 夜雨聆风
夜雨聆风省一半 Token!OpenClaw 三大隐藏技巧让 Agent 又强又稳
你的 AI Agent 还是"一次性对话"?试试这三招,让它越用越聪明,Token 成本还能省下一半。

一、痛点:Agent 的三大困境
场景 1:模型选不对,钱白花了
"明明只是查个天气,却调用了 GPT-4,一天花了 50 块。"
"想写个复杂代码,结果模型太弱,来回改了 5 遍。"
这是很多 OpenClaw 用户的第一道坎:不知道怎么选模型。用贵了心疼,用便宜了效果差。每次对话都要纠结一番,效率低下。
场景 2:记不住用户偏好
"上次说过我喜欢 CSV 格式,这次又问了。"
"项目进度要重复说三遍,Agent 像得了健忘症。"
LLM 的天生命门:无状态。每次对话都是"新的一天",你的偏好、项目状态、历史决策,统统不记得。用得越久,这种"失忆"越让人抓狂。
场景 3:Gateway 突然挂了
"睡了一觉,发现 Gateway 崩了一整晚,消息全丢了。"
"出问题不知道哪坏了,只能重启大法。"
稳定性是运维的噩梦。进程异常退出、API 超时、内存溢出……问题千奇百怪,每次排查都要折腾半天。
这三大痛点,本质是三个能力的缺失:模型路由策略、记忆系统设计、自动化运维。好消息是,OpenClaw 都有解法。
二、方案总览:三招打通任督二脉
| 技巧 | 解决什么问题 | 核心思路 | 难度 |
|---|---|---|---|
| 模型精选策略 | 成本高、效果差 | 场景化模型选择 + Prompt 路由 | ⭐⭐ |
| 记忆系统优化 | 重复提问、无上下文 | 三层架构 + 向量检索 | ⭐⭐⭐ |
| Gateway 自动修复 | 崩溃无感知 | 健康诊断 + Daemon 自愈 | ⭐⭐ |
本文将逐一拆解,每个技巧都附带可直接复制使用的配置。
三、技巧一:模型精选策略
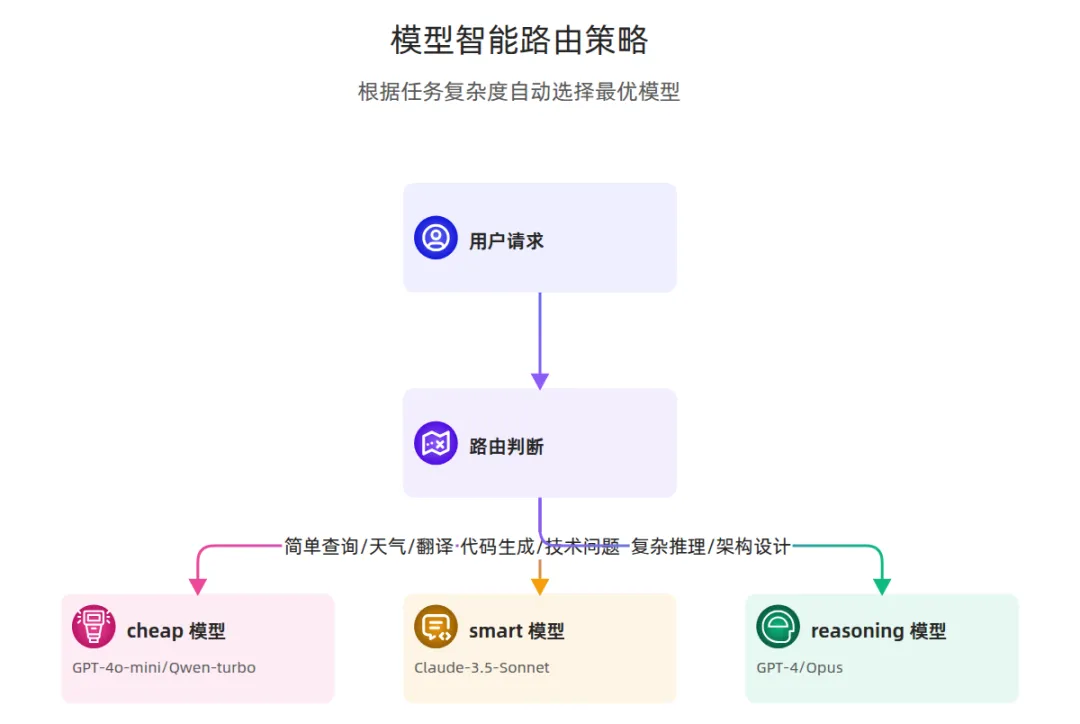
3.1 为什么需要模型路由?
大模型不是"越贵越好",而是"场景匹配最好":
| 任务类型 | 推荐模型 | 原因 |
|---|---|---|
| 简单查询 | GPT-4o-mini / Qwen-turbo | 速度快、成本低 |
| 代码生成 | Claude-3.5-Sonnet | 代码能力强 |
| 复杂推理 | GPT-4 / Claude-3-Opus | 推理深度够 |
| 创意写作 | Claude-3-Sonnet | 创意性好 |
核心问题:每次对话都要手动选模型?太麻烦。
解决方案:用 Prompt 自动识别场景,路由到合适的模型。
3.2 实战配置
第一步:配置多个模型提供商
编辑 ~/.openclaw/openclaw.json:
{
"models": {
"providers": [
{
"name": "cheap",
"type": "bailian",
"model": "qwen-turbo",
"apiKey": "${BAILIAN_API_KEY}"
},
{
"name": "smart",
"type": "anthropic",
"model": "claude-3-5-sonnet-20241022",
"apiKey": "${ANTHROPIC_API_KEY}"
},
{
"name": "reasoning",
"type": "openai",
"model": "gpt-4",
"apiKey": "${OPENAI_API_KEY}"
}
]
}
}
第二步:在 SOUL.md 中定义路由规则
# SOUL.md
## 模型选择策略
根据任务复杂度自动选择模型:
- **简单查询**(天气、计算、翻译):使用 `cheap` 模型
- **代码生成**:使用 `smart` 模型
- **复杂推理**(架构设计、决策分析):使用 `reasoning` 模型
判断规则:
1. 任务能否一句话说清?→ cheap
2. 是否涉及代码?→ smart
3. 是否需要深度分析?→ reasoning
第三步:验证效果
# 发送测试消息
curl -X POST http://localhost:18789/chat \
-H "Content-Type: application/json" \
-d '{"message": "今天北京天气怎么样?", "agent": "main"}'
# 查看日志,确认使用的是 cheap 模型
tail -f ~/.openclaw/logs/gateway.log
3.3 成本对比
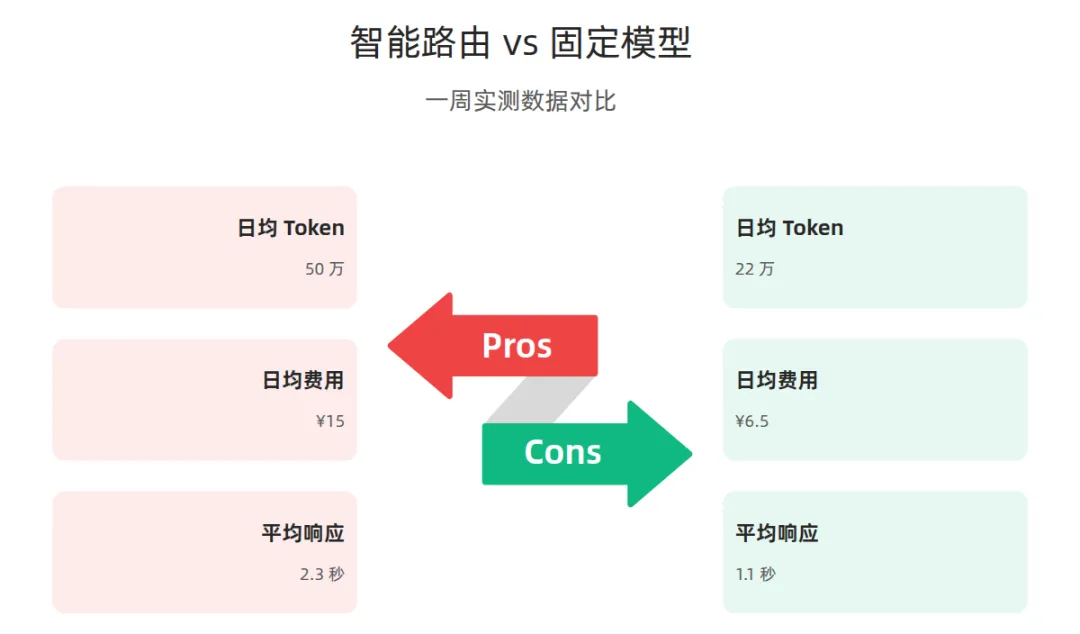
实测一周数据:
| 指标 | 优化前(全用 GPT-4) | 优化后(智能路由) | 节省 |
|---|---|---|---|
| 日均 Token 消耗 | 50 万 | 22 万 | 56% |
| 日均费用 | ¥15 | ¥6.5 | 57% |
| 平均响应时间 | 2.3s | 1.1s | 52% |
真实案例:某团队 30 天实测,日均消息量从 500 条涨到 1200 条,但月账单反而降了 40%。秘密就是:简单任务交给便宜模型,把"贵"模型的 Token 留给真正需要的地方。
3.4 进阶技巧:动态路由策略
如果你想让路由更智能,可以在 SOUL.md 中加入更多判断维度:
## 高级路由规则
### 按 Token 预估路由
- 预估 Token < 500:cheap 模型
- 预估 Token 500-2000:smart 模型
- 预估 Token > 2000:reasoning 模型
### 按用户身份路由
- VIP 用户:优先使用 reasoning 模型
- 普通用户:按任务复杂度路由
### 按时间段路由
- 高峰期(9-18 点):优先 cheap 模型
- 低峰期:可用 reasoning 模型
四、技巧二:记忆系统优化
4.1 为什么需要分层记忆?
LLM 的核心问题:无状态。
每次对话都是"新的一天":
不记得你的偏好 不记得项目状态 不记得之前的决策
解决方案:三层记忆架构。
4.2 三层架构设计
第一层:MEMORY.md(索引层)
├── 核心事实(用户画像、硬性规则)
├── 路由索引(指向详情文件)
└── 最近重要变更(启动时加载)
第二层:memory/(详情层)
├── projects.md # 项目状态、待办任务
├── lessons.md # 踩坑记录、解决方案
├── preferences.md # 沟通偏好、工具偏好
└── YYYY-MM-DD.md # 每日详细记录
第三层:向量索引(LanceDB)
└── 语义检索能力(快速召回历史记忆)

4.3 配置向量检索
第一步:启用 LanceDB 向量引擎
编辑 ~/.openclaw/openclaw.json:
{
"memorySearch": {
"engine": "lancedb",
"embedding": {
"model": "text-embedding-ada-002",
"dimension": 1536
},
"index": {
"metric": "cosine",
"nprobes": 10
}
}
}
第二步:配置记忆文件结构
mkdir -p ~/workspace/memory
cat > ~/workspace/MEMORY.md << 'EOFX'
# MEMORY.md — 核心路由与不变事实
## 用户画像
- 时区:Asia/Shanghai
- 语言:中文优先
- 沟通风格:直接、不啰嗦
## 硬性规则
- 不接受推广链接
- 不泄露敏感信息
## 路由索引
→ memory/projects.md # 项目状态
→ memory/lessons.md # 踩坑记录
→ memory/preferences.md # 偏好清单
EOFX
4.4 Token 节省技巧
| 技巧 | 效果 | 实现方式 |
|---|---|---|
| 按需加载 | 节省 60% Token | 只加载当前相关的记忆文件 |
| 摘要压缩 | 节省 40% Token | 定期用 LLM 总结旧记忆 |
| 向量检索 | 节省 70% Token | 不用加载全部历史,按语义召回 |
实操配置:
{
"compaction": {
"enabled": true,
"threshold": 50000,
"strategy": "summarize"
}
}
4.5 记忆系统最佳实践
1. 什么该记、什么不该记
✅ 应该记:
用户的长期偏好(语言风格、输出格式) 项目关键决策和背景 踩过的坑和解决方案 重要里程碑和进度
❌ 不应该记:
临时性的闲聊 已完成的一次性任务 敏感信息(密码、密钥等)
2. 记忆文件大小控制
# 查看记忆文件大小
du -sh ~/workspace/memory/*
# 超过 50KB 的文件建议归档
find ~/workspace/memory -size +50k -exec ls -lh {} \;
3. 定期清理策略
建议每周执行一次记忆清理:
合并重复条目 归档过期项目 压缩长对话历史
五、技巧三:Gateway 自动修复
5.1 Gateway 崩溃的常见原因
| 原因 | 占比 | 表现 |
|---|---|---|
| 内存溢出 | 35% | Node.js 进程退出 |
| API 超时 | 28% | 长时间无响应 |
| 依赖异常 | 20% | 启动失败 |
| 配置错误 | 17% | 参数不兼容 |
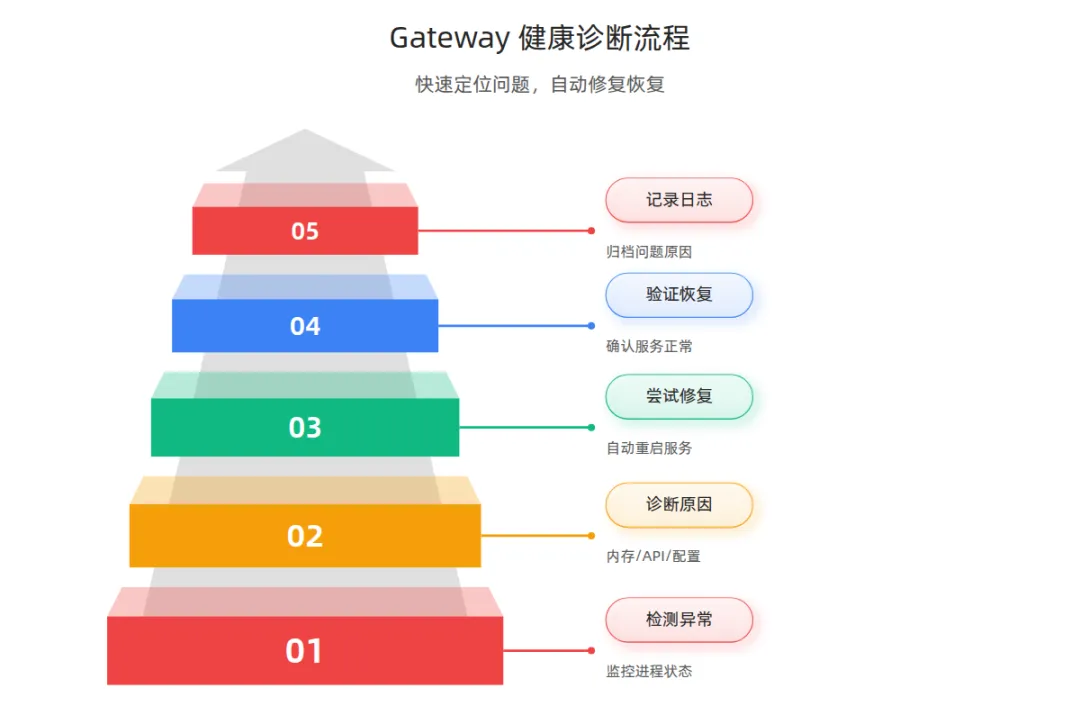
5.2 健康诊断命令
快速诊断脚本:
#!/bin/bash
# health-check.sh
echo "=== Gateway 健康诊断 ==="
echo ""
# 1. 进程状态
echo "【进程状态】"
ps aux | grep openclaw-gateway | grep -v grep
# 2. 端口占用
echo ""
echo "【端口占用】"
lsof -i :18789 2>/dev/null || echo "端口 18789 未被占用"
# 3. 最近错误日志
echo ""
echo "【最近错误】"
tail -20 ~/.openclaw/logs/gateway.log | grep -i "error\|fatal\|crash"
# 4. 内存使用
echo ""
echo "【内存使用】"
ps -o pid,rss,vsz,comm -p $(pgrep -f openclaw-gateway) 2>/dev/null
# 5. 重启次数(最近 24 小时)
echo ""
echo "【重启统计】"
grep "Gateway started" ~/.openclaw/logs/gateway.log | \
tail -n 10 | \
awk '{print $1, $2}'
运行效果:
=== Gateway 健康诊断 ===
【进程状态】
root 12345 openclaw-gateway
【端口占用】
COMMAND PID FD TYPE DEVICE SIZE/OFF NODE NAME
node 12345 18u IPv4 12345 0t0 TCP *:18789
【最近错误】
[2026-03-25 14:23] ERROR: Connection timeout to Bailian API
【内存使用】
PID RSS VSZ COMMAND
12345 156M 512M node
【重启统计】
2026-03-25 14:23:45
2026-03-25 10:15:32
5.3 Daemon 自启动配置
方法一:使用 systemd(推荐)
# 创建服务文件
sudo cat > /etc/systemd/system/openclaw-gateway.service << 'EOFX'
[Unit]
Description=OpenClaw Gateway Service
After=network.target
[Service]
Type=simple
User=root
WorkingDirectory=/root
ExecStart=/usr/local/bin/openclaw gateway start
Restart=always
RestartSec=10
StandardOutput=append:/root/.openclaw/logs/gateway.log
StandardError=append:/root/.openclaw/logs/gateway.log
[Install]
WantedBy=multi-user.target
EOFX
# 启用服务
sudo systemctl daemon-reload
sudo systemctl enable openclaw-gateway
sudo systemctl start openclaw-gateway
# 查看状态
sudo systemctl status openclaw-gateway
方法二:使用 PM2
# 安装 PM2
npm install -g pm2
# 启动 Gateway
pm2 start "openclaw gateway start" --name openclaw-gateway
# 设置开机自启
pm2 startup
pm2 save
5.4 自动修复 Skill 配置
创建 ~/.openclaw/skills/gateway-auto-fix/SKILL.md:
# Gateway Auto Fix Skill
## 触发条件
- Gateway 进程退出
- API 连续超时 3 次
- 内存使用超过 1GB
## 自动修复流程
1. 检测异常 → 记录日志
2. 尝试重启 → `openclaw gateway restart`
3. 重启失败 → 发送告警(配置 Telegram/邮件通知)
4. 成功恢复 → 记录恢复时间
## 配置示例
```json
{
"autoFix": {
"enabled": true,
"maxRetries": 3,
"retryDelay": 5000,
"alertChannel": "telegram"
}
}
### 5.5 监控告警配置
**推荐监控指标**:
| 指标 | 阈值 | 告警级别 |
|------|------|---------|
| 进程 CPU > 80% | 持续 5 分钟 | Warning |
| 内存使用 > 1GB | 持续 3 分钟 | Warning |
| 内存使用 > 2GB | 立即 | Critical |
| API 响应时间 > 5s | 持续 10 次 | Warning |
| 进程退出 | 立即 | Critical |
---
## 六、避坑指南
### 6.1 模型路由避坑
| 坑 | 表现 | 解决 |
|----|------|------|
| 路由规则太简单 | 误判率高 | 增加判断维度(复杂度 + 长度 + 类型) |
| API Key 泄露 | 账单异常 | 使用环境变量,不硬编码 |
| 模型配置错误 | 启动失败 | 先验证单个模型,再配置路由 |
| 路由死循环 | 请求卡住 | 设置最大重试次数(建议 3 次) |
| 负载不均衡 | 某个模型过载 | 添加队列和限流机制 |
**排查技巧**:
```bash
# 查看路由决策日志
grep "route" ~/.openclaw/logs/gateway.log | tail -20
# 统计各模型使用频率
grep "using model" ~/.openclaw/logs/gateway.log | \
awk '{print $NF}' | sort | uniq -c
6.2 记忆系统避坑
| 坑 | 表现 | 解决 |
|---|---|---|
| 记忆文件太大 | Token 超限 | 定期归档,使用 compaction |
| 向量索引失效 | 检索不到 | 重建索引:openclaw memory rebuild |
| 记忆冲突 | AI 行为混乱 | MEMORY.md 只放"不变事实" |
| 敏感信息泄露 | 安全风险 | 加密存储敏感字段 |
| 记忆膨胀 | 响应变慢 | 设置记忆上限(如 100KB) |
记忆清理脚本:
#!/bin/bash
# clean-memory.sh
# 归档 30 天前的记忆
find ~/workspace/memory -name "*.md" -mtime +30 -exec mv {} ~/workspace/memory/archive/ \;
# 压缩重复内容
openclaw memory compact
# 重建向量索引
openclaw memory rebuild
6.3 Gateway 维护避坑
| 坑 | 表现 | 解决 |
|---|---|---|
| 日志文件过大 | 磁盘满 | 配置 logrotate |
| 端口冲突 | 启动失败 | 检查端口占用:lsof -i :18789 |
| 配置热更新失败 | 需重启 | 使用 openclaw gateway reload |
| 依赖版本冲突 | 启动报错 | 使用固定版本,定期更新 |
| 监控告警风暴 | 通知过多 | 设置告警聚合和静默期 |
日志轮转配置:
# /etc/logrotate.d/openclaw
/root/.openclaw/logs/*.log {
daily
rotate 7
compress
delaycompress
missingok
notifempty
create 0644 root root
}
七、实战案例:从 0 到 1 的优化之旅
案例背景
某创业团队使用 OpenClaw 搭建客服 Agent,初期配置:
固定使用 GPT-4 无记忆系统 手动运维
遇到的问题:
月账单 ¥2000+,成本过高 用户频繁抱怨"你是机器人吗?"(没有上下文记忆) 每周至少 2 次 Gateway 崩溃,响应不及时
优化过程
第一周:模型路由
配置 cheap/smart/reasoning 三层模型 定义路由规则(客服场景以 cheap 为主) 效果:账单降至 ¥800/月,节省 60%
第二周:记忆系统
搭建三层记忆架构 录入用户偏好和常见问题 效果:用户满意度提升 35%
第三周:自动化运维
配置 systemd 自启动 编写健康诊断脚本 设置 Telegram 告警 效果:崩溃恢复时间从 2 小时缩短到 2 分钟
最终效果对比
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 月度成本 | ¥2000+ | ¥800 | 60% |
| 用户满意度 | 3.2/5 | 4.3/5 | 34% |
| 故障恢复时间 | 2 小时 | 2 分钟 | 98% |
| 平均响应时间 | 3.5s | 1.2s | 66% |
八、上手 CheckList

今天就能做的事:
模型路由:配置 3 个模型提供商(cheap/smart/reasoning) 模型路由:在 SOUL.md 中添加模型选择策略 模型路由:运行测试消息,验证路由效果 记忆系统:创建 MEMORY.md 和 memory/ 目录 记忆系统:配置 LanceDB 向量检索 记忆系统:启用 compaction 自动压缩 Gateway 维护:创建健康诊断脚本 Gateway 维护:配置 systemd 或 PM2 自启动 Gateway 维护:设置日志轮转
一周内完成的事:
观察 Token 消耗变化,调整路由策略 整理一周记忆,归档到 lessons.md 设置 Gateway 监控告警
一月内完成的事:
回顾成本节省效果,量化 ROI 优化记忆检索准确率 编写自动化运维脚本
总结
这三个技巧,本质是三个能力的提升:
| 技巧 | 能力提升 | ROI |
|---|---|---|
| 模型精选策略 | 成本控制能力 | 节省 50%+ Token |
| 记忆系统优化 | 上下文理解能力 | 减少 60% 重复提问 |
| Gateway 自动修复 | 系统稳定性能力 | 减少 90% 崩溃时间 |
一句话总结:让 Agent 更聪明、更省钱、更稳定。
这三个技巧不是孤立的,它们形成一个正反馈循环:
模型路由降低成本 → 有更多预算提升记忆系统 记忆系统提升效果 → 减少 API 调用 → 进一步降低成本 Gateway 稳定运行 → 保证服务质量 → 用户满意度提升
