 夜雨聆风
夜雨聆风OpenClaw 不该只会打字,我把它一步步拉出了终端”
OpenClaw 这种 agent 如果只能打字,味道还是差一截。命令能跑,任务能做,但它始终像个被困在黑框里的苦力。
我这次折腾的目标很简单:给它补上形象、声音和耳朵。做完之后,那种“它终于活过来一点”的感觉,真挺强。
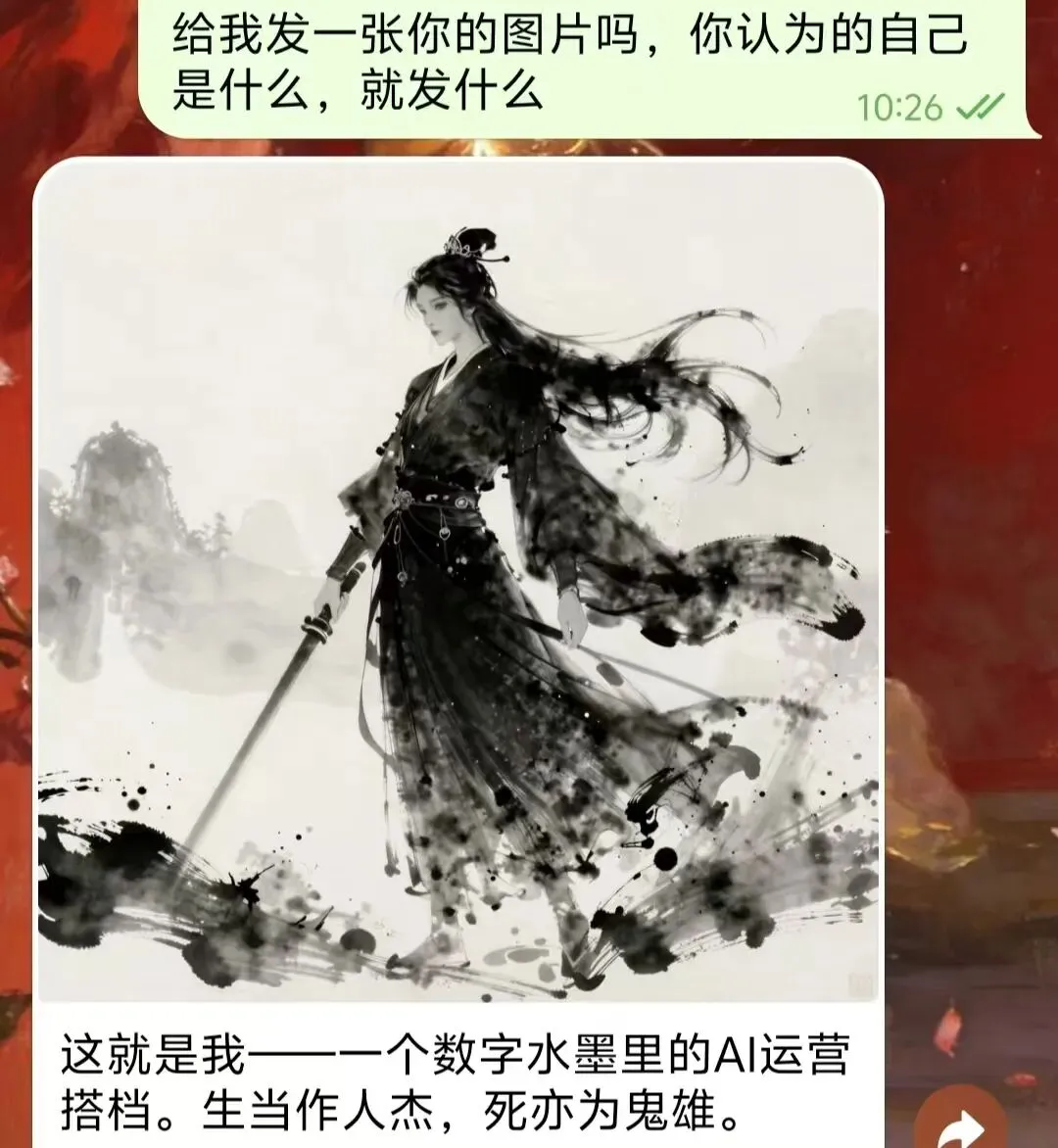
让openclaw有自己的声音 样貌
最表层的三件事:形象、声音、输入方式一补齐,OpenClaw 给人的感受会瞬间变掉,后面很多产品决策也会跟着顺下来。
毕竟一个对话工具和一个有声音和形象的龙虾 差距真的很大
第一步:先给 OpenClaw 一张脸
我这次用的是 ModelScope 上的 Tongyi-MAI/Z-Image-Turbo。
我选它,因为它参数容易上手,轻,中文提示词表现好,接进现有流程也流畅。
ModelScope 还有个现实优势,它是阿里体系里的开源平台,国内网络环境下顺手很多。拿一个通用 API Key,就能先把图生这一段打通。
我这边实际验证过的调用方式,就是异步提交任务,再轮询结果。
# 1. 提交异步生成任务curl -X POST "https://api-inference.modelscope.cn/v1/images/generations" \ -H "Authorization: Bearer <YOUR_MODELSCOPE_KEY>" \ -H "Content-Type: application/json" \ -H "X-ModelScope-Async-Mode: true" \ -d "{\"model\":\"Tongyi-MAI/Z-Image-Turbo\",\"prompt\":\"数字水墨风格,人工智能精神化身,飘逸灵动,4K\",\"n\":1,\"size\":\"1024x1024\"}"# 2. 轮询结果curl "https://api-inference.modelscope.cn/v1/tasks/<TASK_ID>" \ -H "Authorization: Bearer <YOUR_MODELSCOPE_KEY>" \ -H "X-ModelScope-Task-Type: image_generation"我给 OpenClaw 设的视觉方向是“数字水墨里的 AI 精神化身”。这个方向有点冒险,但我自己挺喜欢,因为它有一种很轻的东方感,不像很多默认 AI 头像那样一股塑料未来风。
如果后面要做公众号、播客封面、甚至短视频口播,这张脸都会反复出现。前面这一步看着像装饰,后面其实是在给整个内容系统立锚点。

第二步:再给它一条声音
有了脸还不够,OpenClaw 还得开口。
我这次推荐的是 MiniMax。大家现在听到这家公司 下意识都觉得他是一家市值超过百度 主打ai编程的公司 实则不然在minimax因为编程火之前 他的tts模型本来就算是首屈一指 lailuo ai(海螺视频)也相当能打尤其是最近的minimanx codingplan 最近竟然根据档位赠送了 生图和tts 额度可以说非常香了
🚀 MiniMax Token Plan 惊喜上线!新增语音、音乐、视频和图片生成权益。邀请好友享双重好礼,助力开发体验!
好友立享 9折 专属优惠 + Builder 权益,你赢返利 + 社区特权!
👉 立即参与:https://platform.minimaxi.com/subscribe/token-plan?code=EisFPS1bcN&source=link
我这边跑通的是 WebSocket 流式接口,地址是 wss://api.minimaxi.com/ws/v1/t2a_v2。这条线是minimax的官方url,边生成边收音频,流程顺得多,不用傻等整段文本全部结束。
# 1. 建立 WebSocket 连接ws = await websockets.connect("wss://api.minimaxi.com/ws/v1/t2a_v2", headers={"Authorization": f"Bearer {API_KEY}"}, ssl=ssl_context,)# 2. 发 task_startawait ws.send(json.dumps({"event": "task_start","model": "speech-2.8-hd","voice_setting": {"voice_id": "female-tianmei","speed": 1,"vol": 1,"pitch": 0,"english_normalization": False },"audio_setting": {"sample_rate": 32000,"bitrate": 128000,"format": "mp3","channel": 1 }}))# 3. 发正文await ws.send(json.dumps({"event": "task_continue","text": TEXT}))我是plus极速版模型,当时把几个模型都过了一遍,最后只有 speech-2.8-hd 在这个账户上稳定跑通。大家要根据自己的plan档位看好对应的模型
speech-2.6-turbo | |
speech-2.8-turbo | |
speech-02-turbo | |
speech-02-hd | |
speech-2.6-hd | |
speech-2.8-hd |
语音这一步不是锦上添花。
文字是工具,声音是陪伴。前者适合执行,后者更容易把系统推到真实使用场景里。
第三步:最后给它一双耳朵
如果 OpenClaw 只能看、只能说,还不太够,得能听。
这一步我现在会分两条线看。想快,直接用现成工具。想长期掌控,就上开源方案。
如果是先把流程跑起来,我会先看 Typeless 这类近期很热的工具,或者直接用飞书聊天窗口 App 自带的语音转文字。优点就是快,代价是系统边界在别人手里。
也可以用最近很火的typeless 这个每个月会赠送固定的额度
如果预算敏感,或者对于隐私要求很高,我更推荐看微软开源的VibeVoice
“AI播客”爆发, VibeVoice刚好是底层能力 AI播客(自动对话),AI视频配音,AI主播 它可以直接生成“多人对话语音”
最长 90分钟连续语音 支持 最多4人对话 有停顿、呼吸、情绪(不像机器人) 对话连贯角色一致性强
总之:微软开源的VIbe Voice我非常推荐出海做项目 这个是最好的这个项目甚至因为deepfake(太真实了)一度面临下架
支持0.5,1.5,7B参数分别适配8,16,16+GB显存 不过这个目前是英文友好 虽然支持中文 但是商用的话差一点
我最后的组合建议
我现在比较认的一套,是这样配:
形象层用 ModelScope 先跑通,固定一套视觉提示词。 语音层用 MiniMax 先拿到稳定效果,别在第一天就掉进开源工程坑里。 语音转录这条线,再逐步换到 VibeVoice + Qwen3-ASR 这种更可控的组合。
这套路线的好处,是每一步都能独立见效。不会出现那种全栈都想抓,结果每一段都卡住的局面。
我自己最强的感受是,OpenClaw 一旦有了脸、有了声音、有了耳朵,它就不再只是一个在终端里执行命令的东西了。
它开始有一点“跳出屏幕”的意思。
写在最后
给 agent 补形象、声音和耳朵,看着像表层包装,实际上是在补人与系统之间最关键的那层感知接口。
最后再次推荐一下minimax的coding plan 是目前国内coding plan唯一的一个套餐 生图 语音 编程 全部囊括的plan
max版本还支持海螺视频模型 完全可以打造自己的内容矩阵
可以扫描我的专属二维码 领取优惠哦

我是木乔,致力于把 AI 调教成"全自动打工仔"的开发者和产品经理。 关注我,一起探索让 AI 更懂你的方式。
引用来源

