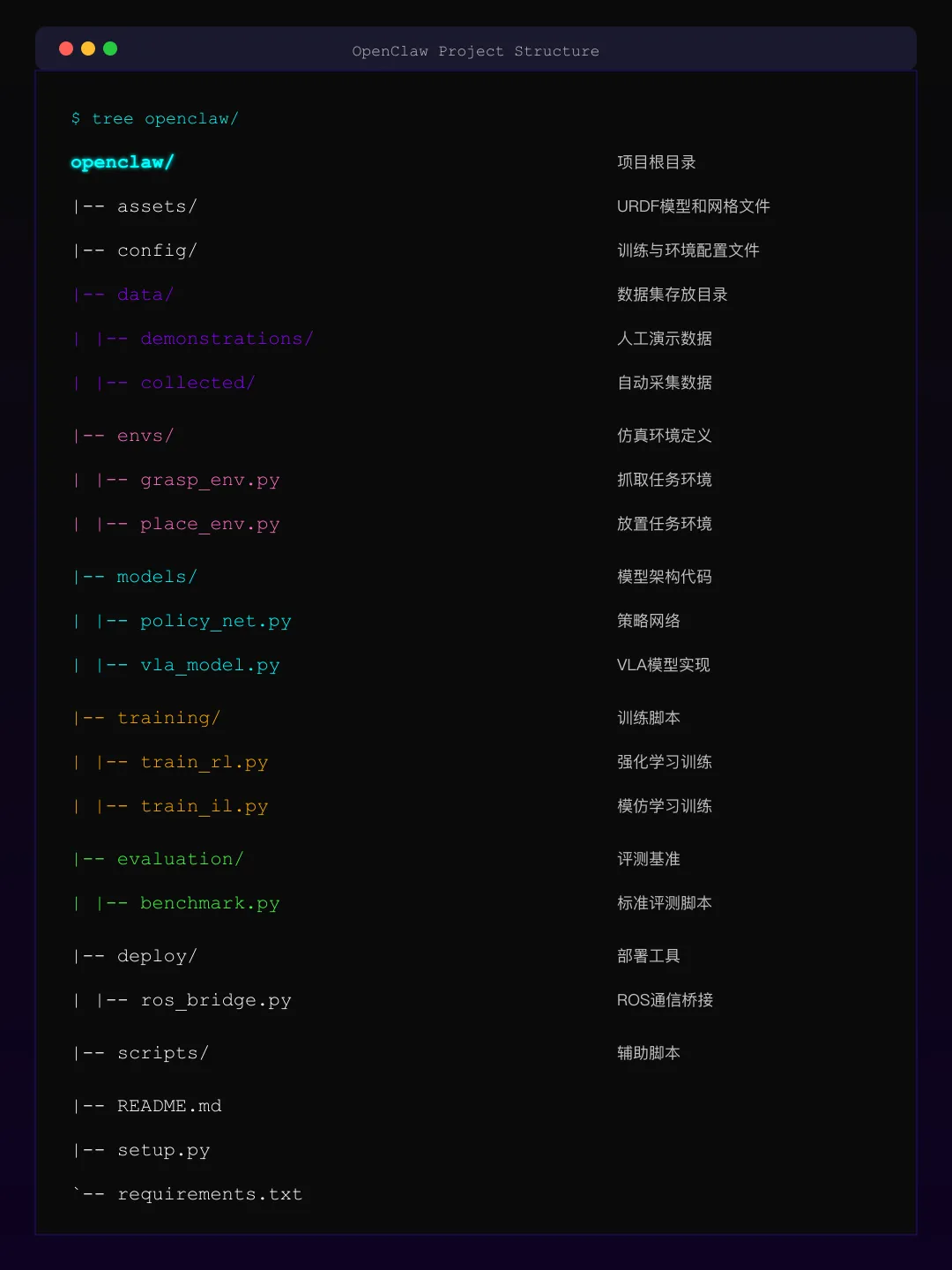
装好了别急着跑,先看看 OpenClaw 的项目结构,知道东西放在哪里,后面调试少走弯路。
openclaw/├── openclaw/│ ├── core/ # 核心模块│ │ ├── engine/ # 物理引擎抽象层(MuJoCo/Isaac Sim)│ │ ├── robot/ # 机器人模型定义│ │ │ ├── hands/ # 灵巧手模型(LEAP Hand、Allegro Hand 等)│ │ │ └── arms/ # 机械臂模型│ │ ├── env/ # Gymnasium 兼容的环境封装│ │ └── controller/ # 控制器(关节控制、笛卡尔控制)│ ├── tasks/ # 预定义任务│ │ ├── grasp/ # 抓取任务│ │ ├── manipulate/ # 操作任务(旋转、翻转等)│ │ └── dexterous/ # 灵巧操作任务│ ├── algo/ # 学习算法│ │ ├── bc/ # Behavior Cloning│ │ ├── rl/ # 强化学习(PPO、SAC)│ │ └── diffusion/ # 扩散策略│ ├── data/ # 数据工具│ │ ├── collector/ # 数据采集│ │ ├── replay_buffer.py # 经验回放│ │ └── dataset.py # 数据集加载│ └── utils/ # 工具函数├── configs/ # 配置文件(YAML)│ ├── env/ # 环境配置│ ├── task/ # 任务配置│ ├── algo/ # 算法配置│ └── robot/ # 机器人配置├── assets/ # 模型资产(URDF/MJCF)├── scripts/ # 运行脚本├── examples/ # 示例代码└── tests/ # 测试用例核心模块说明:
- engine/
:对底层物理引擎做了统一抽象,你可以无缝切换 MuJoCo 和 Isaac Sim,训练代码不用改。 - tasks/
:每个任务目录下包含环境定义、奖励函数、成功判定逻辑。你自定义任务也放这里。 - configs/
:OpenClaw 采用 Hydra 配置管理,所有超参数都在 YAML 里,命令行可覆盖,非常灵活。
四、第一个 Demo:让灵巧手动起来
4.1 运行预置的抓取任务
先跑一个最简单的——用 LEAP Hand 抓取一个方块。
# 运行抓取任务的可视化演示(使用预训练策略)python scripts/run_demo.py \ --task grasp_cube \ --robot leap_hand \ --render \ --num_episodes 5如果一切正常,你会看到一个 MuJoCo 可视化窗口弹出来,一只灵巧手在尝试抓取桌面上的方块。
4.2 用 Python 脚本与环境交互
更推荐用代码的方式理解整个流程:
"""first_demo.py - OpenClaw 第一个灵巧手任务在 MuJoCo 仿真中控制 LEAP Hand 完成方块抓取"""import openclawfrom openclaw.core.env import make_envfrom openclaw.utils.viewer import SimpleViewerimport numpy as npdefmain():# 1. 创建环境 env = make_env( task="grasp_cube", # 任务:抓取方块 robot="leap_hand", # 机器人:LEAP Hand sim_engine="mujoco", # 仿真引擎 render_mode="human", # 渲染模式 config_overrides={"env.episode_length": 200, # 每个回合最大步数"env.object.size": 0.04, # 方块边长 4cm"env.reward.grasp_bonus": 10.0, # 成功抓取奖励 } )print(f"观测空间: {env.observation_space}")print(f"动作空间: {env.action_space}")print(f"动作维度: {env.action_space.shape[0]}")# 2. 运行随机策略for episode inrange(3): obs, info = env.reset() total_reward = 0 done = False step = 0whilenot done:# 随机动作(后面会换成训练好的策略) action = env.action_space.sample() obs, reward, terminated, truncated, info = env.step(action) total_reward += reward done = terminated or truncated step += 1print(f"Episode {episode + 1}: "f"steps={step}, reward={total_reward:.2f}, "f"success={info.get('is_success', False)}") env.close()print("Demo 完成!")if __name__ == "__main__": main()运行:
python first_demo.py随机策略的成功率基本是 0,别担心——这恰恰说明这个任务有学习的空间。后面我们会用强化学习和模仿学习来训练一个像样的策略。
4.3 理解观测和动作空间
"""inspect_spaces.py - 检查环境的观测和动作空间结构"""from openclaw.core.env import make_envenv = make_env(task="grasp_cube", robot="leap_hand", sim_engine="mujoco")# 观测空间详情obs, info = env.reset()print("=== 观测空间 ===")for key, value in obs.items():ifhasattr(value, 'shape'):print(f" {key}: shape={value.shape}, dtype={value.dtype}")else:print(f" {key}: {type(value)}")# 典型输出:# === 观测空间 ===# joint_pos: shape=(16,), dtype=float32 # 关节位置# joint_vel: shape=(16,), dtype=float32 # 关节速度# fingertip_pos: shape=(4, 3), dtype=float32 # 指尖位置# object_pos: shape=(3,), dtype=float32 # 物体位置# object_quat: shape=(4,), dtype=float32 # 物体姿态# goal_pos: shape=(3,), dtype=float32 # 目标位置# 动作空间print(f"\n=== 动作空间 ===")print(f" 维度: {env.action_space.shape}")print(f" 范围: [{env.action_space.low[0]:.2f}, {env.action_space.high[0]:.2f}]")# 动作是 16 维的关节位置增量,范围 [-1, 1]env.close()五、常见报错与解决方案
实战中你大概率会遇到这些坑,提前准备好铲子。
问题 1:MuJoCo 渲染报错
ERROR: GLEW initialization failed: Missing GL version解决:
# 安装 OpenGL 依赖sudo apt-get install -y libgl1-mesa-glx libglew-dev libglfw3 libglfw3-dev# 如果是无头服务器,使用 EGL 渲染export MUJOCO_GL=egl# 或者使用 OSMesa 软渲染export MUJOCO_GL=osmesasudo apt-get install -y libosmesa6-dev问题 2:CUDA out of memory
RuntimeError: CUDA out of memory解决:
# 减小并行环境数量python scripts/train.py env.num_envs=4 # 默认可能是 64 或 128# 或者使用混合精度训练python scripts/train.py algo.mixed_precision=true问题 3:导入报错 ModuleNotFoundError
ModuleNotFoundError: No module named 'openclaw.xxx'解决:
# 确保用 -e 模式安装cd openclawpip install -e ".[all]"# 检查 Python 路径python -c "import openclaw; print(openclaw.__file__)"问题 4:资产文件找不到
FileNotFoundError: MJCF file not found: assets/robots/leap_hand/leap_hand.xml解决:
# 下载资产文件(部分大文件需要单独下载)python scripts/download_assets.py --all# 或者手动指定资产路径export OPENCLAW_ASSETS_DIR=/path/to/openclaw/assets问题 5:版本冲突
# 核实关键包版本的兼容性pip list | grep -E "torch|mujoco|gymnasium|stable-baselines3"# 推荐的兼容版本组合:# torch==2.2.0# mujoco>=3.1.0# gymnasium>=0.29.0# stable-baselines3>=2.2.0六、推荐学习路径
刚跑通第一个 Demo,接下来怎么深入?给你一条实测有效的路径:Week 1-2:基础熟悉
跑通所有 examples/下的示例代码阅读 configs/下的配置文件,理解每个参数的含义尝试修改环境参数(物体大小、摩擦系数、奖励函数)
Week 3-4:训练入门
用 PPO 训练一个简单的抓取策略(下一篇会详细讲) 学会看 TensorBoard 曲线,理解训练动态 尝试 Behavior Cloning,对比 RL 和 IL 的效果差异
Week 5-6:进阶探索
自定义任务:定义新的奖励函数和成功条件 数据采集:录制演示数据,训练模仿学习策略 多物体场景:增加环境复杂度
Week 7-8:深水区
Sim-to-Real:了解域随机化、系统辨识 扩散策略:尝试 Diffusion Policy 等前沿算法 多指协调:高自由度灵巧操作任务
总结
今天我们完成了 OpenClaw 从零搭建的全过程:硬件检查、环境安装、项目结构梳理、第一个 Demo 运行,以及常见坑的填法。这套流程走通之后,你就拥有了一个可以反复实验的具身智能仿真平台。记住几个关键数字:16 维关节空间、200 步回合长度、MuJoCo 60fps 仿真频率——这些是后面训练调参的基础。下一篇,我们正式进入训练环节:用 OpenClaw 训练一个能稳定抓取物体的策略,从仿真到部署,完整走一遍。代码已经准备好了,你的 GPU 准备好了吗?
AI开源纪 — 解码前沿技术,连接开源世界。 关注我们,一起见证AI开源时代。
